《差旅壹号》专题
-
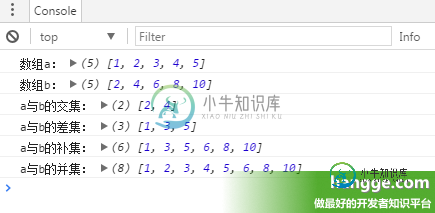 JS计算两个数组的交集、差集、并集、补集(多种实现方式)
JS计算两个数组的交集、差集、并集、补集(多种实现方式)本文向大家介绍JS计算两个数组的交集、差集、并集、补集(多种实现方式),包括了JS计算两个数组的交集、差集、并集、补集(多种实现方式)的使用技巧和注意事项,需要的朋友参考一下 方法一:最普遍的做法 使用 ES5 语法来实现虽然会麻烦些,但兼容性最好,不用考虑浏览器 JavaScript 版本。也不用引入其他第三方库。 1,直接使用 filter、concat 来计算 2,对 Array 进行扩展
-
如何在Java中获取两个日期时间数据之间的差异?[副本]
有2个数据如下。我将相互减去这些数据,并检查它们之间是否有 10 分钟的差异。如何在 java 中执行此操作?
-
基于对一列或多列进行分组来计算日期之间的差异
我的数据集示例如下: 我对这个数据集有两个问题: < li >我需要计算日期之间的差异,但此差异将基于“买方”和“id”分组来计算,这意味着,买方“Jenny”和Id“9”的日期差异将是一个组,Id为“4”的买方“Chang”将是另一个组,Id为“5”的买方“Chunfei”将是另一个组,Id为“8”的“Chunfei”将是另一个组。因此,输出将是: 问题是我不明白为什么group_by不起作用。
-
建筑梯度误差。对不起,我不能把错误放在这里看身体
我在网站“https://medium . com/discord-bots/making-a-basic-discord-bot-with-Java-834949008 c2b”上跟随一个教程我得到了错误接收方类com . github . jengel man . grad le . plugins . shadow . internal . dependency filecollection
-
如果有两个项目,要进行代码比较差异,你该如何操作?
本文向大家介绍如果有两个项目,要进行代码比较差异,你该如何操作?相关面试题,主要包含被问及如果有两个项目,要进行代码比较差异,你该如何操作?时的应答技巧和注意事项,需要的朋友参考一下 https://www.matools.com/compare 在线对比代码
-
简单的统计信息-用于计算均值,标准差等的Java程序包
问题内容: 您能否建议任何简单的Java统计信息包? 我不一定需要任何高级的东西。令我惊讶的是,似乎没有一个函数可以计算包装中的平均值… 你们用来做什么? 编辑 关于: 编写一个简单的类来计算均值和标准差有多难? 好吧,不难。我只在手工编码后才问这个问题。但这只是令我沮丧的是,在我需要这些最简单的功能时,他们没有手头可用。我不记得用心计算stdev的公式:) 问题答案: Apache Common
-
反应,使用扩展类创建组件和简单const =函数之间的差异
问题内容: 在反应教程中: https://egghead.io/lessons/javascript-redux-react-todo-list-example- filtering-todos 有主要组件创建与扩展: 而另一个组件就像一个包含函数的const一样创建: 我看到的区别是,首先使用class创建的函数使用了render函数,另一个则使用return函数将模板发回。 有什么区别?我听
-
 Python3显示当前时间、计算时间差及时间加减法示例代码
Python3显示当前时间、计算时间差及时间加减法示例代码本文向大家介绍Python3显示当前时间、计算时间差及时间加减法示例代码,包括了Python3显示当前时间、计算时间差及时间加减法示例代码的使用技巧和注意事项,需要的朋友参考一下 摘要 在使用Python写程序时,经常需要输出系统的当前时间以及计算两个时间之间的差值,或者将当前时间加减一定时间(天数、小时、分钟、秒)来得到新的时间,这篇文章就系统的对这些进行总结。码字不易,喜欢请点赞!!! 包 这
-
python根据eventType和eventId创建groupby,并获取每个eventType之间的日期差异
我的数据格式如下: 我需要以下任务的帮助: 我想按Id eventSource和eventType进行分组,并显示每个Id eventSource和eventType的和事件之间的差异,如下所示: 等等... 我被困在了群居舞台上, 谢谢你的帮助
-
在什么情况下,在神经网络中使用偏差可能没有好处?
我目前正在阅读迈克尔·尼尔森的电子书《神经网络与深度学习》,并运行了第1章末尾的代码,该代码训练神经网络识别手写数字(稍作修改,使反向传播算法基于小批量矩阵)。 然而,在运行此代码并实现略低于94%的分类准确率后,我决定从网络中删除偏见的使用。重新训练修改后的网络后,我发现分类准确率没有差异! NB:该网络的输出层包含10个神经元;如果这些神经元的第i个具有最高的激活率,则输入被归类为数字i。 这
-
给定一个整数数组,找到两个差最小且和为M的整数
给定一个无序整数列表,以这种方式打印两个总计为的整数(int 1小于或等于int 2,它们之间用空格隔开)。假设整数列表中总是有的解。int1和int2必须是正整数。 如果有多个解决方案,请打印差异最小的整数对。 例子: 这是我的代码,但是根据我们的编译器(这是我们班的一个练习),我对隐藏的测试用例有错误的输出。 更新:代码工作!
-
Weka中决策树和混淆矩阵中正确/错误分类实例的差异
我一直在使用Weka的J48决策树将RSS提要中的关键字频率分类为目标类别。我想我可能在协调生成的决策树与报告的正确分类的实例数以及混淆矩阵中的实例数方面存在问题。 例如,我的一个. arff文件包含以下数据摘录: 以此类推:总共有64个关键字(列)和570行,其中每一行都包含一天提要中关键字的频率。在这种情况下,10天内有57条feed,总共有570条记录需要分类。每个关键字都以代理项编号作为前
-
在sql中获取以月和日为单位的两个日期之间的差异
我需要得到两个日期之间的差异,比如说,如果差异是84天,我应该有2个月和14天的输出,我刚刚给出的代码给出了总数。这是密码 输出为: 例如,我需要这个查询的输出为2个月,最坏情况下为14天,否则我不介意是否可以得到月后的确切天数,因为这些天数实际上不是14天,因为所有月份都没有30天。
-
如何使用moment获得年、月和日的两个日期之间的差异。js
如何获得之间的差异2日期在年,月和天使用moment.js?例如之间的差异4/5/2014
-
如何在javascript两个日期之间的差异,当他们是不同的月份
我想知道不同月份或年份的两个日期之间的差异。我使用了下面的代码 var d1=最后执行日期。拆分(“.”); var d2=jabusinessdate.split ("."); var date1=新日期(d1[2],d1[1],d1[0]); var date2=新日期(d2[2],d2[1],d2[0]); VAR timeDiff=(date2.getTime()-date1.getTim