《兴业证券》专题
-
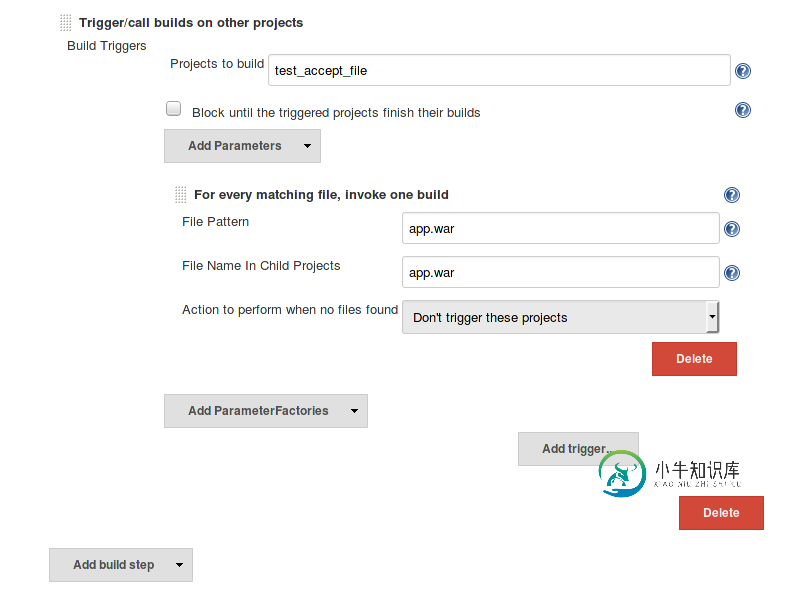 如何将文件传递到阻止上游作业的下游作业?
如何将文件传递到阻止上游作业的下游作业?问题内容: 我要完成的工作是从分支中签出代码,将其合并到分支,构建,运行测试,如果测试成功则推送到分支。 测试应在需要的单独工作中运行。 我当前的设置如下: Job 从中检出,将其合并并构建 作业会在“ 后期制作”步骤中 触发作业(需要预先创建) 如果成功,则在 发布构建操作中推送到分支 __ 我尝试使用 Copy Artifact Plugin, 但是问题在于,在 Post构建步骤中 触发时,我
-
是否可以将Jenkins自由式作业转换为多配置作业?
问题内容: 我在詹金斯(Jenkins)有很多自由式工作,我想转换为多配置工作,这样我就可以在一项工作下跨多个平台进行构建。这些作业指定了很多构建参数,我不想通过创建新的多配置作业来再次手动设置它们。当前,每个作业都将其构建限制为我们一直在构建的平台,而我看到的唯一其他选择是克隆现有作业,并将限制更改为新平台。这不是理想的选择,因为我需要维护2个工作,其中唯一的区别是目标平台。 我没有看到通过UI
-
Jenkins executor忙-加载条作业,但没有链接或id-幽灵作业
Jenkins重启后,我们发现很少有节点执行器繁忙。占据executor的作业有条带的蓝白加载条,并且没有链接到任何特定的构建(事实上,该作业没有正在进行的构建)。所以我们没有id或ui方式来中止它,您可以在这里看到: 詹金斯节点上的工作是什么样子的 现在,我想找到一种方法,在不真正调查问题原因的情况下杀死它,也许它与Jenkins管道作业相关,不会在UI中完成——但在我们的情况下,我们没有基本的
-
Spring Batch Admin现有作业在新作业注册后不再可启动
目前,由于一个我无法解决的问题,我一直在将Spring Batch Admin(SBA)集成到我们的项目中。希望有人能给我一个建议。 我们使用了示例SBA应用程序(Github的当前版本),只添加了一个Tasklet。我通过/job配置上传Spring批处理描述(XMLs)。SBA的json API使用。这工作正常。在SBA的HTML页面中,我看到该作业已注册并可启动。它可以通过API(/jobs
-
Azure Web作业未启动并始终给出“未找到作业功能”
我正在尝试使用触发器运行Azure网络作业,但我的时间作业方法没有触发。我收到了下面的消息。 未找到工作职能。尝试将您的作业类和方法公开化。如果您正在使用绑定扩展(例如ServiceBus、定时器等。)确保您已经在启动代码中调用了扩展的注册方法(例如config。UseServiceBus()、config。使用定时器()等。). 我正在使用配置。UseTimers() 但仍显示消息。不确定以下代
-
在Jenkins中将作业A的工作空间url传递给作业B
我有两个管道作业作业作业A和作业B。我需要通过作业A的工作空间url(比如 /var/lib/jenkins/workspace/JobA)被作业B使用。主要的想法是我试图复制由于maven构建而生成的目标文件夹的内容,但我不想使用复制工件插件或存档工件插件来实现同样的目的。 我尝试过使用“此作业已参数化”选项,其中作业A是作业B的上游,但我无法使用该选项。 有人能帮助实现同样的目标吗?
-
如何在作业结束时运行脚本,即使作业被取消?
这是我目前在GitHub上使用的工作流程 我有一台windows 10计算机,它使用GitHub runner监听传入的作业。在传入作业时,如果正在向主分支推送脚本ci_主机。py使用“--master”标志运行,该标志会启动一个VM并对其运行多个测试。最终,在测试结束时,脚本将VM恢复到预先配置的快照。 因此,基本上我试图实现的是,当通过GitHub操作web界面取消作业时,处理测试的脚本在作业
-
如何从数据流作业内部获取数据流作业 ID - JAVA
在我当前的架构中,多个数据流作业在不同阶段被触发,作为ABC框架的一部分,我需要捕获这些作业的作业id作为数据流管道中的审计指标,并在BigQuery中更新它。 如何使用JAVA从管道中获取数据流作业的运行id?有没有我可以使用的现有方法,或者我是否需要在管道中使用google cloud的客户端库?
-
如何使一个石英作业创建另一个作业后执行?
我想用Quartz实现下面的算法,但不确定是否可以做到。这是我第一次尝试使用石英。 用户通知作业-此作业计算每月报告并向用户发送电子邮件,它需要用户id和用于生成自定义用户报告的其他参数 可能需要生成10,000多个这样的报告 null 如何确保每月作业在单个事务中执行,以便识别所有需要每月报告的用户,并安排作业通知他们 如何立即安排作业在创建它们的作业之后立即执行? 我用的是Spring 3.2
-
部署 Seafile 专业版服务器 - 从社区版迁移至专业版
限制条件" class="reference-link">限制条件 您可能已经部署过 Seafile 社区版服务器,并想要切换到专业版,或者反过来从专业版迁移到社区版。但是有一些限制条件需要您注意: 您只能在相同大版本的社区版服务器和专业版服务器之间进行切换。 这意味着,如果您正在使用 2.0 版本的社区版服务器, 并且想要切换到 2.1 版本的专业版服务器,您必须先将您的社区版服务器升级到 2.
-
flask验证式RequestParser的嵌套验证
问题内容: 使用flask式的微框架,我很难构建一个RequestParser可以验证嵌套资源的。假设期望的JSON资源格式为: 中的每个项目都对应一个对象: …然后使用如下形式创建一个: …但是你将如何验证其中MyObject每个字典的嵌套?或者,这是错误的方法吗? 与此对应的API MyObject本质上将每个对象视为对象文字,并且可能有一个或多个传递给服务;因此,在这种情况下,拼合资源格式将
-
Linux RPM包验证和数字证书
主要内容:Linux RPM 包校验,Linux RPM数字证书验证执行 命令可以看到,Linux 系统中装有大量的 RPM 包,且每个包都含有大量的安装文件。因此,为了能够及时发现文件误删、误修改文件数据、恶意篡改文件内容等问题,Linux 提供了以下两种监控(检测)方式: RPM 包校验:其实就是将已安装文件和 /var/lib/rpm/ 目录下的数据库内容进行比较,确定文件内容是否被修改。 RPM 包数字证书校验:用来校验 RPM 包本身是否被修改。 L
-
无法验证的SSL证书https://rubygems.org/
我在运行
-
在PHP SoapClient中禁用证书验证
问题内容: 简介: 有没有一种方法可以强制PHP中的内置SoapClient-class通过HTTPS连接到具有无效证书的服务器? 我为什么要这样做? 我已经在没有DNS条目或证书的服务器上部署了新应用程序。我想 在 设置DNS条目和修复证书 之前 尝试使用SoapClient连接到它,而最合理的方法似乎是使客户端在测试过程中忽略证书。 我是否没有意识到这是巨大的安全风险? 这仅用于测试。服务投入
-
facebook错误“验证码验证错误”
问题内容: 非常奇怪的错误。我使用的是http://developers.facebook.com/docs/authentication/。所以我创建了对fb的请求并传递redirect_uri。我在本地主机上使用测试站点。所以如果我通过 redirect_uri = http://localhost/test_blog/index.php 它工作正常,但如果我通过 redirect_uri =