《补录》专题
-
来自PyExecutor的Spark日志记录
问题内容: 使用pyspark on访问Spark的log4j记录器的正确方法是什么 遗嘱执行人? 在驱动程序中这样做很容易,但我似乎不明白如何访问 executor上的日志记录功能,以便我可以在本地进行日志记录并 纱线收集当地的原木。 有什么方法可以访问本地记录器吗? 标准的日志记录过程是不够的,因为我无法访问spark 执行器的上下文。 问题答案: 不能对执行器使用本地log4j记录器。Pyt
-
PyLint消息:日志记录格式插值
问题内容: 对于以下代码: 产生以下警告: 日志记录格式插值(W1202): 在日志记录函数中使用%格式,并将%参数作为参数传递。在日志记录语句的调用形式为“ logging。(format_string.format(format_args …))”时使用。这样的调用应改为使用%格式,但通过将参数作为参数传递,将插值留给日志记录函数。 我知道我可以关闭此警告,但我想理解它。我假定使用是在Pyth
-
python pexpect ssh 远程登录服务器的方法
本文向大家介绍python pexpect ssh 远程登录服务器的方法,包括了python pexpect ssh 远程登录服务器的方法的使用技巧和注意事项,需要的朋友参考一下 使用了python中的pexpect模块,在测试代码之前,可输入python进入交互界面,输入help('pexpect'),查询是否本地含有pexpect模块。 如果没有,linux系统输入 easy_install
-
如何使用Fabric将目录复制到远程计算机?
问题内容: 我在本地计算机上有一个目录,我想使用Fabric将其复制到远程计算机上(并重命名)。我知道我可以使用复制文件,但是目录呢。我知道使用 scp 很容易,但是如果可能的话,我宁愿在我内部进行。 问题答案: 您也可以使用它(至少在1.0.0中使用): 可以是相对或绝对本地文件或 目录路径 ,并且可以包含 shell样式的通配符 ,如Python glob 模块所理解的那样。波形扩展(由os.
-
mysql技巧:提高插入数据(添加记录)的速度
本文向大家介绍mysql技巧:提高插入数据(添加记录)的速度,包括了mysql技巧:提高插入数据(添加记录)的速度的使用技巧和注意事项,需要的朋友参考一下 问题描述: 普通台式机,采集数据,表中已经有>1000万数据量。 采集回来的数据插入表中的时候很慢,每条约100毫秒。 解决方法: 1、加大mysql配置中的bulk_insert_buffer_size,这个参数默认为8M bulk_inse
-
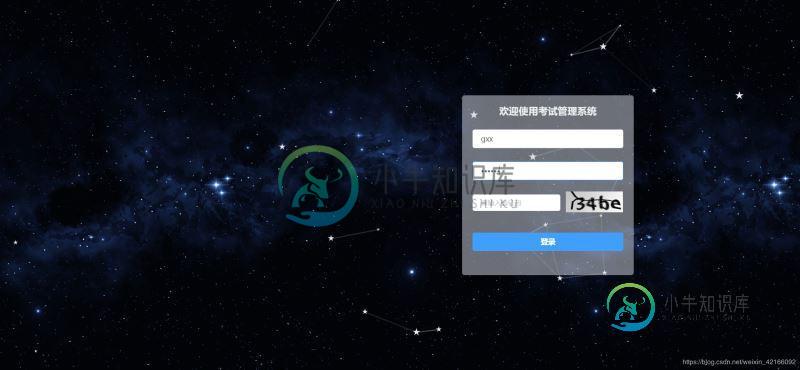 python自动化实现登录获取图片验证码功能
python自动化实现登录获取图片验证码功能本文向大家介绍python自动化实现登录获取图片验证码功能,包括了python自动化实现登录获取图片验证码功能的使用技巧和注意事项,需要的朋友参考一下 主要记录一下:图片验证码 1.获取登录界面的图片 2.获取验证码位置 3.在登录页面截取验证码保存 4.调用百度api识别(目前准确率较高的识别图片api) 本次登录的系统页面,可以看到图片验证码的位置 上面我们已经把图片保存到本地 这就是我们截取
-
npm WARN ENTENT ENOENT:没有此类文件或目录,请打开“ C:\ Users \ Nuwanst \ package.json”
问题内容: 我只想将socket.io安装到位于3.chat文件夹中的项目中。但是当我运行以下命令时,它显示以下警告。并且它没有在我的项目文件夹中创建一个node_modules目录。如何解决这个问题? 问题答案: 您是否创建了 package.json 文件?也许先运行此命令。 它在您的文件夹中创建一个 package.json 文件。 然后跑 在确保您的模块保存为您的依赖关系 的package
-
如何在mongoose.js中获取最新和最旧的记录(或它们之间的时间跨度)
问题内容: 基本问题 我有一堆记录,我需要获取最新(最新)和最旧(最新)的记录。 谷歌上搜索时,我发现这个话题,我看到一对夫妇的查询: 不幸的是,它们都出错: 该链接也包含以下内容: 那一个错误: 那么我如何获得这些记录? 时间跨度 更为理想的是,我只希望最旧记录与最新记录之间的时间差(秒?),但是我不知道如何开始进行这样的查询。 这是模式: 我很确定我拥有mongoDB和mongoose的最新版
-
Passport.js:password-facebook-token策略,通过JS SDK登录,然后对护照进行身份验证?
问题内容: 我一直在寻找一种让我的客户使用facebook JS SDK授权的方法,然后以某种方式将此授权转移到我的节点服务器(以便它可以使用fb graph api验证请求) 我偶然发现了:https : //github.com/jaredhanson/passport- facebook/issues/26 和 https://github.com/drudge/passport-faceb
-
更改模块目录后的Python酸洗
问题内容: 我最近更改了程序的目录布局:以前,我的所有模块都位于“主”文件夹中。现在,我将它们移动到以该程序命名的目录中,并在其中放置一个包。 现在,我的主目录中只有一个.py文件,用于启动程序,这更加整洁。 无论如何,尝试从程序的早期版本中加载腌制文件失败。我收到“ ImportError:没有名为工具的模块”的信息- 我猜是因为我的模块以前位于主文件夹中,而现在位于whyteboard.too
-
运行节点bin脚本时确定命令行工作目录
问题内容: 我正在创建节点命令行界面。它是全局安装的,并使用bin文件执行。 我计划在正在处理的文件的根目录下打开一个命令窗口,然后运行命令,但是由于返回节点包的目录,我无法确定当前的工作目录。最初,我假设由于代码是使用批处理文件作为包装器执行的(这就是bin文件可以在开始时没有节点的情况下执行的方式),所以这是不可能的,但是coffee- script可以做到这一点。我看了看咖啡脚本的源代码,但
-
在node.js和mongodb中创建注册和登录表单
问题内容: 我是node.js的新手,并希望为用户创建一个注册和登录页面。还需要对该用户进行适当的授权。我想将用户信息存储在mongodb数据库中。我该如何实现?有人可以提供我吗?这样做的代码,以便我可以开始使用node.js和mongodb。请帮助 问题答案: 您可以在Alex Young 的Nodepad应用程序中找到要执行的操作的完整示例。您应该查看的2个重要文件是这些2: https :
-
如何使用npm在当前目录中安装package.json依赖项
问题内容: 我有一个Web应用程序: fooapp 。我有根。我想将所有依赖项安装在特定的中。我该怎么做呢? 我想要的是 可以说我有两个依赖项。我想以这样的目录结构结束: 我得到什么 当我跑步时, 我得到以下信息: npm在node_modules目录中复制我的应用程序目录,并将软件包安装在 另一个 node_modules目录中。 我了解这对于安装软件包很有意义。但是我不在其他地方使用Web应用
-
我可以还是应该在Angularjs中使用Global变量来存储登录用户?
问题内容: 我刚开始接触角并正在开发我的第一个“真实”应用程序。我正在尝试构建一个日历/计划应用程序(源代码都可以在github上看到),并且我希望能够在有用户登录的情况下更改内容(即显示与他们相关的详细信息),但是这里有个问题: 我不希望该应用依赖于已登录的用户(需要配置为可公开,私密或同时工作) 如果可以避免,我不想在此应用程序中实现用户/登录(我想最终将我的应用程序包含在可能已实现但不一定使
-
从同级目录导入
问题内容: 我有一个名为“ ClassA”的Python类,另一个应该导入“ A ClassB”的ClassA的Python类。目录结构如下: 我将如何使用,以便ClassB可以使用ClassA? 问题答案: 您确实应该使用软件包。然后将MainDir放置在文件系统中sys.path上的某个点(例如… / site- packages)上,然后可以在ClassB中说: 您只需要在每个目录中放置命名