《兴盛优选》专题
-
寻求异步与/for的优点的解释
我不熟悉asyncio。我遇到了所有文件(https://github.com/Tinche/aiofiles)最近,在文档中看到它支持“async with”和“async for”我想了解它,但除了PEP 492没有太多细节外,没有太多好的报道。 PEP 492相关部分的快捷方式: https://www.python.org/dev/peps/pep-0492/#asynchronous-c
-
Nodejs异步回调的优雅处理方法
本文向大家介绍Nodejs异步回调的优雅处理方法,包括了Nodejs异步回调的优雅处理方法的使用技巧和注意事项,需要的朋友参考一下 前言 Nodejs最大的亮点就在于事件驱动, 非阻塞I/O 模型,这使得Nodejs具有很强的并发处理能力,非常适合编写网络应用。在Nodejs中大部分的I/O操作几乎都是异步的,也就是我们处理I/O的操作结果基本上都需要在回调函数中处理,比如下面的这个读取文件内容的
-
Vue SPA单页应用首屏优化实践
本文向大家介绍Vue SPA单页应用首屏优化实践,包括了Vue SPA单页应用首屏优化实践的使用技巧和注意事项,需要的朋友参考一下 1.代码压缩(gzip) 如果你用的是nginx服务器,请修改配置文件(其他web server 类似):sudo nano /etc/nginx/nginx.conf 在Gzip Settings里加入: gzip 开启或者关闭 gzip 模块,这里使用 on 表示
-
docker容器如何优雅的终止详解
本文向大家介绍docker容器如何优雅的终止详解,包括了docker容器如何优雅的终止详解的使用技巧和注意事项,需要的朋友参考一下 前言 在Docker大行其道的今天,我们能够非常方便的使用容器打包我们的应用程序,并且将它在我们的服务器上部署并运行起来。但是,谈论到如何停掉运行中的docker容器并正确的终止其中的程序,这就成为一个非常值得讨论的话题了。 事实上,在我们日常的项目当中,这是我们经常
-
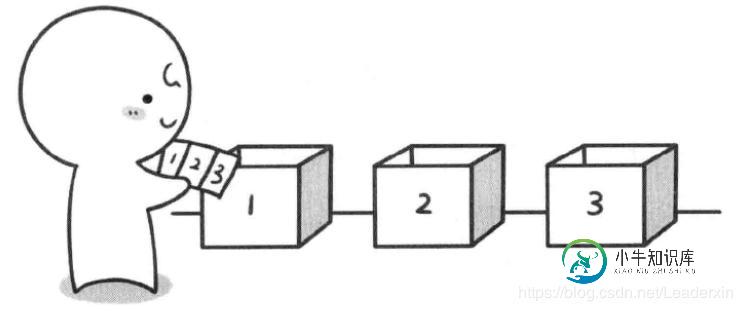 C#深度优先遍历实现全排列
C#深度优先遍历实现全排列本文向大家介绍C#深度优先遍历实现全排列,包括了C#深度优先遍历实现全排列的使用技巧和注意事项,需要的朋友参考一下 假如让你说出123三个数字的全排列你可以很快说出来123,132,213,231,312,321,但是让你说出1~20总共20个数字的全排列是不是就没那么简单了呢?本篇我们就通过C#运用深度优先算法实现全排列 算法图例 假如有编号为1,2,3的三张扑克牌和编号为1,2,3的三个盒子,
-
与ngResource相比,使用Restangular有什么优势?
问题内容: 用…实现事情 似乎 已经 很简单 了… 与 ngResource相比 ,使用Restangular 有哪些优点/缺点? 1.1.3 将返回承诺,并且可以使用[最新的PRcommit来实现。将来会提供支持来支持Restangular所做的其他动词吗?如果发生这种情况,Restangular似乎将消失并变得不耐烦。 问题答案: 我是Restangular的创建者。 我已经在自述文件中创建了
-
 浅谈Vue SPA 首屏加载优化实践
浅谈Vue SPA 首屏加载优化实践本文向大家介绍浅谈Vue SPA 首屏加载优化实践,包括了浅谈Vue SPA 首屏加载优化实践的使用技巧和注意事项,需要的朋友参考一下 写在前面 本文记录笔者在Vue SPA项目首屏加载优化过程中遇到的一些坑及优化方案! 我们以 vue-cli 工具为例,使用 vue-router 搭建SPA应用,UI框架选用 element-ui , ajax方案选用 axios, 并引入vuex ,使用 vu
-
浅谈JS运算符&&和|| 及其优先级
本文向大家介绍浅谈JS运算符&&和|| 及其优先级,包括了浅谈JS运算符&&和|| 及其优先级的使用技巧和注意事项,需要的朋友参考一下 今天看了一段YUI compressor压缩的js代码: userNum && (ind += index,ind >= userNum && (ind -= userNum),ind < 0 && (ind === -2 && (ind = -1),ind +=
-
实例分析ORACLE数据库性能优化
本文向大家介绍实例分析ORACLE数据库性能优化,包括了实例分析ORACLE数据库性能优化的使用技巧和注意事项,需要的朋友参考一下 ORACLE数据库的优化方式和MYSQL等很大的区别,今天通过一个ORACLE数据库实例从表格、数据等各个方便分析了如何进行ORACLE数据库的优化。 tsfree.sql视图 这个sql语句迅速的对每一个表空间中的空间总量与每一个表空间中可用的空间的总量进行比较 表
-
Gekko非线性优化,目标函数误差
函数“def gekko_obj(x)”适用于任何x值。 但是,当m作为Gekko目标函数调用时,它会失败。Obj(gekko_obj(x))。 文件“/anaconda3/lib/python3.6/site packages/spyder/utils/site/sitecustomize.py”,第710行,在runfile execfile(文件名,命名空间)中 文件“/anaconda3/
-
1000万数据的Spark性能调优配置
我们正在以下硬件上运行用JAVA编写的SPARK应用程序: 一个主节点 两个Worker节点(每个节点都有502.5 GB可用内存和88个内核(CPU))。 具有以下<代码>配置/spark submit命令: --执行器内存=30GB--驱动程序内存=20G--执行器内核=5--驱动程序内核=5 我们正在使用SPARK集群管理器。 处理1000万个数据需要13分钟。 我们无权共享应用程序代码。
-
垃圾收集器优先和JMap EOF错误
我们正在客户端的正式服堆上工作,以检测和解决内存泄漏。为此,我们定期使用jmap来收集必要的信息。 但上周我们无法进行转储,因为它触发了一个EOF错误并关闭了Tomcat实例。 我在网上搜索了一下,但找不到关于这个错误的任何具体信息。我们检测到,只有在使用Gc-First垃圾收集器算法时才会发生这种情况。 这是我们用来执行jmap的命令行: jmap文件heap.bin 服务器上的Java版本:J
-
php中的数组声明,优缺点[重复]
到目前为止,我还没有找到任何直接的解释。我找到了两种声明数组的方法。我基本上已经习惯了 然而,我发现了另一种方法: 为什么有人会使用第二种选择而不是第一种。在内存分配方面有什么不同吗?
-
Mysql优化:有没有办法让它更快?
更新: 谢谢所有的帮助。我将总结一下答案。 从@Jayde开始,他的回答成功地将结果减少到0.09秒,并且与限制中的数字成线性关系。 选择*from(选择table1.id作为table1\u id,从table1中选择table1.id 在@Rick James中,他提到这可能是表2的问题。因为我的表2只有几列,所以我可以省略它,自己进行连接,即使是在客户端! 所以我去掉了表2,它只有0.02s
-
如何优化二维矩阵读取速度?
我正在做一个2D游戏。我把游戏地图保存在一个名为gameMap的js对象{}上。我的问题是读取矩阵上的一个项目需要太长时间。对于冲突检测,我通常必须检查地图矩阵的10或20个项目,大约需要1ms,屏幕上有10个字符冲突检测成为应用程序的瓶颈,每帧应该持续16ms中的10ms。此外,当地图变得太大时,按比例放大。 假设地图有1000 x 1000个项目。现在,如果我想检查什么是在位置我检查。我的想法