《内存》专题
-
地图的可用内存[重复]
我有一个计划: clear()不执行任何操作。在内存监视器中,我看到内存使用量为184 Mb,清除后没有任何变化。为什么?如何清除地图的内存?
-
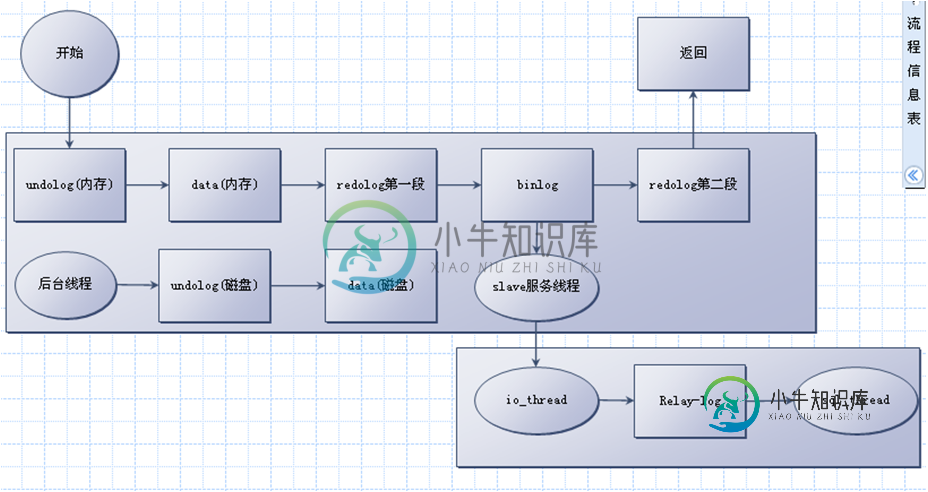 Mysql IO 内存方面的优化
Mysql IO 内存方面的优化本文向大家介绍Mysql IO 内存方面的优化,包括了Mysql IO 内存方面的优化的使用技巧和注意事项,需要的朋友参考一下 这里使用的是mysql Ver 14.14 Distrib 5.6.19, for Linux (i686) using EditLine wrapper 一、mysql目录文件 ibdata1:系统表空间 包含数据字典、回滚日志/undolog等 (insert buf
-
Spark内存/工作线程问题
5个节点各有4个内核和32GB内存,其中一个节点(节点4)有8个内核和32GB内存。 所以我总共有6个节点-28个核,192GB RAM。(我想使用一半的内存,但要使用所有的内核) 计划在集群上运行5个spark应用程序。 我的spark\u默认值。配置如下: 我想在每个节点上使用16GB max,并通过设置以下配置在每台机器上运行4个工作实例。所以,我希望(4个实例*6个节点=24个)集群上的工
-
WebApp2.4到2.5版本内存不足
null xmlns:xsi=“http://www.w3.org/2001/xmlschema-instance”xsi:schemalocation=“http://java.sun.com/xml/ns/javaeehttp://java.sun.com/xml/ns/javaee/web-app_2_5.xsd”> 谢谢, 斯特凡
-
Java中的内存映射文件
问题内容: 我一直在尝试编写一些非常快速的Java代码,这些代码必须执行很多I / O。我正在使用返回ByteBuffer的内存映射文件: 我遇到的问题是ByteBuffer .array()方法(应返回一个byte []数组)不适用于只读文件。我想编写我的代码,以便它可以与构造在内存中的内存缓冲区和从磁盘读取的缓冲区一起使用。但是我不想将所有缓冲区都包装为ByteBuffer.wrap()函数,
-
Java堆和堆栈内存分配
问题内容: 是局部变量,将其存储在堆或堆栈中的何处? 问题答案: 在堆上。每当您用来创建对象时,它都会在堆上分配。
-
Java中的类的内存分配?
问题内容: 类B继承了类A。现在,当我们创建类型B的对象时,为B分配的内存是多少?是否包括A和B或任何其他内存分配过程? 问题答案: 当创建对象B时,假设调用了默认构造函数 然后,JVM分配具有更多或更少内容的对象: 在B中显式声明的每个字段都有足够的内存(每个字段通常大约4-8字节,但是类型和主机系统之间有很大差异) 对于A及其祖先继承的每个最终字段,都有足够的内存 足够的内存来包含对调度向量的
-
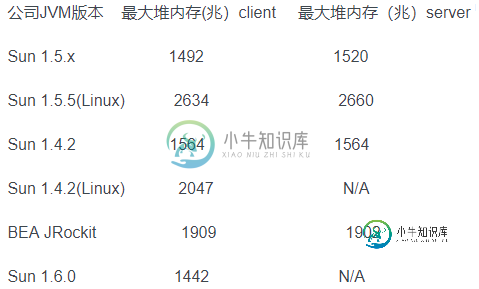 jvm最大内存限制多少?
jvm最大内存限制多少?本文向大家介绍jvm最大内存限制多少?相关面试题,主要包含被问及jvm最大内存限制多少?时的应答技巧和注意事项,需要的朋友参考一下 考察点:JVM (1)堆内存分配 JVM初始分配的内存由-Xms指定,默认是物理内存的1/64;JVM最大分配的内存由-Xmx指定,默认是物理内存的1/4。默认空余堆内存小 于40%时,JVM就会增大堆直到-Xmx的最大限制;空余堆内存大于70%时,JVM会减少堆直到
-
防止itertools.permutation中的内存错误
问题内容: 首先,我想提一下,我有一个3 GB的内存。 我正在研究一种在节点上时间呈指数形式的算法,因此在代码中已经有了 生成列表中所有顶点的组合,然后我可以处理其中一种排列。 但是,当我为40个顶点运行程序时,它给出了内存错误。 有没有一种更简单的实现方式可以通过它生成顶点的所有组合而不会出现此错误。 问题答案: 尝试使用由排列生成的迭代器,而不是用它重新创建一个列表: 通过这样做,python
-
cython.parallel.prange中的cython共享内存-块
问题内容: 我有一个函数,该函数将指向内存的指针作为参数,并写入和读取该内存: 我分配喜欢这样: 我的问题现在是:不同的线程如何处理呢?我的猜测是,指向的内存将由所有线程共享,并在函数内部“同时”读取或写入。然后,由于不能依赖先前设置的datavalue(在内),这会弄乱所有结果?我的猜测是正确的还是在cython编译器中实现了一些魔术安全带? 提前非常感谢您。 问题答案: 我假设没有线程的读或写
-
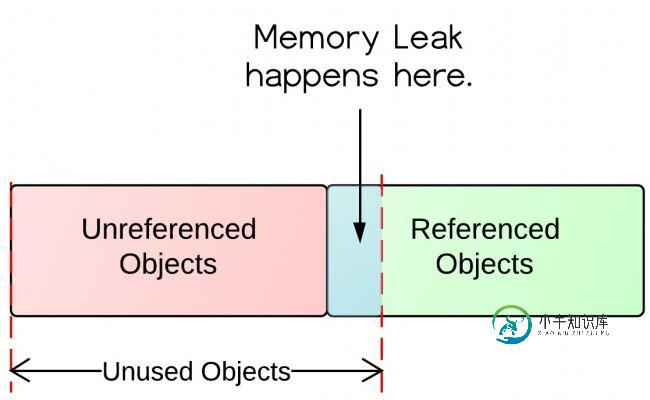 浅析Java中的内存泄漏
浅析Java中的内存泄漏本文向大家介绍浅析Java中的内存泄漏,包括了浅析Java中的内存泄漏的使用技巧和注意事项,需要的朋友参考一下 ava最明显的一个优势就是它的内存管理机制。你只需简单创建对象,java的垃圾回收机制负责分配和释放内存。然而情况并不像想像的那么简单,因为在Java应用中经常发生内存泄漏。 本教程演示了什么是内存泄漏,为什么会发生内存泄漏以及如何预防内存泄漏。 什么是内存泄漏? 定义:如果对象在应用中
-
MySQL全局共享内存介绍
本文向大家介绍MySQL全局共享内存介绍,包括了MySQL全局共享内存介绍的使用技巧和注意事项,需要的朋友参考一下 前言 全局共享内存则主要是 MySQL Instance(mysqld进程)以及底层存储引擎用来暂存各种全局运算及可共享的暂存信息,如存储查询缓存的 Query Cache,缓存连接线程的 Thread Cache,缓存表文件句柄信息的 Table Cache,缓存二进制日志的 Bi
-
处理器如何读取内存?
我正在尝试重新实现malloc,我需要理解对齐的目的。据我所知,如果内存对齐,代码将执行得更快,因为处理器不必采取额外步骤来恢复被剪切的内存位。我想我理解64位处理器读取64位逐64位内存。现在,让我们想象一下,我有一个有序的结构(没有填充):一个char、一个short、一个char和一个int。为什么short会错位?我们有区块中的所有数据!为什么地址必须是2的倍数。整数和其他类型的问题是一样
-
JVM内存段和JIT编译器
我知道这依赖于JVM,每个虚拟机都会选择实现它,但我想了解总体概念。 据说对于JVM用来执行Java程序的内存段 Java堆栈 不一定用连续内存实现,并且可能都实际分配在操作系统提供的一些堆内存上,这就引出了我的问题。 完全使用JIT机制并将字节码方法编译为本机机器码方法的JVM将这些方法存储在某个地方,那会在哪里?执行引擎(通常用C/C编写)将不得不调用这些JIT编译函数,然而内核不应该允许程序
-
Tarantool应用程序内存限制
日安,我是tarantool的新手,我有一个关于tarantool内部客户端应用程序内存限制的问题,我有3亿个项目的内存数据库和选择其中一部分的lua应用程序,在选择我将结果包装为“类”后,从代码中进行更简单的交互。例如: 使用方法: 在大多数情况下,它在第一次运行时运行成功,但在第二次运行时,它以100%的概率失败,并显示消息(tarantool消息): 我知道,内存使用(非释放内存)存在问题,