《分析》专题
-
解析C#中的分部类和分部方法
本文向大家介绍解析C#中的分部类和分部方法,包括了解析C#中的分部类和分部方法的使用技巧和注意事项,需要的朋友参考一下 可以将类或结构、接口或方法的定义拆分到两个或多个源文件中。每个源文件包含类型或方法定义的一部分,编译应用程序时将把所有部分组合起来。 分部类 在以下几种情况下需要拆分类定义: 处理大型项目时,使一个类分布于多个独立文件中可以让多位程序员同时对该类进行处理。 使用自动生成的源时,无
-
 Hibernate框架数据分页技术实例分析
Hibernate框架数据分页技术实例分析本文向大家介绍Hibernate框架数据分页技术实例分析,包括了Hibernate框架数据分页技术实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Hibernate框架数据分页技术。分享给大家供大家参考,具体如下: 1.数据分页机制基本思想: (1)确定记录跨度,即确定每页显示的记录条数,可根据实际情况而定。 (2)获取记录总数,即获取要显示在页面中的总记录数,其目的是根据该数来确
-
如何从谷歌分析转移到Firebase分析?
最近几个月,谷歌发布了一个新的分析替代方案,称为“Firebase Analytics”。 由于该应用程序已经有谷歌分析,我发现一些障碍,我不知道如何最好地处理。 > 以前,“newTracker”函数需要一个属性ID。现在我没有看到它。这是否意味着它不需要一个? 以前,“enableAdvertisingIdCollection”也可以用来收集广告信息。在新的API里找不到。是自动收藏的吗? “
-
基于文本分类的Stanford CoreNLP情感分析
但是,我还没能在Stanford CorenLP中找到任何文本分类的注释器。我有什么办法可以实现我的想法。更好的是,有没有更好的方法来实现我想要实现的目标。 提前谢了。
-
Google Analytics(分析)跟踪中的分析接收器
在Google Analytics(分析)跟踪Ver1中,它具有类。 但当我使用Google Analytics Tracking Ver2时,它没有类。我不知道我应该用哪门课来代替。 在使用Google Analytics跟踪时声明的清单中: 你能帮帮我吗。
-
 得物L【95分】商业分析师面试0221~
得物L【95分】商业分析师面试0221~今年第三家面试公司是得物旗下的95分商业分析师。现在看录音回放,感觉当时的回答好糟糕啊!!! 面试得物的是一个超级无敌温柔的商业分析师。感觉就像是小姐姐一样亲切一直引导你,但我还是经验尚浅。准备的不够充分吧。 开头一贯都是先让做自我介绍。 然后接下来就问我目前所在位置+实习能够实习多久之类的问题。 接下来就是扔给我之前HR发我的两道题,一道是有关费米估算问题的求解,另一道是SQL题。 费米估算问题
-
六、监督学习第二部分:回归分析
在回归中,我们试图预测连续输出变量 - 而不是我们在之前的分类示例中预测的标称变量。 让我们从一个简单的玩具示例开始,其中包含一个特征维度(解释性变量)和一个目标变量。 我们将使用一些噪声从正弦曲线创建数据集: x = np.linspace(-3, 3, 100) print(x) rng = np.random.RandomState(42) y = np.sin(4 * x) + x +
-
句子分类(分类)
问题内容: 我一直在阅读有关文本分类的文章,并找到了几种可用于分类的Java工具,但我仍然想知道:文本分类与句子分类一样! 有没有专门针对句子分类的工具? 问题答案: “文本分类”和“句子分类”之间没有形式上的区别。毕竟,句子是一种文本。但是总的来说,当人们谈论文本分类时,恕我直言,他们指的是更大的文本单元,例如文章,评论或演讲。将政治人物的讲话归类为民主人士或共和党人比对推文进行分类要容易得多。
-
7 分页和分段
分页: 用户程序的地址空间被划分成若干固定大小的区域,称为“页”,相应地,内存空间分成若干个物理块,页和块的大小相等。可将用户程序的任一页放在内存的任一块中,实现了离散分配。 分段: 将用户程序地址空间分成若干个大小不等的段,每段可以定义一组相对完整的逻辑信息。存储分配时,以段为单位,段与段在内存中可以不相邻接,也实现了离散分配。 分页与分段的主要区别 页是信息的物理单位,分页是为了实现非连续分配
-
html分区与分区
我正在制作一个web组件,一个导航栏(或navbar)。里面有四个部分,标志,菜单,切换器,和额外。 问题是,我应该对每个部分使用 还是 ? 还是有更合适的元素类型? 插图是这样的: 匿名用户 这是一个很棒的问题,并且与语义HTML相关。根据MDN,当没有其他标记真正相关或合适时,我们应该使用section标记。如果意图是一个实际的节,那么它还应该包括一个节头。 HTML 元素表示文档的一个通用的
-
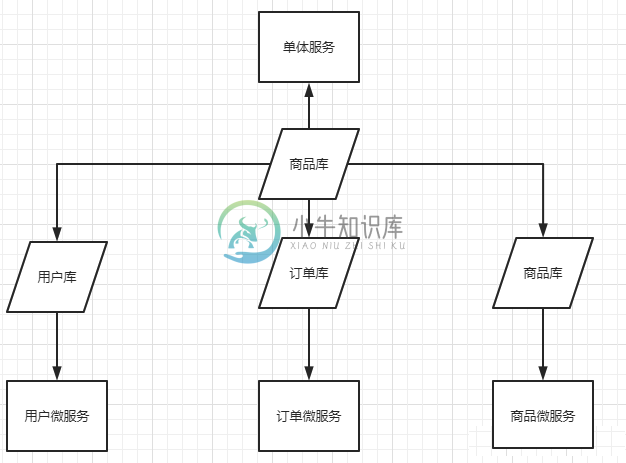 分库分表-入门
分库分表-入门主要内容:1.数据库瓶颈,2.垂直切分,3.水平切分,4.数据分片规则,5.分库分表带来的问题1.数据库瓶颈 不管是IO瓶颈,还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载活跃连接数的阈值。在业务Service来看就是,可用数据库连接少甚至无连接可用。 (并发量、吞吐量、崩溃)。 1.1 IO瓶颈 第一种:磁盘读IO瓶颈,热点数据太多,数据库缓存放不下,每次查询时会产生大量的IO,降低查询速度 -> 分库和垂直分表。 第二种:网络IO瓶颈,请求的数据太多,
-
分析gc日志
问题内容: 我正在使用和选项打开gc日志记录。 但是发现只有在4 0r 5后才通过命令打印我的gc日志的实际详细信息! 按照定义,将为每个gc打印应用程序停止时间。 但是我不清楚为什么它会打印如下所示的示例。 是因为 只需在每个安全点到达后打印 (要么) 该日志文件将由其他gc线程记录。我正在使用并发扫描进行完整GC,并为年轻一代使用ParNew 我的应用程序是Web应用程序。 O / p模式-我
-
JavaScript YAML分析器
问题内容: 我正在寻找一个JavaScriptYAML解析器,它将YAML转换为HTML页面中可用的东西。我已经在Github上尝试过此版本,但它似乎只能与node.js一起使用 我应该使用哪些库?是否有示例代码可以显示示例用法? 问题答案: JS-YAML解析器可在浏览器中使用。虽然,它的主要目标是node.js,但浏览器版本只是为了好玩而已
-
 边界值分析
边界值分析边界值分析是广泛使用的黑盒测试用例设计技术之一。它用于测试边界值,因为边界附近的输入值具有较高的误差机会。 每当我们通过边界值分析进行测试时,测试人员会在输入边界值时关注软件是否产生正确的输出。 边界值是包含变量上限和下限的值。假设是任何函数的变量,其最小值为,最大值为,和都将被视为边界值。 边界值分析的基本假设是,使用边界值创建的测试用例最有可能导致错误。 和是边界值,所以测试人员更关注这些值,
-
MongoDB查询分析
主要内容:$explain,$hint查询分析是衡量数据库和索引设计有效性的一个非常重要的方式。下面我们来介绍一下比较常用的 $explain 和 $hint 查询。 $explain $explain 运算符提供了有关查询、索引使用以及查询统计的相关信息,这在索引优化方面非常有用。《 MongoDB覆盖索引查询》一节中我们已经使用以下代码在 users 集合中的 gender 和 name 字段上的创建了索引: 在 mongo sh