《七牛云》专题
-
避免在Beam Python SDK中重新计算所有云存储文件的大小
我正在开发一个从谷歌云存储(GCS)目录中读取约500万个文件的管道。我已经将其配置为在谷歌云数据流上运行。 问题是,当我启动管道时,需要花费数小时“计算”所有文件的大小: 如你所见,计算大约5.5M文件的大小需要一个半小时(5549秒),然后从头开始!又花了2个小时运行第二遍,然后又启动了第三遍!截至本文撰写之时,该作业在数据流控制台中仍然不可用,这使我相信这一切都发生在我的本地机器上,并且没有
-
谷歌云平台上Kafka/AWS动觉流的等效值
我正在构建一个应用程序,该应用程序不断附加到缓冲区,而许多阅读器独立地从该缓冲区中消费(写一次读多/WORM)。起初我想使用Apache Kafka,但由于我更喜欢即服务选项,我开始研究AWS Kinesis Streams KCL,似乎我可以用它们完成这项任务。 基本上,我需要两个特性:排序(所有读卡器必须以相同的顺序读取事件)和在缓冲区中选择读卡器开始消费的偏移量的能力。 现在我也在评估谷歌云
-
针对NRT数据应用程序的谷歌云数据流
我正在评估Kafka/Spark/HDFS开发NRT(sub-sec)java应用程序的能力,该应用程序从外部网关接收数据,并将其发布到桌面/移动客户端(消费者),用于各种主题。同时,数据将通过流式处理和批处理(持久性)管道传输,用于分析和ML。 例如,流将是。。。 独立的TCP客户端从外部TCP服务器读取流数据 客户端根据数据包(Kafka)发布不同主题的数据,并将其传递给流管道进行分析(Spa
-
如何在从datalab运行的数据流管道中使用google云存储
我们在datalab中运行了一个Python管道,它从google云存储(导入google.datalab.storage)中的存储桶中读取图像文件。最初我们使用DirectRunner,效果很好,但现在我们尝试使用DataflowRunner,并且出现导入错误。即使在管道运行的函数中包含“import google.datalab.storage”或其任何变体,也会出现错误,例如“没有名为'da
-
AVRO生成了pojo的Kafka Spring云模式注册表
我正在考虑使用模式来验证Kafka主题的数据。我正在结合apache kafka探索spring云模式注册表。 如果我在阅读文档后理解正确。Spring云模式注册表仅支持avro模式!在avro pojos中,需要使用类路径上的. avsc文件生成pojos,并且有一个maven插件可以完成所需的工作。 问题: 如果我的POJO上有这样的自定义验证呢?我不想在我的Kafka消费者中使用avro模式
-
Google云数据流使用什么java运行时?java8或java11
谷歌云数据流是基于ApacheBeam的。beam并不正式支持java11。但是当我在GCP上运行一个数据流作业并检查该作业作为工作线程使用的vm实例时。我发现容器映像是“gcr.io/cloud dataflow/v1beta3/beam-java11-batch:beam-2.23.0”。那么,在运行数据流时,数据流是否使用java11作为java运行时?为什么不使用java8?是否存在bug
-
如何运行Python谷歌云数据流作业与自定义Docker图像?
我想运行一个Python谷歌云数据流作业与自定义Docker图像。 根据文件,这应该是可能的:https://beam.apache.org/documentation/runtime/environments/#testing-自定义图像 为了尝试此功能,我使用此公共repo中的文档中的命令行选项设置了基本wordcount示例管道https://github.com/swartchris8/b
-
使用docker解决google云数据流依赖
我对使用谷歌云数据流并行处理视频感兴趣。我的工作同时使用OpenCV和tensorflow。是否可以只在docker实例中运行worker,而不按照以下说明从源安装所有依赖项: https://cloud.google.com/dataflow/pipelines/dependencies-python 我本以为docker容器会有一个标志,它已经位于google容器引擎中。
-
谷歌云数据流工作者的自定义虚拟机映像
浏览了Google云数据流文档后,我的印象是worker VM运行一个特定的预定义Python 2.7环境,没有任何改变的选项。是否可以为工作人员提供自定义VM映像(使用库、特定应用程序需要的外部命令构建)。可以在Gcloud数据流上运行Python 3吗?
-
谷歌云数据流实例的图像
当我运行Dataflow作业时,它会将我的小程序包(setup.py或requirements.txt)上传到Dataflow实例上运行。 但是数据流实例上实际运行的是什么?我最近收到了一个stacktrace: 但从理论上讲,如果我在做,这意味着我可能没有运行这个Python补丁?你能指出这些作业正在运行的docker图像吗,这样我就可以知道我使用的是哪一版本的Python,并确保我没有在这里找
-
如何从云端恢复中检索自定义对象?
我正在尝试将我的实时数据库调整为一个聊天应用程序的云firestore。存储的对象是我创建的Message类。我希望邮件成为文档。 我的RecyclerView适配器将使用实时数据库这样检索它们: 下面是我如何开始用Firestore重新创建它的。如何在快照侦听器的OneEvent方法中将快照转换回消息?
-
如何将JSON导入云Firestore
我目前正在使用Firebase实时数据库。我已经将JSON导入实时数据库,但由于查询的限制,我需要打开Firebase Firestore。 我想将JSON导入Firebase的云Firestore。
-
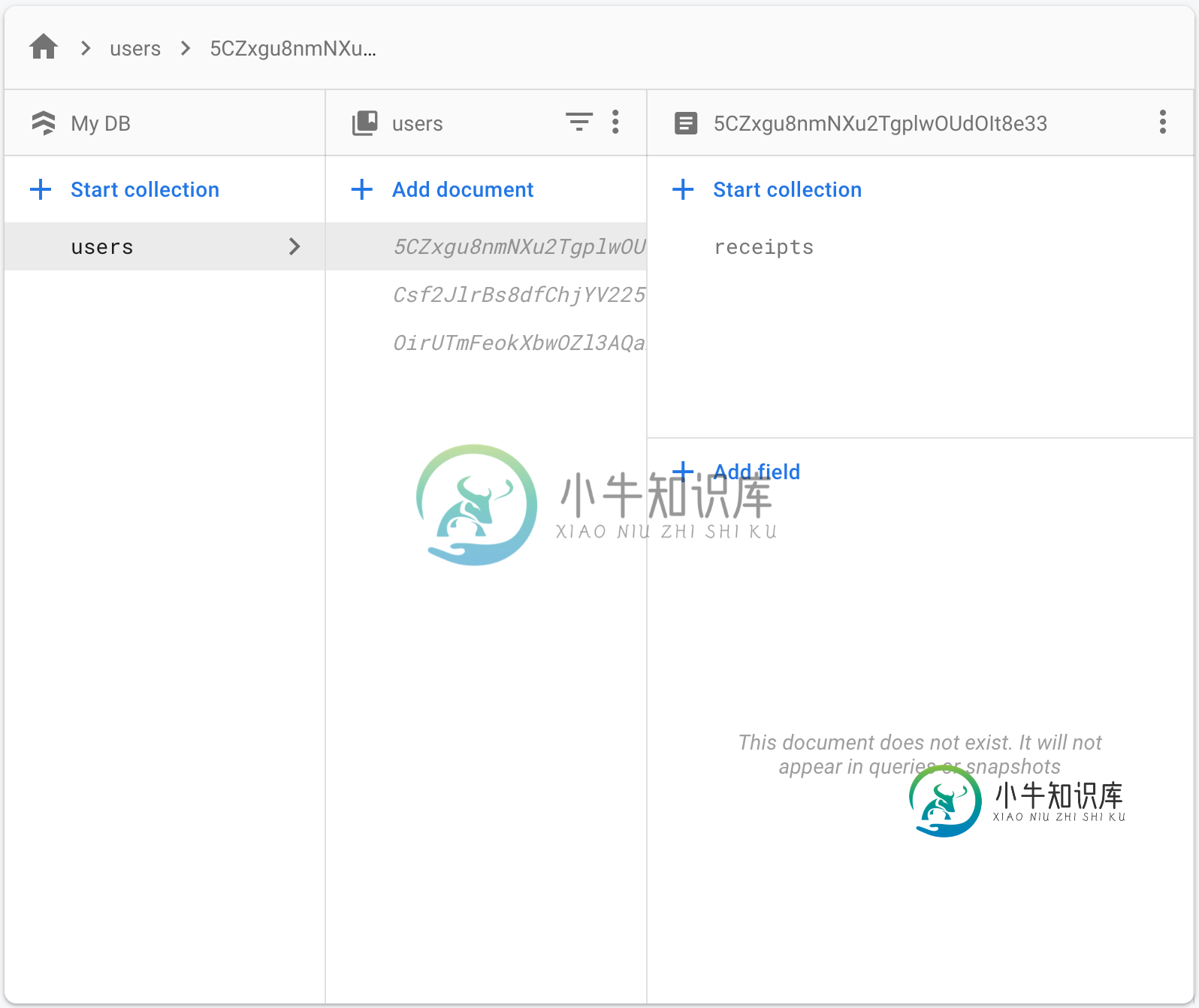 Firestore云函数空集合
Firestore云函数空集合我有一个困扰我好几天的问题。我正在尝试创建一个从Firestore数据库读取的Firebase云函数。 我的Firestore DB如下所示: 问题是我无法像这样列出: 如果我尝试这样做,我会得到空响应,就像我的集合中没有用户一样。 但我尝试直接访问用户它可以工作: 我的完整代码: 有人知道我做错了什么吗?非常感谢。
-
在云Firestore中使用Firebase实时数据库节点密钥作为文档ID
我正在将我的实时数据库迁移到Cloud FiRecovery。理想情况下,我需要保留使用生成的相同实时数据库节点密钥,并将其用作FiRecovery中的文档ID,但这样做安全吗? 我已经阅读了https://firebase.google.com/docs/firestore/best-practices的信息,我仍然不确定这是否安全。我知道Cloud FiRecovery中自动生成的文档ID与实
-
云火:在实时侦听器上,即使没有变化也会收取读取费用?
我想要一些关于实时监听器定价的解释。 在Firestore文档上(https://firebase.google.com/docs/firestore/pricing)声明如下: 如果侦听器断开连接的时间超过30分钟(例如,如果用户脱机),您将被收取阅读费用,就像您发出了一个全新的查询一样。 如果没有任何更改(无论是本地更改还是远程更改),该怎么办。在30分钟后重新连接时,您是否仍会因阅读而收取费