《上海》专题
-
在父上下文和子上下文中声明Spring Bean
问题内容: 我有一个Spring bean(dao)对象,该对象通过以下xml在ServletContext中实例化: 该bean在我的webapp-servlet.xml文件中声明,并由我的应用程序在ServletContext中使用。 我也在使用SpringSecurity。据我了解,这在不同的上下文(SecurityContext)中运行。 我的应用程序具有webapp-security.x
-
php文件上传,如何限制文件上传类型
问题内容: 我有以下代码来检查(上传的简历和推荐信是否与所需类型(pdf或doc或docx)匹配)和大小(小于400 kb) 这无法正常工作,甚至连txt文件都没有通过+大小限制,这是怎么回事? 谢谢, 问题答案: 下面仅使用mime类型来验证文件,然后检查两者的大小。有关大多数MIME类型的列表,请参见此处或google。
-
在DalvikVM之上的Android-Sun JVM上运行Java字节码
问题内容: 由于Java实现()和Android的虚拟机DalvikVM都是开源的,因此必须有可能在Google的DalvikVM之上实现Sun的JavaVM。这样就可以在android上开箱即用地运行基于JVM的应用程序和语言()。 是否正在持续努力以产生Sun JVM的这种实现? 问题答案: OpenJDK使用本机代码,因此它是一个不平凡的端口……至少有一个用Java编写的VM(JikesRV
-
jQuery文件上传始终失败,文件上传中止
问题内容: 我试图让Blueimp的Jquery File Upload插件在我的网站上正常工作,但是我一生都无法用它来上传文件。我整天都在努力,被困住了。它将上传文件并将其提交到UploadHandler类,但是在尝试完成功能时,它将达到: 但这总是返回0。我无法弄清楚为什么无法上传该文件。我得到的完整答复是: 仅实例化UploadHandler,仅此而已。 如果您想查看有关UploadHand
-
如何在网页上实现文件上传进度条?
问题内容: 当用户将文件上传到我的Web应用程序时,我想显示比gif动画更有意义的内容。我有什么可能性? 编辑:我正在使用.Net,但我不介意是否有人向我展示平台不可知的版本。 问题答案: 以下是一些常用JavaScript工具包的几种版本。 Mootools- http: //digitarald.de/project/fancyupload/ Extjs- http: //extjs.com/
-
通过JavaScript上传之前如何上传预览图像
问题内容: 我想先预览图像,然后再将其上传到服务器。我已经为其编写了一些代码,但是由于某种安全原因,它只能在Internet Explorer中预览,而不能在其他浏览器(如Safari,Chrome,Firefox)中预览。有什么解决方案可以在这些浏览器中预览图像吗? 问题答案: 对于Firefox。由于安全原因,它的路径被截断了。但是,他们提供了其他方法: 以下内容适用于Internet Exp
-
JDBC连接在Windows上工作,但在Ubuntu上不工作
我有一段非常简单的Java代码,在那里我尝试从Java连接到我的Oracle DB。 在Windows下一切正常,但当我尝试在Ubuntu上运行时,我得到了一个错误。 我读了很多书,也试过很多解决方法。这是我的代码: 当我运行它时,我收到一个错误: 连接失败Java.sql.sqlRecoverable异常:IO错误:网络适配器无法在oracle.jdbc.driver.T4CConnection
-
在Ubuntu 14.04 LTS上的wget上无法建立SSL连接
问题内容: 我试图通过wget下载图像,但出现错误:无法建立SSL连接。 我的测试用例: 使用Ubuntu 12.04.4 LTS(GNU / Linux 3.8.0-44-通用x86_64),基于linux-gnu构建的GNU Wget 1.13.4,我能够使用上面的代码下载映像。没错 使用Ubuntu 14.04 LTS(GNU / Linux 3.13.0-24-通用x86_64),基于li
-
Spring boot实现文件上传实例(多文件上传)
本文向大家介绍Spring boot实现文件上传实例(多文件上传),包括了Spring boot实现文件上传实例(多文件上传)的使用技巧和注意事项,需要的朋友参考一下 文件上传主要分以下几个步骤: (1)新建maven java project; (2)在pom.xml加入相应依赖; (3)新建一个表单页面(这里使用thymleaf); (4)编写controller; (5)测试; (6)对上传
-
如何在Informix上的磁盘上写入二进制Blob
问题内容: 我在notifyix数据库中有一些图像,作为二进制Blob字段(jpg),如何使用SQL将图像写到磁盘上? 问题答案: 数据存储在BYTE或BLOB字段中吗? 如果数据存储在BLOB列中,则可以使用: 如果数据存储在BYTE列中,则您必须付出更大的努力。如果您的计算机上装有ESQL / C(ClientSDK)和C编译器,则建议从IIUG软件档案库中获取SQLCMD并解压缩该软件。您需
-
 Jsp+Servlet实现文件上传下载 文件上传(一)
Jsp+Servlet实现文件上传下载 文件上传(一)本文向大家介绍Jsp+Servlet实现文件上传下载 文件上传(一),包括了Jsp+Servlet实现文件上传下载 文件上传(一)的使用技巧和注意事项,需要的朋友参考一下 文件上传和下载功能是Java Web必备技能,很实用。 本文使用的是Apache下的著名的文件上传组件 org.apache.commons.fileupload 实现 下面结合最近看到的一些资料以及自己的尝试,先写第一篇文件上
-
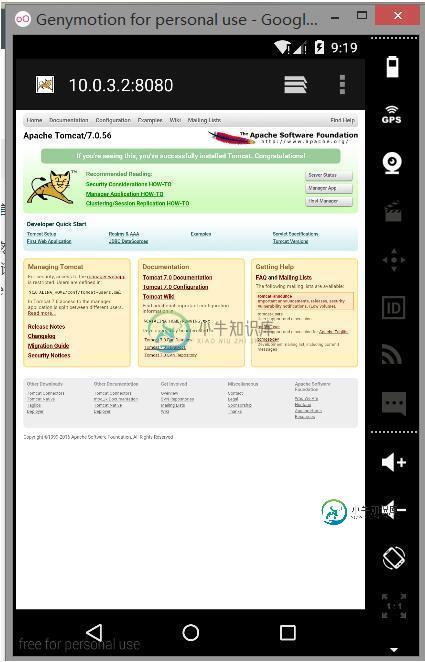 使用genymotion访问本地上Tomcat上数据的方法
使用genymotion访问本地上Tomcat上数据的方法本文向大家介绍使用genymotion访问本地上Tomcat上数据的方法,包括了使用genymotion访问本地上Tomcat上数据的方法的使用技巧和注意事项,需要的朋友参考一下 1、首先 当然是启动genymotion 2、然后Tomcat ,启动tomcat。。如图 将请求的URL地址变为10.0.3.2 ,比如在电脑上访问的是http://localhost:8080/ 那么在genymot
-
在Connect-redis和ioredis上的AWS配置上的Redis集群
我在AWS(ElastiCache)上配置了Redis集群。 它有一个配置endpoint和6个节点(3个碎片)。 在这里阅读npm模块的文档时,它说您必须合并ioredis才能使其用于Redis集群。 我共享了以下配置,该配置适用于单个Redis节点,但不适用于集群 我的问题是-如何合并ioredis来支持集群? 这对我来说是一个巨大的障碍,所以任何帮助都将受到高度赞赏。 全网找例子,一无所获!
-
更改Spring boot 2.1.2上文件上传的大小限制
我正在开发一个带有角前端和springboot2.1.2后端的项目,并实现了一种上传图像的方法。但是,它仅在图像是 org.apache.tomcat.util.http.fileupload.FileUploadBase$FileSizeLimitExceededException:字段图像超过其最大允许大小1048576字节 我已经看了这些问题:我正在尝试设置maxFileSize但不尊重Sp
-
Angular下H5上传图片的方法(可多张上传)
本文向大家介绍Angular下H5上传图片的方法(可多张上传),包括了Angular下H5上传图片的方法(可多张上传)的使用技巧和注意事项,需要的朋友参考一下 最近做的项目中用到了angular下上传图片功能,在做的过程中遇到了许多问题,最终都得以解决 angular上传时和普通上传时过程差不多,只不过是要不一些东西转化为angular的东西。 1.ng-file-select,指令angular