《七牛云》专题
-
谷歌云网络负载均衡器-健康检查总是不健康
我试图在谷歌云上设置网络负载均衡器,但健康检查总是返回不健康的结果。 我给你我遵循的步骤 > 我创建了两个windows Server 2012 R2实例 我检查了端口80在这两个实例上是否对公众开放 我创建了转发规则,谷歌云给了我一个外部IP 我在两个服务器实例的网络环回接口中设置了外部IP 我创建了一个网络路由,用于转发两个实例上的流量(路由菜单) 我为169.254.169.254/32(网
-
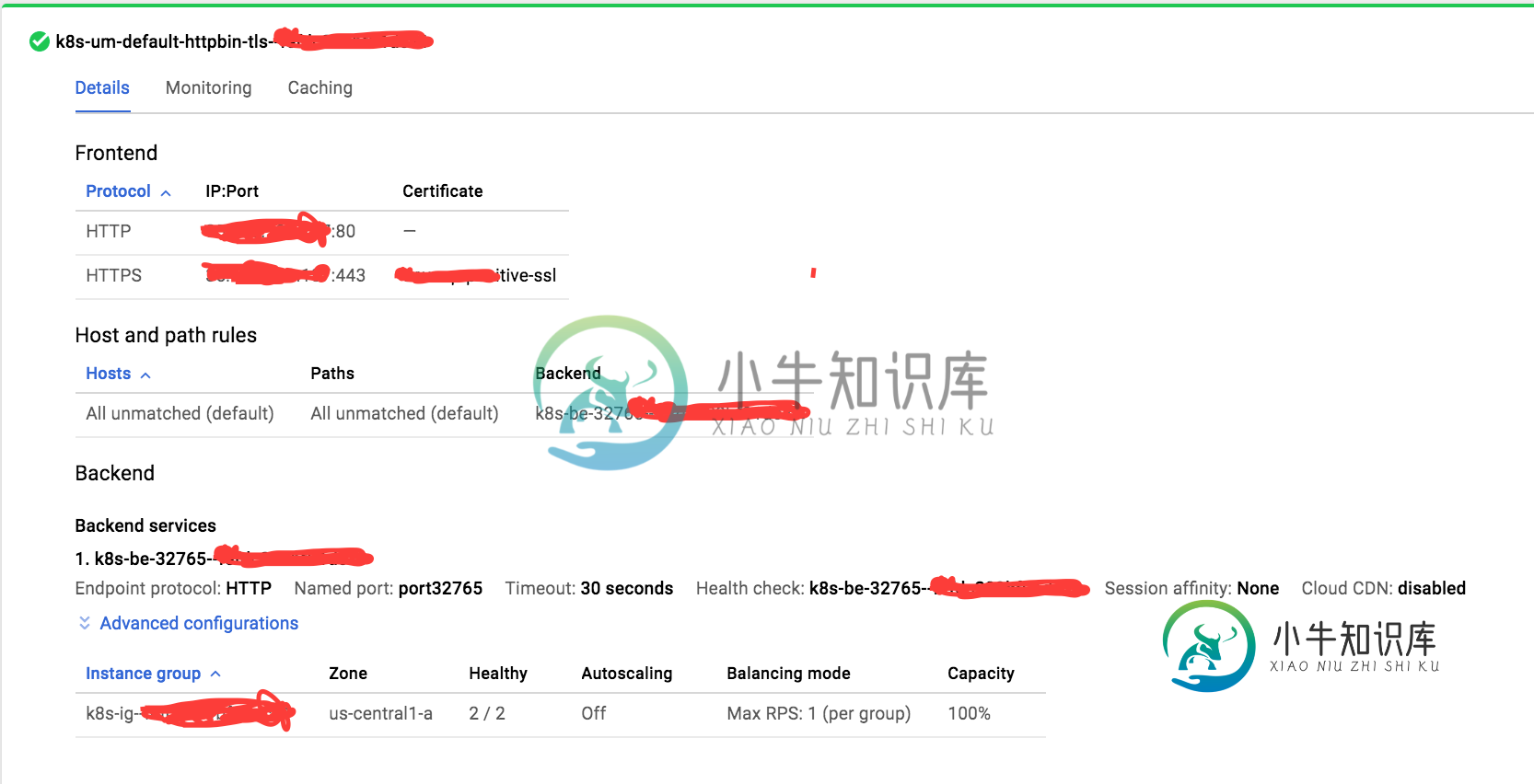 Google云负载平衡器使用Kubernetes入口强制HTTP而不是HTTPS
Google云负载平衡器使用Kubernetes入口强制HTTP而不是HTTPS我正在尝试部署一个Docker容器,它公开了一个简单的Docker服务器,它是Google容器引擎(库伯内特斯)中httpbin.org服务的克隆。 这是我正在使用的服务定义: 入口定义为: 在服务/入口仪表板中,我可以看到两个IP,一个直接绑定到服务(临时),另一个静态IP绑定到入口。直接在80号端口给他们两个打电话很有魅力。 完成后,我为静态IP创建了一个A记录,并确保GKE仪表板中的负载平衡
-
在Google云上使用HTTP负载平衡器和容器集群
我想在Google容器引擎上运行docker映像的集群前面放置一个HTTP负载平衡器,这样我就可以使用HTTPS,而无需应用程序支持它。 我使用以下命令创建了一个容器集群: 然后,我创建了一个复制控制器,在集群上运行一个映像,该映像基本上是nginx,其中复制了静态文件。 如果我为此创建一个网络负载平衡器,一切都会正常工作。我可以转到我的负载平衡器IP地址并查看网站。但是,如果创建HTTP负载平衡
-
设置多个入口、服务、部署资源和云DNS
本质上,我想为每个包含一个或多个子域的服务设置一个入口,所有这些入口都指向同一个集群。现在,我通过每个入口获得不同的临时IP。我可以创建一些转发规则,将所有流量指向静态IP转到集群,然后可能创建一个通配符DNS条目,将所有子域指向静态IP吗? 这是一个类似于我正在使用的示例配置: 我在kube集群上创建这些资源,如下所示: 然后查看这样创建的入口: 现在,假设您复制了上面的yaml,并将服务、部署
-
谷歌云入口:库伯内特斯使用其他地区的区域IP
我们目前仍在欧洲西部地区2(伦敦)运行Kubernetes群集,但必须使用新的IP地址从欧洲西部3(法兰克福)进入群集。 在尝试在europe-west2地区的集群上部署新入口后,我发现以下错误: 我假设入口只能访问同一区域的区域IP地址。 我使用以下注释: 有人知道如何在进入europe-west2时使用europe-west3的IP地址吗? 干杯干杯
-
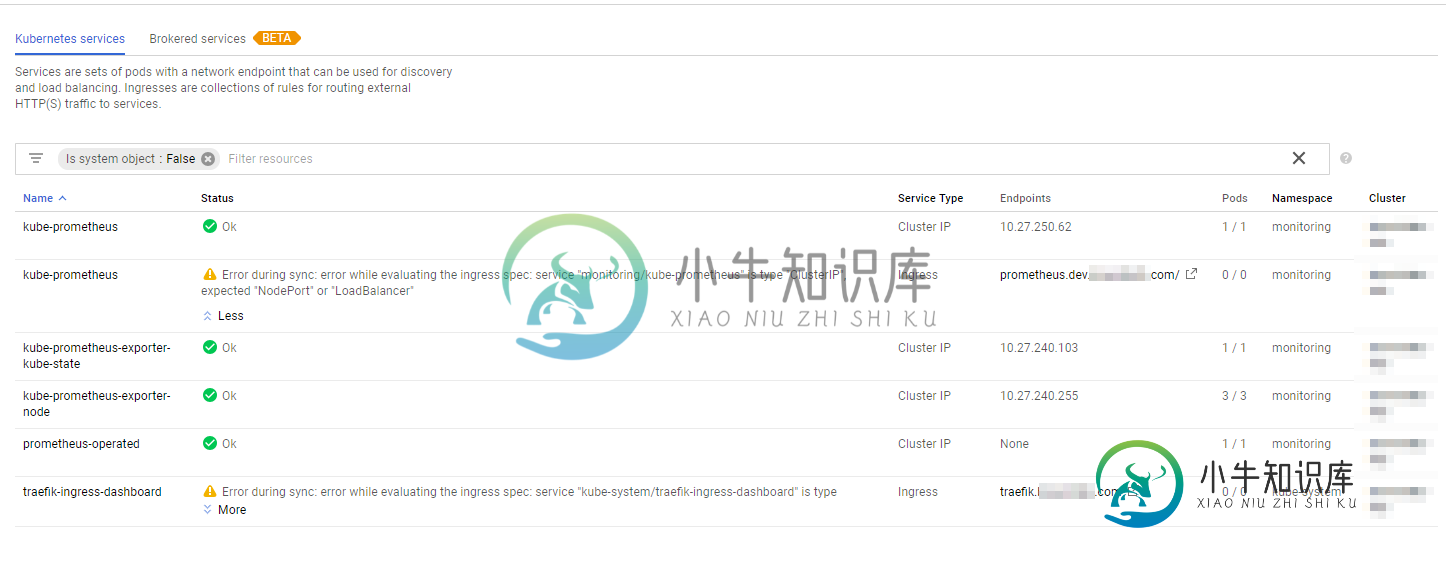 为什么谷歌云在使用ClusterIP时显示错误
为什么谷歌云在使用ClusterIP时显示错误在我的gcloud控制台中,我定义的入口显示以下错误: 同步期间出错:评估入口规范时出错:服务“monitoring/kube prometheus”类型为“ClusterIP”,应为“NodePort”或“LoadBalancer” 我使用traefik作为反向代理(而不是nginx),因此我使用集群IP定义入口。据我所知,所有流量都是通过traefik服务(定义了负载均衡器入口)代理的,因此我
-
使用Spring云配置重新启动HikariCP
我最近将我的应用程序配置为使用SpringCloudConfig和Github作为配置存储库。 Spring靴-2.1。1.发布 我的应用程序几乎使用了所有现成的东西。我刚刚在我有HikariCP自动配置在后台发挥神奇的作用。 我正在刷新我的应用程序使用这个作业,调用方法上的刷新endpoint。 一切似乎都很好,但每次刷新配置时,我都会看到以下日志。这些日志显示HikariCP池在每次刷新时都会
-
谷歌云数据流:如何初始化Hikari连接池每个工人只有一次(单例)?
Hibernate Utils正在创建带有Hikari配置的会话工厂。目前我们正在做@Setup方法的ParDo,但它打开了太多的连接。那么有没有什么好的例子来初始化每个工作人员的连接池呢?
-
Spring云总线和Spring for Apache Kafka有什么区别?
使用Spring for Apache Kafka或Spring AMQP,我可以实现消息发布/订阅。Spring云总线使用Kafka/rabbitmq来完成大致相同的事情,它们之间的区别是什么?
-
如何使用Spring Cloud stream集成Spring启动应用程序以IBMBluemix云上的事件流
Pom文件包含依赖项-spring cloud starter流kafka 控制器代码 问候听众类 问候语流接口 问候服务 问候课程 结合 主类 我能够使用属性文件中指定的以下配置连接、发送和接收消息到本地Kafka实例 但是,我无法连接到blue mix云上的IBM事件流。下面是我连接到云上事件流的配置 请让我知道配置有什么问题。我没有找到任何符合我要求的例子。
-
Spring云流:尝试暂停不支持可暂停bean的组件
我是Spring云流的新手。我使用的是我们团队成员之一写的活页夹。我使用执行器的/绑定endpoint暂停/恢复应用程序中的使用者。但我有个错误 问题1。我猜这是因为我使用的活页夹不支持暂停/恢复操作。有谁能给我举一些例子,在那里我可以找到如何将此功能添加到活页夹? Qn 2。我也使用执行器endpoint尝试启动/停止。停止工作正常,但在启动时,我得到了以下错误 是否有人可以提供一些关于此错误的
-
如何使用Kafka DSL对Spring云流进行单元测试
我正在尝试(单元)测试使用Kafka DSL的Spring Cloud Stream Kafka处理器,但收到以下错误“无法建立到节点1的连接。代理可能不可用。”。此外,测试不会停止。我尝试了EmbeddedKafka和TestBinder,但我有同样的行为。我试图从Spring Cloud团队(有效)给出的响应开始,我将应用程序改编为使用Kafka DSL,并将测试类保持原样。EmbeddedK
-
Spring云流Kafka:如何在生成Kafka主题的消息后访问Kafka头的recordMetadata
我想在生成一条发送给Kafka主题的消息后,获取偏移量和分区信息。我通读了spring cloud stream kafka绑定文档,发现这可以通过fecting RECORD\u元数据kafka头来实现。 来自Spring文档:(https://cloud.spring.io/spring-cloud-static/spring-cloud-stream-binder-kafka/3.0.0.R
-
Spring Cloud Stream Rabbit Binder,单消息源,具有分布在数据中心的云代工实例
我正在使用Spring Cloud stream发布者将分区的Rabbit MQ队列设置为30个分区。消费者部署在Cloud-oundry中。 这需要30个云铸造中的消费者应用程序实例,我想将这些实例分布到2个数据中心。所以我在一个数据中心启动了15个实例,在第二个数据中心启动了其他15个实例 我期望每个实例连接到0-29分区(一个分区得到一个实例),但2个实例(每个数据中心各一个)连接到0到14
-
集团财产不工作在春流云?
我使用Spring Stream云来消费Kafka上的消息。当Kafka上的信息产生时,所有的消费者都受到了冲击。 但Kafka的文献表明,通过使用群体,只有一个消费者消费信息。 这是我的消费代码。 这是我的配置,但我的两个方法都调用了:(