《石化盈科》专题
-
 Maven自动化构建
Maven自动化构建主要内容:使用 maven-invoker-plugin 插件Maven 自动化构建是一种方案,即当某个项目构建完成后(特别是有代码更新的情况下),所有依赖它的相关项目也应该开始构建过程,以确保这些项目的稳定运行。 Maven 的自动化构建主要通过如下两种方案实现: 使用 maven-invoker-plugin 插件。 使用持续集成(CI)服务器自动管理构建自动化,例如 Jenkins (了解即可)。 使用 maven-invoker-plugin 插件
-
 Code::Blocks汉化教程
Code::Blocks汉化教程主要内容:下载CodeBlocks汉化包,汉化CodeBlocks,更改CodeBlocks设置由于官方下载的 CodeBlocks 全部都是英文版,本教程中给大家推荐的 CodeBlocks 17.12 版本也是官方英文版,所以本节给大家介绍: 如何将英文版设置为简体中文版。 下载CodeBlocks汉化包 首先,大家需要下载一个 CodeBlocks 汉化包,下载地址为: 百度网盘: 链接: https://pan.baidu.com/s/1sniGc01 密码: 7e9m 提示:汉化包
-
Java日期格式化
主要内容:DateFormat 类,SimpleDateFormat 类格式化日期表示将日期/时间格式转换为预先定义的日期/时间格式。例如将日期“Fri May 18 15:46:24 CST2016” 格式转换为 “2016-5-18 15:46:24 星期五”的格式。 在 Java 中,可以使用 DateFormat 类和 SimpleDateFormat 类来格式化日期,下面详细介绍这两个格式化日期类的使用。 DateFormat 类 DateFormat 是日
-
Java数字格式化
数字的格式在解决实际问题时使用非常普遍,这时可以使用 DedmalFormat 类对结果进行格式化处理。例如,将小数位统一成 2 位,不足 2 位的以 0 补齐。 DecimalFormat 是 NumberFormat 的一个子类,用于格式化十进制数字。DecimalFormat 类包含一个模式和一组符号,常用符号的说明如表 1 所示。 表 1 DecimalFormat 支持的特殊字符 符号
-
实施迭代深化
为了通过Alpha-Beta剪枝提高最小极大算法的性能,我实现了迭代深化: 其中方法<code>iterativeDeepening</code>只返回最佳移动的id。 首先,我不确定这是否是实现迭代深化的正确方法。 其次,我注意到AI开始做错误的动作。迭代深化有可能影响决策吗? 在使用转置表和迭代深化时,我衡量了算法速度的显著提高,但我真的不想为了速度而牺牲AI质量。
-
格式化HTML?[副本]
提前感谢你的帮助。
-
graphql解析器优化
如果我有模式: 和一个解析器: 和两个可能的查询。问题#1: 和查询#2: 是否可以优化冲突解决程序,使查询#1 readAllPosts仅从数据库中提取标题,而查询#2则同时提取标题和lotsofdata? 我查看了parent、args、context和info参数,但看不到任何指示解析器是否被调用以响应像#1或#2这样的查询的内容。
-
无法初始化OneDS
我有一个使用MIP SDK的Azure函数,当调用< code>MIP时,我得到以下错误。CreateMipContext(...): 令人惊讶的是,该错误仅在 Azure 上运行时发生。在本地运行时,一切都很好。 我正在使用MIP SDK v1.8.86和.NET Core 3.1。 知道OneDS是什么或者是什么导致了错误吗?
-
优化排序依据
我正在尝试优化这个查询,该查询通过字段(第1个)和字段(第2个)对进行排序。没有第一个字段查询需要大约0.250秒,但有了它需要大约2.500秒(意味着慢了10倍,可怕)。有什么建议吗? 注意: -使用InnoDB(MySQL 5.7.19) -主要是表上的 -字段同时被索引和 解释结果: 更新^^ 信誉规定:一个帖子,多少(n=信誉)天可以显示在列表的顶部。 实际上,我试图给一些帖子的声誉,可以
-
无法实例化SpatialIntegrator
我试图使用Postgis 2.2和Postgreql 9.5与JPA,Postgis 9.5方言。我已经在pom.xml的要求,按这里http://www.hibernatespatial.org/documentation/documentation/和类型导入正确,但是当我试图运行程序使用几何类型我得到这个错误: 我显然遗漏了一些配置,有人能指出是什么吗?
-
 TestNG参数化测试
TestNG参数化测试主要内容:1. 使用XML传递参数,2. 通过@DataProvider传递参数,3. @DataProvider + 方法,4. @DataProvider + ITestContextTestNG中的另一个有趣的功能是参数化测试。 在大多数情况下,您会遇到业务逻辑需要大量测试的场景。 参数化测试允许开发人员使用不同的值一次又一次地运行相同的测试。 TestNG可以通过两种不同的方式将参数直接传递给测试方法: 使用 使用数据提供者 在本教程中,我们将向您展示如何通过XML 或将参数传递给方法。
-
OrientDB优化数据库
根据技术术语,优化表示“在最快的时间内实现更好的性能”。 参照数据库,优化涉及最大化检索数据的速度和效率。 OrientDB支持轻量级边缘,这意味着数据实体之间的直接关系。 简而言之,它是一个字段到字段的关系。 OrientDB提供了不同的方法来优化数据库。 它支持将常规边转换为轻量级边缘。 以下语句是数据库命令的基本语法。 将常规边转换为轻量级边,而禁用输出。 示例 在这个例子中,我们将使用在前
-
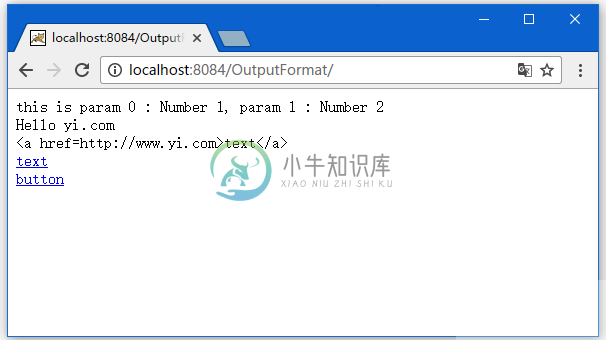 JSF输出格式化
JSF输出格式化主要内容:实例,运行实例标签呈现HTML文本,但可以接受参数化输入。 以下JSF代码 - 被渲染成以下HTML代码 - 实例 打开NetBean8.2,创建一个名称为:OutputFormat 的JavaWeb JSF工程。以下是文件:UserBean.java中的代码 - 以下是文件:index.xhtml中的代码 - 运行实例 Tomcat启动完成后,在浏览器地址栏中输入以下URL。 得到结果如下图所示 -
-
Java国际化(i18n)UTC
主要内容:时区转换,可用时区UTC代表协调世界时。 这是时间标准,并在全世界普遍使用。 所有时区的计算都与UTC的时差相当。 例如,丹麦哥本哈根的时间是表示UTC时间加上一个小时。用于在数据库中存储日期和时间。 时区转换 以下示例将展示各种时区的转换。 我们将以毫秒为单位打印一天中的小时和时间。 第一次将会有所不同,第二次将保持不变。 文件:IOTester.java - 执行上面示例代码,得到以下结果 - 可用时区 以下示
-
Gson序列化示例
主要内容:1. 数组,2. 集合,3. 泛型在本章中,我们将讨论和学习如何使用数组,集合和泛型的序列化/反序列化。 1. 数组 示例 我们来看看数组的序列化/反序列化。 创建一个名为的Java类文件:GsonTester.java - 执行上面示例代码,得到以下结果 - 2. 集合 让我们看看集合()序列化/反序列化的实际操作。 创建一个名为的Java类文件: GsonTester.java - 执行上面示例代码,得到以下结果 - 3. 泛