《量化》专题
-
FastAPI变量查询参数
我正在编写一个Fast API服务器,它接受请求,检查用户是否被授权,如果成功,则将其重定向到另一个URL。 我需要携带URL参数,例如
-
硒递归含量测试?
假设一个网站有以下结构 类似地,链接3,链接4 现在我需要遍历每个链接Link1,Link2,Link3,Link4来提取最后一页上没有后续链接递归存在的内容。 但目前递归不起作用,它抛出 由于当前页面不同,无法保留旧元素信息,并且页面已移动到新页面,因此会引发错误。 递归搜索内容的最佳方法是什么??? 示例代码段:
-
Spark流:广播变量,java.lang.ClassCastException
当我这样做时,我得到了一个java.lang.ClassCastException:不能将Scala.some实例分配给org.apache.spark.accumulator实例中scala.option类型的字段org.apache.spark.accumulable.name与硬编码ArrayBuffer相同的代码工作得很好,所以我假设它与静态文件资源有关...有人知道我可能做错了什么吗?任
-
无法创建d::矢量
我可以创建std::数组: 它很好用。但我无法创建向量: 这给了我一个错误:
-
使用变量的装配
我试图使文本屏幕打印'h',这是存储在一个变量。我在用NASM。x86保护模式,一个从头开始的内核。
-
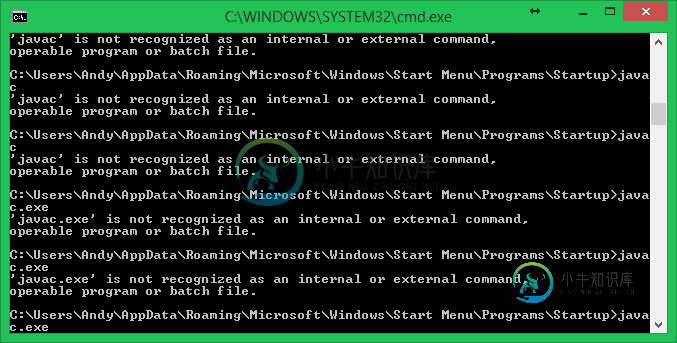 路径变量不工作
路径变量不工作我的java bin文件夹包含java.exe @大卫华莱士 Microsoft Windows[版本6.3.9600](c)2013 Microsoft Corporation。保留所有权利。 C:\用户\Andy\AppData\漫游\Microsoft\Windows\开始菜单\Programs\Startup>
-
ElasticSearch-高索引吞吐量
我正在对ElasticSearch进行基准测试,以实现非常高的索引吞吐量。 我目前的目标是能够在几个小时内索引30亿(3,000,000,000)文档。为此,我目前有3台windows服务器机器,每台16GB内存和8个处理器。插入的文档有一个非常简单的映射,只包含少数数字非分析字段(被禁用)。 使用这个相对适中的钻机,我能够达到每秒大约120,000个索引请求(使用大桌子监控),我相信吞吐量可以进
-
Java度量示例代码
我是度量的新手,我不明白为什么我得到这个输出,请有人解释。提前感谢。 输出: 12/18/15 12:01:15PM = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = -- 计量----------------------------------------
-
控制每秒吞吐量
我有一个类女巫负责向客户端发送数据,所有其他类在需要发送数据时都使用这个。让我们称之为“数据ender.class”。 现在客户端要求我们将吞吐量控制在每秒最多50次调用。 我需要在这个类上创建一个algoritm(如果可能的话),以保持当前秒的调用次数,如果它达到50的最大值,保持进程要么睡眠或某事,并继续而不丢失数据。也许我必须实现一个队列或比简单的睡眠更好的东西。我需要建议或遵循的方向。 为
-
从集群收集度量
有人能建议从节点集群收集指标的最佳模式吗(每个节点都是带有Java应用程序的Tomcat Docker容器)? 我们计划使用ELK堆栈(ElasticSearch、Logstash、Kibana)作为可视化工具,但我们的问题是如何将指标交付给Kibana? 我们使用DropWizard度量库,它提供每个实例的度量(量表、计时器、直方图)。 显然,应该收集每个实例的一些指标(例如,cpu、内存等..
-
大量数据库连接
我的设置如下:
-
Softmax输出大量错误
下面是一个小代码,我正试图计算softmax。它适用于单个阵列。但是如果数量更大,比如1000等,就会爆炸 我收到一个错误 运行时警告: 在 exp 中遇到溢出 运行你的代码 softmax1 = np.exp(x)/np.sum(np.exp(x))
-
继承变量上的@ConfigurationProperties
我有一个超类看起来像这样 扩展类 科目类 尝试将从强制转换为时,出现无法强制转换的异常。 原因:java.lang.ClassCastException:com.example.bean.hrs.ProviderAccount无法强制转换为com.triphop.bean.hrs.CustomProviderAccount(位于com.triphop.service.hrsServiceImpl.
-
docx4j用html替换变量
有没有办法做到这一点?
-
Bitbucket管道变量为curl
我正在使用bitbucket管道,在一个步骤中,我想调用curl请求我们的API来将部署数据保存在DB中。 但是当我试图用BITBUCKET_BRANCH和BITBUCKET_REPO_SLUG变量调用curl时,它们总是为空或者根本没有填充。 这是我从管道中得到的回复。 你可以看到,对于分支dev1/*,我有第一步,我用两个变量调用curl。我尝试了两种使用我在互联网上找到的变量的方法,但都不起