《工商银行四川省分行》专题
-
如何将引导行划分为5个相等的部分?
我想把行分成5个相等的部分。它包括,那么我如何将它分成相等的5部分呢? 有人能帮我解决这个问题吗?
-
拆分(explode)pandas数据框字符串条目以分隔行
问题内容: 我有一个文本字符串的一列包含逗号分隔的值。我想拆分每个CSV字段并为每个条目创建一个新行(假定CSV干净,只需要在’,’上拆分)。例如,a应变为b: 到目前为止,我已经尝试了各种简单的函数,但是该.apply方法似乎只在轴上使用一行作为返回值,而我无法开始.transform工作。我们欢迎所有的建议! 示例数据: 我知道这是行不通的,因为我们通过numpy丢失了DataFrame元数据
-
如何在MySQL中将逗号分隔的值分成几行?
问题内容: 我在MySQL中有一个函数,该函数返回由逗号分隔的整数值列表,从而形成一个字符串。 例如 退货 这是后端(Java)所需的简单功能-但是现在,由于建议了新功能,我需要这些结果用于另一个查询,该查询可能正在使用 IN 关键字遍历这些查询,如下所示: 作为单个csv元素,MyFunction(23)的结果不可迭代。如果我可以使用某些函数,例如可以生成结果的函数,则以下内容将非常适合我的查询
-
使用Spring批处理作业分发进行远程分块
我在运行Spring批处理作业时遇到了一个技术问题。作业只是从DB(MongoDB)读取记录,对记录进行一些计算(聚合)并将记录结果写入另一个表。读取A、处理A、写入记录B B是A的许多记录的聚合。我想使用远程分块来垂直扩展我的系统,从而使处理部分缩放和快速。我面临的问题是,我需要同步A记录,以便在将结果写入B时处理它们不会发生冲突。如果我将10条A记录分发给4个从站,它们在将聚合结果写入B时会发
-
spark何时以及如何在执行器上分配分区
spark如何给一个执行器分配一个分区? 当我使用 1 个驱动程序和 5 个执行器在火花外壳中运行以下行时: 重新分区后,10个分区仍然位于原来的两个节点上(总共5个)。这似乎非常低效,因为5个任务在包含分区的每个节点上重复运行,而不是平均分布在节点上。在同一个rdds上重复多次的迭代任务中,效率低下最为明显。 所以我的问题是,Spark如何决定哪个节点具有哪个分区,有没有办法强制将数据移动到其他
-
使用pyspark对parquet文件进行分区和重新分区
步骤3我通过for循环加载每个分区,执行聚合,并以追加模式将其保存为文件夹,这样我就有9个模块作为文件夹:、等。它们不按模块分区,只是保存为文件夹。由于我的默认spark numpartitions是,每个模块文件夹都有文件,因此总共有文件 步骤4到目前为止还不错,但是我需要按把它分区回来。因此,我循环遍历每个分区,并将文件保存为一个没有任何分区的parquet文件。这导致总共有文件。我不知道这是
-
编译工作正常,但运行失败
问题内容: 我在主软件包的一个目录下有一些文件: main.go config.go server.go 当我这样做时:“执行构建”程序将完美构建并运行良好。当我这样做时:“ go run main.go”失败了。 输出: 未定义的符号是结构,并且大写,因此应将其导出。 我的Go版本:go1.1.2 linux / amd64 问题答案: 这应该工作 Go run需要一个文件或多个文件,并且它仅合
-
在运行时获取Maven工件版本
问题内容: 我注意到在Maven工件的JAR中,project.version属性包含在两个文件中: 是否有建议的方式在运行时读取此版本? 问题答案: 你无需访问特定于Maven的文件即可获取任何给定库/类的版本信息。 你可以简单地使用来获取存储在中的版本信息。幸运的是,足够聪明,不幸的是,默认情况下,也不将正确的信息写入清单! 相反,必须修改的设置元素和,如下所示: 理想情况下,应将此配置放入公
-
Kafka Connect 的行为是如何工作的?
我正在为 Elasticsearch 编写一个 Kafka Sink 连接器。 我实现了启动,把,刷新,关闭方法在Sink任务类。 但是,我不知道Kafka Sink Connector的行为到底起什么作用。 如果Connect Worker重复执行所有这些任务,即通过< code>put()方法从Kafka代理获取SinkRecord,在内部对其进行处理,然后将数据发送到Elasticsearc
-
150行Node.js实现的dns代理工具
本文向大家介绍150行Node.js实现的dns代理工具,包括了150行Node.js实现的dns代理工具的使用技巧和注意事项,需要的朋友参考一下 工具地址:github.com/Yi-love/dns… 安装: npm install dns-proxy-server -g 这个我觉得应该还是挺实用的一个工具。开发过程中我们需要配置IP来访问测试环境域名。 使用电脑开发测试还好,直接使用Swit
-
python命令行工具Click快速掌握
本文向大家介绍python命令行工具Click快速掌握,包括了python命令行工具Click快速掌握的使用技巧和注意事项,需要的朋友参考一下 前言 写 Python 的经常要写一些命令行工具,虽然标准库提供有命令行解析工具 Argparse,但是写起来非常麻烦,我很少会使用它。命令行工具中用起来最爽的就是 Click,它是 Flask 的团队 pallets 的开源项目。Click 只要很少的代
-
自动复制Google工作表中的行
我正在尝试编写一些函数 复制谷歌表单提交到从表单提交表到所有线索表 根据单元格值="open"将整行从"All Leads"工作表移动到"Open Leads"工作表 根据单元格值=关闭/丢失/空白将整行数据移回所有线索或关闭、丢失的工作表 但我不会让它触发onEdit或onFormSubmission。非常感谢您的帮助,正如您所知,我对脚本编写还不熟悉。 这是共享的谷歌电子表格 https://
-
 Flink工作流并行与自定义源
Flink工作流并行与自定义源我在Flink中构建了一个工作流,它由一个自定义源、一系列地图/平面地图和一个接收器组成。 我的自定义源的run()方法遍历存储在文件夹中的文件,并通过上下文的collect()方法收集每个文件的名称和内容(我有一个自定义对象,它将此信息存储在两个字段中)。 然后,我有一系列地图/平面图来转换这些对象,然后使用自定义接收器将其打印到文件中。在Flink的Web UI中生成的执行图如下所示: 我有一
-
 使用PrintPDF命令行工具打印PDFBox
使用PrintPDF命令行工具打印PDFBox我正在使用DHL Shipping(XML)API请求DHL发货并自动打印响应的发货标签。 系统是这样工作的: DHL响应XML包含base64编码的pdf,其中包含: 第1页。装运标签(打印在包装上的标签上) 第2页。存档文件(需要单独打印并交给快递员) 为了分离这两个PDF,我首先解码base64,然后使用PDFBox命令行工具执行PDFSplit,最后在各自的打印机上打印各自的文档: 问题是
-
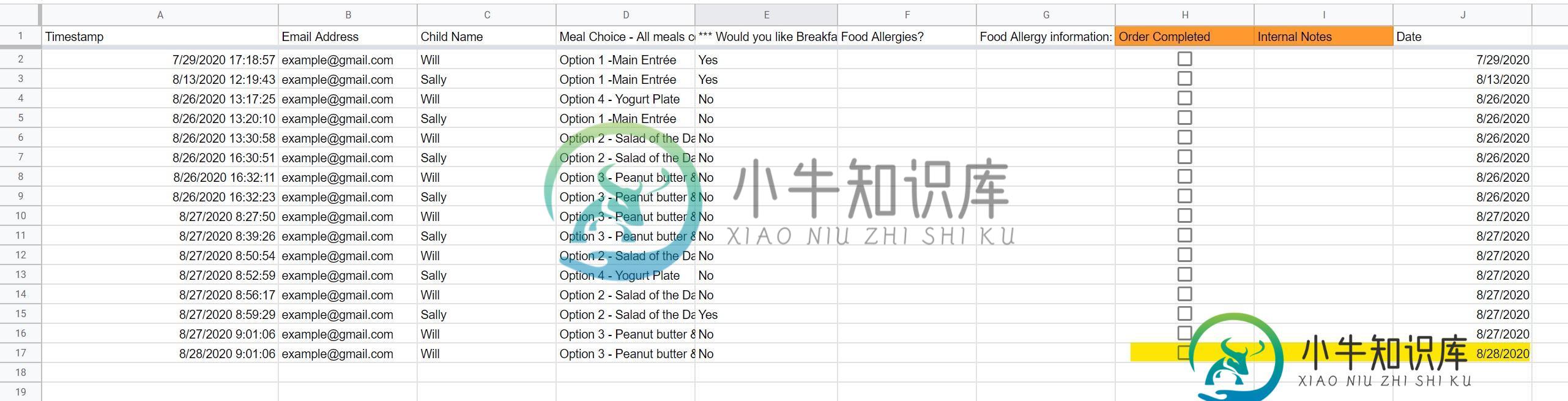 Google工作表脚本未完全执行
Google工作表脚本未完全执行我正在使用谷歌表单来触发这个脚本。 当我用播放按钮运行脚本时,它工作得很好。 当我让提交触发器运行它时,复选框填充正常,但setValue日期没有。 我也试过了但是我得到了相同的结果。 最终目标是让J列在每次提交表单时填充A列中的快照格式日期 我需要此格式在另一张工作表上运行countIfs。 另一种选择是以某种方式将格式标记嵌入到CountIfs命令中,以便它们匹配。