《字节跳动内推》专题
-
对于一个字节块,HTTP“内容类型”是什么?
当响应客户端的GET请求返回字节块时,要使用什么HTTP“内容类型”? 在本例中,信息负载是使用Python的Pickle库序列化的对象。
-
Java 中字节数组的内存使用情况 [重复]
对于启发式预计算表,我需要一个包含1504935936个条目的字节数组。这大约需要1.5 GB内存。 为什么我有一个“内存不足错误:Java堆空间”-例外,如果我给程序2 GB的RAM 与 它起作用了。为什么它需要那么多RAM?
-
通过套接字Java发送字节数组、字符串和字节
我需要通过Java socket发送一个文本消息到服务器,然后发送一个字节数组,然后是一个字符串等等。到目前为止,我所开发的内容还在工作,但客户端只读取发送的第一个字符串。 从服务器端:我使用发送字节数组,使用发送字符串。 问题是客户机和服务器不同步,我的意思是服务器发送字符串然后字节数组然后字符串,而不等待客户机消耗每个需要的字节。 我的意思是情况不是这样的:
-
从字节数组中删除前16个字节
问题内容: 在Java中,如何获取byte []数组并从数组中删除前16个字节?我知道我可能必须通过将阵列复制到新阵列中来执行此操作。任何例子或帮助将不胜感激。 问题答案: 参见Java库中的类:
-
字节vs字节数组在Python 2.6和3中
问题内容: 我正在Python中测试vs。我不明白某些差异的原因。 一个迭代器返回的字符串: 给出: 但是迭代器返回s: 给出: 为什么会有所不同? 我想编写可以很好地转换为Python 3的代码。那么,Python 3中的情况是否相同? 问题答案: 在Python中,2.6字节只是str的别名 。 引入此“伪类型”是为了(部分地)准备要与Python 3.0转换/兼容的程序(和程序员!),在Py
-
 字节 字节云 测试开发 面经 社招
字节 字节云 测试开发 面经 社招部门:字节云 岗位:测试开发 社招 3年 有点紧张 流程 1自我介绍 2你未来岗位有啥要求?(给我问懵逼了)为啥想要离职? 3以下问题偏测试(没问项目,可能项目差异太大了) 如何提升产品质量之类 你负责的产品质量怎么样 自动化有啥好处? 4编程语言python 你知道哪些类型 dict是怎么实现的 5做一个SQL题,大概用子查询吧 6编程题,最长回文子串 7你的优势,劣势 许愿,梦想还是
-
jupyterlab互动情节
问题内容: 我正在使用Jupyter笔记本中的Jupyterlab。在我以前使用的笔记本中: 用于交互式地块。现在给我(在jupyterlab中): 我还尝试了魔术(安装了jupyter-matplotlib): 但这只是返回: 内联图 工作正常,但我想要交互式地块。 问题答案: 完成步骤 1. 安装nodejs,例如。 2. 安装ipympl,例如。 3. [可选,但推荐;更新JupyterLa
-
Symfony 3 PHP致命错误:允许的内存大小X字节已用尽(尝试分配Y字节)
尝试使用命令生成数据库时: 我发现以下错误: PHP致命错误:第281行的…\vendor\doctor\orm\lib\doctor\orm\EntityManager.PHP中允许的内存大小为1073741824字节(尝试分配262144字节) 致命错误:允许的内存大小1073741824字节耗尽(试图分配262144字节)在...\供应商\原则\orm\lib\原则\ORM\EntityMa
-
PHP警告:第0行中未知的帖子内容长度8978294字节超过8388608字节的限制
在我的XAMPP本地开发环境中尝试在WordPress上上载导入时,我遇到此错误: 警告:第0行中未知的帖子内容长度8978294字节超过8388608字节的限制 我将从更改为,但这似乎没有任何作用。 有什么想法吗?
-
使用UTF8编码的json,“要写入流的字节超过指定的内容长度字节大小”
在向Mandrill API发送JSON对象时,我面临编码问题。在使用UTF8编码写入流写器时,会引发以下异常: “要写入流的字节超过了指定的内容长度字节大小。”紧接着:“在写入所有字节之前无法关闭流。” 这是用于发送JSON对象的代码部分: 在我看来,这个错误与UTF8中的字节长度有关,但即使我将httpWebRequest加倍。ContentLength值我仍然会得到相同的错误。
-
PHPExcel抛出致命错误:允许的内存大小134217728字节已用尽(尝试分配71字节)
我正在使用PHPExcel(在这里找到:https://github.com/PHPOffice/PHPExcel)。如果我尝试读取超过大约2000行,然后它显示内存错误如下。 致命错误:第89行的/home/sample/PHPExcelReader/Classes/PHPExcel/sheetwork.php中允许的134217728字节内存已耗尽(尝试分配71字节) 我的Excel数据范围是
-
 字节 国际化搜索运营-推荐内容安全 社招一面
字节 国际化搜索运营-推荐内容安全 社招一面听说在牛客许愿很灵# 双非一本,硕211+海外硕,3年工作经验 自我介绍 1、就我曾经工作内容提问,细问了内容安全的时效、特殊标签规则?谁制定?如何制定?外包有多少人?负责绩效制定吗?规则如何同步给外包?如果让你来制定tiktok的特殊标签,你怎么定? 2、介绍组内情况,设问你负责10国多语种的烟酒内容的安全准则制定,你会怎么制定传达? 3、app个性化推荐,我们和算法怎么合作,各负责哪块?分发逻
-
了解Java字节
问题内容: 因此,在昨天的工作中,我不得不编写一个应用程序来计算AFP文件中的页数。因此,我整理了我的MO:DCA规范PDF,找到了结构化字段及其3个字节的标识符。该应用程序需要在AIX机器上运行,所以我决定用Java编写它。 为了获得最大效率,我决定读取每个结构化字段的前6个字节,然后跳过该字段中的其余字节。这会让我: 因此,我检查字段类型,如果是,则增加页面计数器,如果不是,则不增加。然后,我
-
Concat字节数组
问题内容: 有人可以指出以下更有效的版本吗 每个变量都是一个字节片,大小不一 : 码: : 基准测试结果: 问题答案: 如果已经分配了内存,则x = append(x,a …)的序列在Go中非常有效。 在您的示例中,初始分配(制造)的成本可能比附加序列的成本高。这取决于字段的大小。考虑以下基准: 在我的盒子上,结果是: 系统地重新分配缓冲区(甚至是很小的缓冲区)会使此基准测试速度至少慢5倍。 因此
-
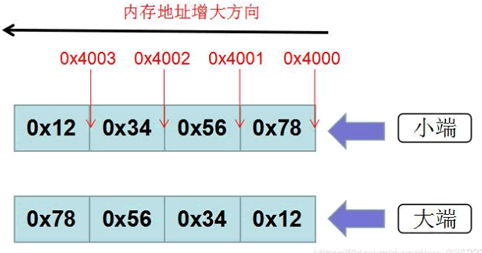 NumPy字节交换
NumPy字节交换主要内容:numpy.ndarray.byteswap()数据以字节的形式存储在计算机内存中,而存储规则可分为两类,即小端字节序与大端字节序。 小端字节序(little-endian),表示低位字节排放在内存的低地址端,高位字节排放在高地址段,它与大端字节序(big-endian)恰好相反。 对于二进制数 0x12345678,假设从地址 0x4000 开始存放,在大端和小端模式下,它们的字节排列顺序,如下所示: 图1:字节存储模式 小端存储后:0x