《巨杉数据库》专题
-
从数据库+网络加载数据(Room+Retrofit+RxJava2)
我有一个示例API请求,它返回用户的WatchList列表。我想在用户加载watchlist屏幕时实现以下流程: 差异与 i.Same->一切都很好,因为数据已经显示给用户,什么都不做。 ii.Differs->将保存到本地存储,并将发送到下游。 到目前为止我做了什么? watchlist.kt localstore.kt(Android room) > 实现上述逻辑的最佳方法是什么? 我是否泄漏
-
基于Spring数据的多租户mongoDB数据库
我想让我的web应用程序使用mongodb和spring data multitenat。 基本上,我希望将所有实体(集合)复制到不同的数据库中。然后(基于一些规则,例如登录系统的用户),我想将一些实体实例(文档)存储到正确的数据库中。 例如,我有一个名为DBNameProviderService的服务。动态返回数据库名称的getDbName()。如何使用此服务动态选择正确的数据库? 编辑 抱歉,
-
无法从Android向Firebase数据库发布数据
我正在将Firebase用于我的Android平台聊天应用程序。我正在将此库用于Firebase数据库: 我按照这里的所有步骤来设置我的项目。我为Firebase数据库的< code>read和< code>write权限设置了< code>true。 我使用下面的代码将我的数据发送到Firebase数据库(单击按钮后,下面的代码块触发): 我的日志返回以下信息: 然后我检查了我的Firebase
-
如何从Room SQLite数据库中检索数据?
所以我根据YouTube上的教程创建了一个房间数据库。我有两个栏day and likes,每个栏都有int.目前,我已经用三行数据手动填充了数据库。 下面是手动填充数据库的代码: 在我的Dao类中,我当前有Insert、Update、deleteAll和getall...方法。这里是道: } 现在,我要从Room数据库中检索基于当天的数据。所以我想要第6天的likes数,它是1。我想检索数据并将
-
如何将Spark数据帧写入Neo4j数据库
null 非常感谢任何指向文档或非常基本的示例的指针。
-
将数据库表用作JMeter的CSV数据集
我目前正在使用JMeter为我公司的一个应用程序进行性能测试。该应用程序需要登录,我必须使用多个用户。这在JMeter中通常完成的方式似乎是通过CSV数据集,但是我可以访问数据库,并且可以直接从那里读取所有凭据。 因为这是一个测试环境,所有用户都有相同的密码,所以我可以硬编码,但我需要用户名列表。JMeter已经可以处理JDBC请求,但我想知道是否有任何方法可以将此类请求的结果用作数据集。 对我来
-
Spring数据Mongodb NoSuchMethodError写入数据库时出错
我正在使用mongodb构建一个SpringWebApp,但最近我开始在写DB时遇到问题。下面是我得到的堆栈跟踪。 阅读之后,最常见的原因似乎是依赖项不匹配,但我不确定在这种情况下,哪些依赖项实际上是相互兼容的。 波姆。xml 这些主要是最新的发布版本,尽管我将Spring框架更改为4.0.7。发布尝试并修复它,但我也使用了4.1.0。释放并发生相同的异常。 谢啦 EDIT:@Document注释
-
第六章 海量数据处理 - 6.10 数据库
方法介绍 当遇到大数据量的增删改查时,一般把数据装进数据库中,从而利用数据的设计实现方法,对海量数据的增删改查进行处理。
-
数据库 - dolphindb 批量数据写入去重复?
dolphindb 目前使用的 是 pool = ddb.DBConnectionPool("0.0.0.0", 8903, 20, "admin", "123456") appender = ddb.PartitionedTableAppender("dfs://dd", "dd", "instrument_id", pool) 多线程 线程池写入 问题是: 批量写入有重复 怎么去除重复呢 写入
-
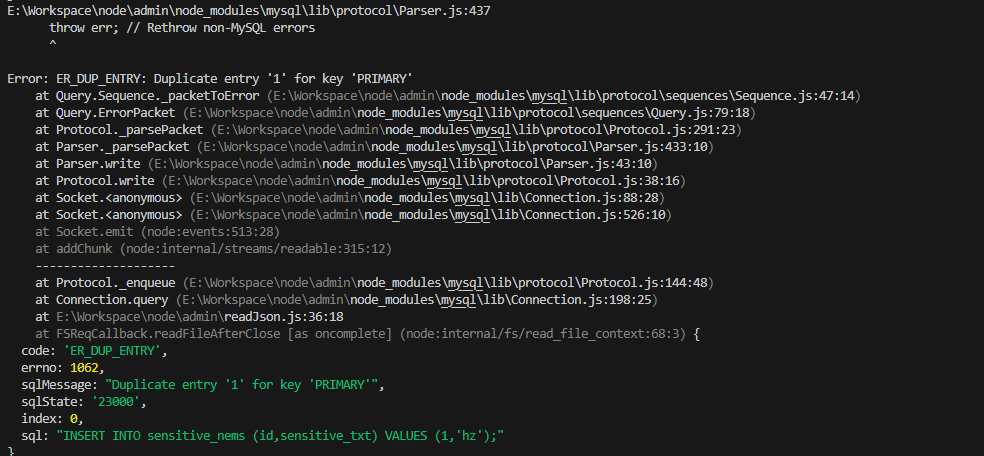 node.js - nodejs往数据库插入数据的问题?
node.js - nodejs往数据库插入数据的问题?拿到了一份敏感词的json文件,想通过nodejs循环插入数据库中 但是每次都会报错,不知道是怎么回事,有大佬帮忙看看呗 报错 设计的表
-
Java:读取巨大文件的最后n行
问题内容: 我想读取一个非常大的文件的最后n行,而不使用Java将整个文件读入任何缓冲区/内存区域。 我环顾了JDK API和Apache Commons I / O,但无法找到适合此目的的一个。 我在想UNIX中使用tail或更少的方式。我认为他们不会加载整个文件,然后显示文件的最后几行。在Java中也应该有类似的方法。 问题答案: 如果使用,则可以使用和到达文件末尾附近的特定点,然后从那里开始
-
Numpy内存错误创建巨大的矩阵
问题内容: 我正在使用numpy并尝试创建一个巨大的矩阵。这样做时,我收到内存错误 由于矩阵并不重要,因此我将向您展示如何轻松重现错误的方法。 毫不奇怪,这把我扔了 我想讲两件事: 我真的需要创建和使用一个大矩阵 我认为我有足够的RAM来处理此矩阵(我有24 Gb或RAM) 有没有一种简单的方法可以处理numpy中的大型矩阵? 为了安全起见,我之前阅读过这些帖子(听起来很相似): 使用Python
-
如何部分读取巨大的CSV文件?
问题内容: 我有一个很大的csv文件,因此无法将它们全部读入内存。我只想阅读和处理其中的几行内容。所以我正在Pandas中寻找一个可以处理此任务的函数,基本的python可以很好地处理此任务: 但是,如果我在熊猫中这样做,我总是会读第一行: 我正在寻找一些更简单的方法来处理熊猫中的这项任务。例如,如果我想读取1000到2000的行。如何快速执行此操作? 我想使用熊猫,因为我想将数据读入数据框。 问
-
使用VTD-XML解析巨大的XML文件
为了在巨大的xml文件中执行XPATH查询,我阅读了许多喜欢VTD-xml的文章,因此我复制了这些文章中的代码: 但当我运行它时没有结果,所以这意味着XML文件没有映射到内存中。。。我的问题是如何在VTD-xml中强制映射xml文件?
-
在巨大的事件流中发现差距?
问题内容: 我在PostgreSQL数据库中有大约一百万个具有以下格式的事件: 大约有50,000个唯一流。 我需要找到所有两个事件之间的时间间隔都超过特定时间段的所有事件。换句话说,我需要找到在特定时间段内没有事件的事件对。 例如: 在这种情况下,我想找到对(f,g),因为这些是紧挨着缺口的事件。 我不在乎查询是否慢,即在一百万条记录上花费一个小时左右就可以了。但是,数据集将保持增长,因此,如果