《亿联面试分享》专题
-
使用Apriori算法进行关联分析
关联分析 关联分析是一种在大规模数据集中寻找有趣关系的任务。 这些关系可以有两种形式: 频繁项集(frequent item sets): 经常出现在一块的物品的集合。 关联规则(associational rules): 暗示两种物品之间可能存在很强的关系。 相关术语 关联分析(关联规则学习): 从大规模数据集中寻找物品间的隐含关系被称作 关联分析(associati analysis) 或者
-
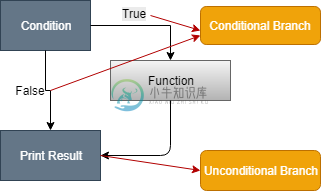 分支覆盖测试
分支覆盖测试主要内容:如何计算分支覆盖范围?分支覆盖技术用于覆盖控制流图的所有分支。它至少涵盖决策点的每个条件的所有可能结果(真和假)。分支覆盖技术是一种白盒测试技术,可确保每个决策点的每个分支都必须执行。 然而,分支覆盖技术和决策覆盖技术非常相似,但两者之间存在关键差异。决策覆盖技术涵盖每个决策点的所有分支,而分支测试涵盖代码的每个决策点的所有分支。 换句话说,分支覆盖遵循决策点和分支覆盖边缘。许多不同的指标可用于查找分支覆盖范围和决策覆
-
第5部分:测试
本教程上接教程第4部分。 我们已经建立一个网页投票应用,现在我们将为它创建一些自动化测试。 自动化测试简介 什么是自动化测试? 测试是检查你的代码是否正常运行的简单程序。 测试可以划分为不同的级别。 一些测试可能专注于小细节(某一个模型的方法是否会返回预期的值?), 其他的测试可能会检查软件的整体运行是否正常(用户在对网站进行了一系列的操作后,是否返回了正确的结果?)。这些其实和你早前在教程 1中
-
10.4. 测试与分支
case和select结构在技术上说不是循环,因为它们并不对可执行的代码块进行迭代.但是和循环相似的是,它们也依靠在代码块的顶部或底部的条件判断来决定程序的分支. 在代码块中控制程序分支 case (in) / esac 在shell中的case同C/C++中的switch结构是相同的.它允许通过判断来选择代码块中多条路径中的一条.它的作用和多个if/then/else语句相同,是它们的简化结构,
-
 得物数分笔试
得物数分笔试大题 1.sql执行顺序 2.海盗分金币五个海盗分得的金币为 21,20,19,22,18 因为每个人都足够聪明,所以最后两人再聪明都没用,无论怎么分,金币只能被没收。这个题有点博弈论的味道。
-
 美的数分笔试
美的数分笔试不总结的笔试面试等于白做,最近的教训 三类题 1,20单选。主要是hadoop组件基础知识 2,5不定项选择。也是大数据基础知识 3,三个sql(一个窗口函数,一个基础,一个分组拼接) 第二个sql用例过了,提交0
-
 微众商分笔试
微众商分笔试20道选择题,2道大题。 选择题覆盖:统计,sql,python,数字规律,数量关系。 大题:k均值算法原理阐述,数据分析师去分析某个项目增长10%的原因。
-
 百度面试|界面设计一面!愉快的面试经历!
百度面试|界面设计一面!愉快的面试经历!这是负责百度网盘的界面设计的岗位。整个面试过程真的很不错,小姐姐很nice!问了一下团队氛围,比较扁平化的,感觉都是年龄相仿的同事,沟通相处起来都比较和谐一点!面了那么多公司,大概的面试流程都差不多了! 这个岗位是偏UI视觉一点的,所以在面试中面试官也会问我想看一些偏视觉类的项目。 这个岗位的招聘流程是 一面 - 笔试 - 二面 - hr面 新鲜出炉专业面试的一些问题 希望以后可以派上用场! 整个
-
Spring引导千分尺分层度量命名空间级联
我有一个Spring Boot Java应用程序,正在向一个分层的Graphite度量系统发送度量。我在使用管理层。指标。出口石墨标记为前缀,并将主机和应用程序映射为前缀“我的指标”。然后,我有一个名称空间<代码>jvm的度量。记忆力已提交,但度量名称空间将作为主机进行连接。应用程序。JVMMORYCOMMITED* 。所以它代替了点(“.”)在metric名称空间中,并对名称空间的以下部分进行c
-
如何将1亿行加载到内存中
问题内容: 我需要将一个MySQL数据库中的1亿多行记录加载到内存中。我的Java程序失败, 因为我的机器中有8GB RAM,并且我的JVM选项中给出了-Xmx6144m。 这是我的代码 任何想法如何克服这个问题? 更新 我碰到了这篇文章 ,以及根据下面的评论更新了我的代码。看来我能够以相同的- Xmx6144m量将数据加载到内存中,但是需要很长时间。 这是我的代码。 要加载前100,000行,需
-
5亿个int找到它们的中位数?
本文向大家介绍5亿个int找到它们的中位数?相关面试题,主要包含被问及5亿个int找到它们的中位数?时的应答技巧和注意事项,需要的朋友参考一下 将2^32个数表示划分为2^16个区域,然后读取数据统计落在各个区域里的数的个数,之后就可以根据统计结果判断中位数落在哪个区域,同时知道这个区域中的第几大数刚好是中位数,然后第二次扫描只用统计这个区域中的那些数就可以
-
如何在ext4上存储十亿个文件?
问题内容: 我只创建了大约800万个文件,然后/ dev / sdb1中没有免费的索引节点。 有人说可以在格式化分区时指定索引节点数。 例如mkfs.ext4 -N 1000000000。 我尝试过但出现错误: “ inode_size(256)* inodes_count(1000000000)太大…指定更高的inode_ratio(-i)或更低的inode计数(-N)。”。 合适的inode_
-
拥有1亿个零的高效Python数组?
问题内容: 在Python中初始化和访问大数组元素的有效方法是什么? 我想在Python中创建一个数组,其中包含1亿个条目(无符号4字节整数),并初始化为零。我想要快速的数组访问,最好是连续内存。 奇怪的是,NumPy阵列的执行速度非常慢。我可以尝试其他替代方法吗? 有array.array模块,但我看不到有效分配1亿个条目的块的方法。 对评论的回应: 我不能使用稀疏数组。对于该算法来说太慢了,因
-
算法题 - 40亿个数中快速查找
40亿个数中快速查找 题目描述 给40亿个不重复的unsigned int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中? 分析与解法 海量数据处理往往会很有趣,有趣在什么地方呢? 空间,available的内存不够,需要反复交换内存 时间,速度太慢不行,毕竟那是海量数据 处理,数据是一次调用还是反复调用,因为针对时间和空间,通常来说,多次调用的话,势必会增加预处理以
-
 华为od面经分享
华为od面经分享双非一本,三年java开发,机试257,二面挂了,分享下整个过程给大家参考: 一、11月3号完成机试,两道简单都ac了,最后一题只通过一点: 第一道题目考查的是10进制转换其他进制 第二题是给一个数组,找出这个数组中的众数(众数可能不止一个),然后输出众数中的中位数 第三题题目是<数据单元的变量替换>,题目太长就不说了,感兴趣的可以自己搜索下 二、11月6日完成性格测试 三、11月10号完成HR面