《这一年,我的高光时刻》专题
-
Java时间解析“2021年6月26日,04:30:15 pm NY”
似乎不包括在中,请注意这个错误,还有什么技巧可以避免在解析器中使用吗?
-
当格式设置为dd/mm/yyyy时,SimpleDataFormat似乎允许年
如果我有这个: 如果传入2位数的年份,我的应用程序应该抛出异常吗?这似乎没有任何问题。
-
编年史地图在超过200M条目时显著减慢
我正在使用编年史地图来临时存储/查找大量的KV对(实际上是数十亿)。我不需要持久性或复制,我使用的是内存映射文件,而不是纯堆外内存。平均密钥长度为8字节。 对于较小的数据集--多达2亿个条目--我得到的吞吐量约为每秒100万个条目,即创建条目需要大约200秒,这是惊人的,但到了4亿个条目时,地图已经显著放缓,创建它们需要1500秒。 我已经在Mac OSX/16GB四核/500GB SSD和Pro
-
使用Jodatime自动将秒转换为年/天/小时/分钟?
当x超过3600秒时,有没有办法把x秒转换成y小时和z秒?类似地,当x超过60但小于3600秒时,使用Jodatime将其转换为“A分钟和b秒”?我明白我必须在PeriodFormatter中指定我需要什么,但我不想指定它--我想要一个基于秒值的格式化文本。 这类似于你在论坛上发帖,然后你的帖子最初会显示为“10秒前发布的”…一分钟后,你会看到“1分20秒前发布”,几周、几天、几年都是如此。
-
 2024年华为OD机试真题-会议室占用时间
2024年华为OD机试真题-会议室占用时间华为OD机试真题-会议室占用时间-2024年OD统一考试(D卷) 题目描述: 现有若干个会议,所有会议共享一个会议室,用数组表示各个会议的开始时间和结束时间,格式为: [[会议1开始时间,会议1结束时间],[会议2开始时间,会议2结束时间]] 请计算会议室占用时间段。 输入描述: [[会议1开始时间,会议1结束时间],[会议2开始时间,会议2结束时间]] 备注 会议室个数范围: [1,100] 会
-
当我使用cx_Freeze时TCL_Library
当我使用时,我得到一个KeyError,同时构建我的pyplay程序。我为什么会得到这个,我该如何修复它? 我的设置。具体如下:
-
为什么我的排序功能不直接地做这项工作?
通常,当我只对参数化对象进行排序时,它会完美地预成型,但是当我添加没有数据的对象时,它就会发疯。帮助。 顺便说一句,我想要按降序排序的数据,由“Stanje na racunu”排序,或者用英语“你的账户余额”排序,它接受对象类中的“stanje”变量并对其进行比较。我将再次重复。当tr1、tr2和tr3不包括在内时,这是完美的。帮助 结果如下。 所需的输出是(不是完整的,只有名称(vlasnik
-
Heroku的这个错误是什么意思,我该如何解决它?
当我试图通过heroku打开我正在处理的应用程序时,我得到了一个应用程序错误。我查看了heroku日志,发现以下错误: “错误H10(应用程序崩溃)- 我不确定错误指的是什么,或者我如何解决导致错误的问题。你能给的任何帮助都会很棒!
-
为什么我的SHA-256转换不符合这个在线工具?
我为SHA-256编写了一个字符串: 使用此工具运行SHA-256得到的输出为,但当我自己运行它时,得到的是
-
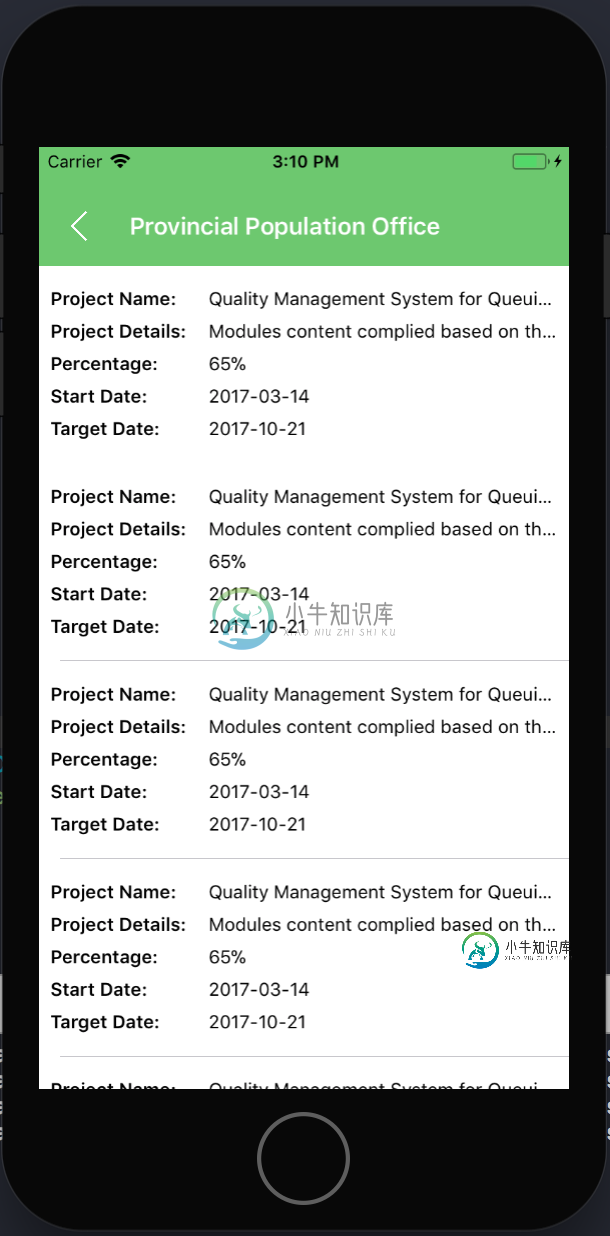 我可以知道这个最好的UI / UX方法是什么吗?
我可以知道这个最好的UI / UX方法是什么吗?我必须在此处显示tableView中的所有数据,但其他细节不适合设备的大小。 正如您所看到的,除了“项目详细信息”之外,这些信息是可读的。但是客户给我说,“项目细节”可能比设备屏幕(iPhone o iPad||横向或纵向)更长。 如果项目详细信息的字符串比设备屏幕长,那么显示这些信息的最佳方法是什么?
-
如果我使用像express这样的节点服务器,我是否需要webpack dev服务器
我下面的一些教程,以建立一个同构的应用程序与表达和反应。我与webpack开发服务器混淆。 webpack教程介绍了webpack开发服务器: 这将绑定localhost:8080上的一个小型express服务器,它为您的静态资产和捆绑包(自动编译)提供服务。 当包被重新编译(socket.io)时,它会自动更新浏览器页面。在浏览器中打开http://localhost:8080/webpack-
-
PHP错误:为什么这不工作,我不能在我的页面中看到数据结果?
我正在设置一个新的wampserver,并使用名为“users”的表创建了一个新的数据库 apache 2.4.23 我的值实际上在数据库中,但在运行代码后页面中没有显示任何内容
-
我希望代码在这里结束。下面的步骤不再继续。我该怎么做呢?
[返回res.redirect(“/register”);]如果用户不存在,我希望代码在此结束。下面的步骤将不会继续。 我该怎么做呢?
-
我可以在树集的构造函数中同时有一个ArrayList和一个比较器吗?
假设我在一个ArrayList中有一个属性为name(String)和age(int)的类Pet,我想在不使用Collections框架的情况下对它们进行排序,所以我使用一个TreeSet来解析ArrayList。我的问题是,有没有方法在TreeSet的构造函数中初始化一个新的比较器(与ArrayList一起),或者我必须在Pet类中实现一个新的比较器/比较器? 我已经通过在Pet类中实现一个可比
-
为从目录中读取光栅、将数据汇总到单个光栅并输出新光栅而创建的循环的索引不起作用
我有几个目录,里面都是每日的气候数据。我需要将每日栅格合并为每周栅格,一些是通过值的总和,一些是通过值的平均值。到目前为止,我已经在目录(其中包含每日光栅文件)中创建了一个文件名向量,并为编写了一个