《集度》专题
-
Jprofiler和WebSphere 8集成问题
我在将JProfiler连接到Linux上运行的远程WebSphere 8.5.5实例时遇到了一些问题。当我在我的Windows 10机器上启动JProfiler时,我选择“本地或远程配置应用程序服务器”,并选择与IBM WebSphere 8集成的选项。x应用服务器。 我遇到的问题是设置配置文件的“指定远程地址”部分。安装程序说我需要在目标JVM上运行分析代理。我从JProfiler网站下载ta
-
Integer、AbstractVector{Integer}和String的并集
我有一个函数,在这个函数中,用户传递一个参数来选择应该处理矩阵的哪些列,如下所示: 我想让用户有一种方法来指定应该处理所有列,最后我更改了函数,使其成为默认行为: 为什么一个整数、一个整数向量和一个字符串之间的联合似乎不起作用?
-
Saxon-HE集成扩展函数
我最初应该发布我的问题,说明我们的代码使用了一个嵌入式撒克逊扩展函数——撒克逊:解析($xml),它返回xml的根元素/节点。然而,在Saxon-HE中,该扩展不再可用——所以我试图编写一个集成扩展,将xml字符串解析到文档中并返回根元素。 我使用的是Saxon HE 9.5.1.6——我试图编写一个集成的扩展函数,返回文档的根节点。该函数接收一个xml字符串——创建一个文档,并需要将根节点返回给
-
集成AWSJavaSDK 2. x与Spring Sleuth
我第一次使用Spring Boot,正在为我的应用程序设置分布式跟踪。我已经将Spring Cloud Slueth添加到我的应用程序中,当调用我的endpoint时,我可以看到生成的跨度和跟踪,但是我很难让它与Aws Sdk 2. x集成(使用Dynamo异步客户端)。我有几个关于集成的问题: 通过aws sdk跟踪http调用的最佳方式是什么。我能做到这一点的唯一方法是实现ExecutionI
-
redisson连接到远程群集
我已经创建了一个redis集群,它自己是工作的,但我不能连接我的客户到它。 我正在使用redisson连接到它,下面的代码 其中,redisURL是csv,格式为:,但包含集群中的所有6个节点。
-
对ArrayList使用集合排序
因此,我有实现comparable的类,但当我试图创建调用Collections.sort()的排序方法时,它给出了一个错误,说明我不能用ArrayList调用collection sort。有人能帮忙吗?并且帮助我使用compareTo方法,我仍然停留在如何比较ArrayList中的每个元素上
-
集中式Java日志记录
我正在寻找一种方法来集中分布式软件(用Java编写)的日志问题,这将非常简单,因为所讨论的系统只有一台服务器。但请记住,未来很可能会运行更多特定服务器的实例(并且需要更多的应用程序),因此必须有类似日志服务器的东西,它负责处理传入日志,并使支持团队能够访问这些日志。 目前的情况是,一些java应用程序使用log4j将其数据写入本地文件,因此,如果客户机过期出现问题,支持团队必须要求提供日志,这并不
-
关于结果集类型JDBC
在这个oracle java教程中,它说: TYPE_FORWARD_ONLY:结果集不能滚动;其光标仅向前移动,从第一行之前移动到最后一行之后。结果集中包含的行取决于基础数据库如何生成结果。也就是说,它包含在执行查询时或在检索行时满足查询的行。 “结果集中包含的行取决于基础数据库生成结果的方式。 查询执行时间和行检索时间有什么区别?我如何知道我的数据库支持哪些?提前致谢。
-
使用spock的集成测试
在我的应用程序中有,它有一个操作,如下所示: 现在,我正在测试视图和模型,如下所示: 但是我的测试用例失败了,stacktrace如下: 正在运行2个spock测试。。。第1页,共2页 有什么问题吗。
-
ItemReader集成测试抛出ClassCastExctive
我正在尝试集成测试一个ItemReader——下面是一个类: 这是我的豆子。xml: 这是我想写的测试: 我java.lang.ClassCastExctive:com.sun.proxy.$Proxy36不能在之前和之后转换为ItemReader。我错过了什么?是否还有其他需要设置的东西(例如配置xml中的任何注释或条目)?
-
链动画师集Android动画
对于android新手,我想制作一些平滑的动画。 我在设备上有一个文件,其中包含效果,每个效果都是一个动画。该文件告诉我何时播放效果以及效果持续时间。 问题是我不能链动画师动态设置: 现在我如何从我的AnimatorSet()列表中得到mainAnimatorSet();每个动画从最后一个动画的结尾开始。 这不起作用。谢谢
-
ASP. NET MVC与LACRM Api集成
我以前在另一篇文章中问过这个问题,但是我没有收到回复。我正在尝试将ASP. Net MVC与少烦人的CRM API集成。目的是将表单提交存储到CRM中,以便将每个提交组织成类别或任务。LACRM api是为PHP设计的,开发人员提到他们缺乏在C#方面提供帮助的技能。这是我的代码(LACRM使用默认字段“FullName”和“Email”,然后它有一个参数“CustomFields”,以便可以创建自
-
AWS Spark群集设置错误
我创建了一个AWS密钥对。 我在这里逐字逐句地遵循指示:https://aws.amazon.com/articles/4926593393724923 当我键入“aws emr创建集群——名称SparkCluster——ami版本3.2——实例类型m3.xlarge——实例计数3——ec2属性KeyName=MYKEY——应用程序名称=Hive——引导操作路径=s3://support.elas
-
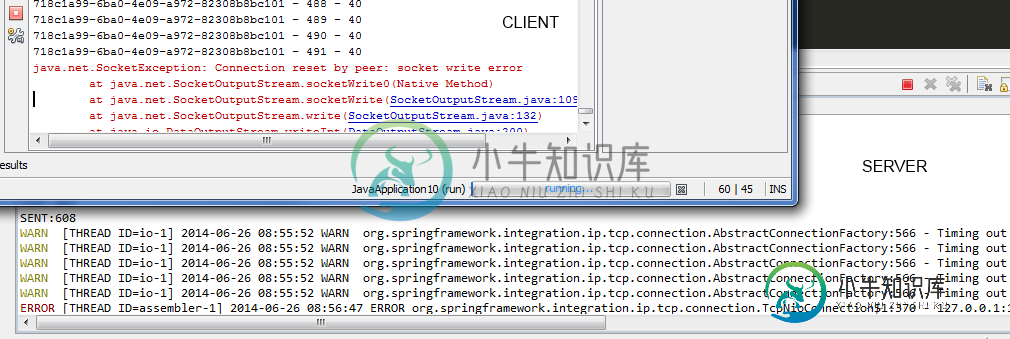 Spring集成超时客户端
Spring集成超时客户端我对Spring集成的设想是: 使用自定义协议(大小和内容)发送数据的十个生产者 我必须解码这个自定义协议,然后处理结果。 所以我尝试了很多配置,目前最好的配置如下: 序列化类为: 我使用此代码来测试服务器: 当我用一个线程执行此操作时,如果我尝试执行多个线程,则效果很好,如: spring集成服务器卡住了,我有以下警告: 而且它不工作,服务器无法接收消息。 我错在哪里?非常感谢。 编辑 我这样修
-
jdbcTemplate是否关闭结果集?
我有一个spring应用程序,它的主页发出多个ajax调用,这些调用反过来从DB中提取数据并返回。DB已配置连接池,minPoolSize为50,maxPoolSize为100。 现在,当我打开主页时,大约有7个连接与DB建立,这是因为大约有7个ajax调用被调用,我假设所有调用都创建了自己的连接。现在,当我刷新页面时,我看到又建立了7个新连接(我看到db2监控中总共有14个物理连接),这似乎出乎