《内存》专题
-
了解JVM内存分配和Java内存不足:堆空间
我想真正了解内存分配在JVM中是如何工作的。我正在编写一个内存不足的应用程序:堆空间异常。 我知道我可以传入VM参数,如Xms和Xmx,以增加JVM为正在运行的进程分配的堆空间。这是一个可能的解决方案,或者我可以检查我的代码内存泄漏并修复那里的问题。 我的问题是: 1)JVM实际上如何为自己分配内存?这与OS如何将可用内存传递给JVM有什么关系?或者更一般地说,为任何进程分配内存实际上是如何工作的
-
内存使用差异:cgroup Memory.usage_in_bytes与docker容器内部的RSS
“Kubernetes”(v1.10.2)说我的pod(包含一个容器)使用了大约5GB的内存。在容器内部,RSS更像是681MIB。anypony能否解释如何使用以下数据从681MIB到5GB(或者描述如何使用我省略的另一个命令来弥补差异,或者来自容器,或者来自在kubernetes中运行该容器的docker主机)? kubectl top pods显示为5GB: Cadvisor报告了一个相似的
-
第7章 OpenCL设备端内存模型 - 7.5 私有内存
私有内存指的是各工作项内自己所使用的变量,也包括内核参数。原则上,私有数据通常放置到寄存器上,不过寄存器的资源并不是那么多,当使用的私有内存过多时,一部分数据将会放置到全局内存中。私有内存的分配会影响内核所使用到的寄存器数量。与局部内存一样,指定的架构中所分配的寄存器数量是固定的。而且,不同架构之间的性能差异也很大。 x86类型的CPU所具有的寄存器数量相当少。不过,因为其缓存较大,一些需要将寄存
-
第7章 OpenCL设备端内存模型 - 7.4 局部内存
OpenCL也支持一些架构的子集,包括多GPU和Cell带宽引擎,用于处理小暂存式缓存数组在主DRAM和基础缓存上的分布。局部内存与全局内存没有交集,访问两种内存所使用的是不同的操作。基于这种架构,不同内存之间就需要进行数据传输(使用async_work_group_copy()进行拷贝会更高效),或者直接内存间的拷贝。局部内存也同样支持CPU实现,不过在CPU端局部内存就存放在标准可缓存内存中。
-
第7章 OpenCL设备端内存模型 - 7.3 常量内存
常量内存使用__constant标识进行描述,常量内存作为全局地址空间的一部分,在运行时可以分配出出相应的缓存空间,利用常量内存可以提高应用访存效率。使用常量地址空间的方式有两种: 可以通过数组创建的方式,之后将数组作为参数传入内核中。内核参数描述上,必须指定__constant为对应指针的标识符。 内核端声明常量对象,并使用__constant标识对其进行初始化,其属于编译时常量类型。 不同架构
-
第7章 OpenCL设备端内存模型 - 7.2 全局内存
OpenCL C中使用类型修饰符__global(或global)描述的指针就是全局内存。全局内存的数据可以被执行内核中的所有工作项(比如:设备中的计算单元)所访问到。不同类型的内存对象的作用域是不同的。下面的小节中,将详细讨论每种全局内存对象。 7.2.1 数组 __global可以用来描述一个全局数组。数组中可以存放任意类型的数据:标量、矢量或自定义类型。无论数组中存放着什么类型的数据,其是通
-
第6章 OpenCL主机端内存模型 - 6.2 内存管理
使用OpenCL主机端API创建内存对象,这些内存对象都在全局空间内分配,可以被上下文上中所有的设备使用。虽然,OpenCL中只设置了一块全局内存,不过实际使用的很多异构系统中具有很多设备,这些设备对共享地址空间有严格的要求,并且可能不同设备的内存在物理设备上是分开的——比如CPU的内存和离散GPU的内存。这样的话,在内核运行前,运行时可能就要将数据在各种设备的内存间进行拷贝。即使在共享内存系统中
-
第6章 OpenCL主机端内存模型 - 6.1 内存对象
OpenCL定义了三种内存对象——数组,图像和管道——这几种内存对象可以通过主机端的API进行创建。数组和图像内存对象上存储的数据,可以在主机端和设备端进行随机访问。管道对象上的数据对象只能在内核端先进先出(FIFO),并且主机端无法访问这些数据。 数组对象可以看做为CPU上的一维数组,并且其分配过程与C的malloc()函数类似。数组对象可以包含任何标量数据,向量数据或自定义结构体。数据在数组中
-
ng-repeat内的AngularJS内联编辑
问题内容: 我正在与AngularJS一起显示应用程序键(应用程序标识符)表,我想使用编辑按钮在该表行中显示一个小表格。然后用户可以编辑字段并单击“保存”或“取消” 演示:http://jsfiddle.net/Thw8n/ 我的内联表单效果很好。我单击编辑,然后出现一个表格。取消也很棒。 我的问题是 如何连接保存按钮和将对API进行$ http调用的函数 如何从该行获取数据以发送到$ http调
-
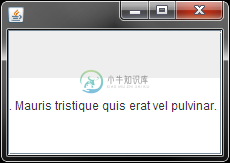 JScrollPane内部的JPanel内部的JTextComponent
JScrollPane内部的JPanel内部的JTextComponent我最近需要在一个JScrollPane的viewport视图中放置几个组件,其中包括一个JTextPane。 我将所有组件(两个JPanel和JTextPane)放在另一个JPanel中,这个JPanel有一个BorderLayout LayoutManager,并将该JPanel设置为ScrollPane的viewport视图。 我立即注意到: JTextPane不再根据JScrollPane的
-
内容模块 - 内容库操作
获取内容库详情 接口 GET https://cloud.minapp.com/userve/v1/content/:content_group_id/ 其中 content_group_id 是内容库的 ID 代码示例 var axios = require('axios').create({ withCredentials: true }) axios.get('https://cloud
-
内容模块 - 内容库操作
获取内容库详情 接口 GET https://cloud.minapp.com/oserve/v1/content/:content_group_id/ 其中 content_group_id 是内容库的 ID 代码示例 {% tabs getContentGroupCurl=”Curl”, getContentGroupNode=”Node”, getContentGroupPHP=”PHP”
-
选择Redis最大内存大小和BGSAVE内存使用情况
问题内容: 我试图找出在以下情况下“ maxmemory”的安全设置: 大量写入的应用程序 8GB RAM 假设其他进程占用约1GB 这意味着redis进程的内存使用量不得超过7GB 每个BGSAVE事件的内存使用量都会增加一倍,原因是: 在redis 文档中,有关BGSAVE事件的内存使用量增加的说法如下: 如果要在写入量很大的应用程序中使用Redis,则在将RDB文件保存在磁盘上或重写AOF日
-
关于内存,Java Runtime.exec()从哪个Linux内核/ libc版本安全?
问题内容: 在工作中,我们的目标平台之一是运行Linux的资源受限小型服务器(内核2.6.13,基于旧的Fedora Core的自定义发行版)。该应用程序是用Java(Sun JDK 1.6_04)编写的。Linux OOM杀手配置为在内存使用量超过160MB时杀死进程。即使在高负载下,我们的应用程序也永远不会超过120MB,并且与其他活动的本机进程一起,我们也始终保持在OOM限制内。 但是,事实
-
IPC共享内存和线程内存之间的性能差异
问题内容: 我经常听到与访问线程之间的进程内存相比,访问进程之间的共享内存段不会降低性能。换句话说,多线程应用程序不会比使用共享内存的一组进程更快(不包括锁定或其他同步问题)。 但我有疑问: 1)shmat()将本地进程虚拟内存映射到共享段。必须为每个共享内存地址执行此转换,并且转换可能会花费大量成本。在多线程应用程序中,不需要额外的转换:所有VM地址都转换为物理地址,就像在不访问共享内存的常规过