《求职交流聚集地》专题
-
Python数组并集交集补集代码实例
本文向大家介绍Python数组并集交集补集代码实例,包括了Python数组并集交集补集代码实例的使用技巧和注意事项,需要的朋友参考一下 这篇文章主要介绍了Python数组并集交集补集代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 并集 打印结果: 交集 打印结果: 补集 打印结果: 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望
-
Spring集成子集和Spring子集交互问题
我创建了一个新示例,并将代码分为客户端和服务器端。 完整的代码可以在这里找到。 服务器端有3个版本。 服务器无Spring Boot应用程序,使用Spring Integration RSocket InboundGateway 服务器引导重用Spring RSocket autconfiguration,并通过serverrsocketmessagehandler创建ServerRSocketC
-
采集帮助 - 了解采集 - 采集流程
采集流程: 采集一般可以分为3个过程:1.设置采集规则;2.采集数据内容;3.导出内容,这3个内容是可以独立分开来的。 设置采集规则:这个就是在操作中的添加采集节点,并对这个节点规则进行设置,比如:设置采集内容列表的地址、指定采集标题或者内容的位置(规则)、设置采集内容过滤规则。这个规则是采集最根本最基础的东西,采集规则可以导入导出,方便对这个采集规则进行分享。 采集数据内容:根据不同情况对数据采
-
本地上的交叉源请求
我正在尝试一些非常简单的方法,但由于某些原因它不起作用: 启动index.html时出现的错误: 无法加载文件:///e:/dev/eclipse/syrilab/pages/header.html:跨源请求仅支持协议方案:http、data、chrome、chrome-extension、HTTPS。 无法加载文件:///e:/dev/eclipse/syrilab/pages/home.htm
-
JSON字符串的交集
问题内容: 我正在尝试找到一种方法来将一个JSON字符串用作各种“模板”以应用于另一个JSON字符串。例如,如果我的模板如下所示: 然后将其应用于以下JSON字符串: 我想要如下所示的结果JSON字符串: 不幸的是,我既不能依赖模板也不可以是固定格式的输入,因此我无法编组/解组到已定义的接口中。 我已经编写了一个遍历模板的递归函数,以构造一个带有每个要包含的节点名称的字符串切片。 我称这个函数如下
-
Elasticsearch日期范围交集
问题内容: 我在elasticsearch中存储以下信息: 假设我还有另一个日期范围(例如,从用户输入中得出),我想搜索一个相交的时间范围。与此类似:确定两个日期范围是否重叠这概述了以下逻辑: 但是我不确定如何将其放入elasticsearch查询中,我会使用范围过滤器并且仅将“ to”值设置为,而将from留为空白吗?还是有一种更有效的方法? 问题答案: 更新:现在可以使用在elasticsea
-
MongoDB中的数组交集
好吧,这里有几件事。。我有两个集合:test和test1。这两个集合中的文档都有一个数组字段(分别是tags和tags1),其中包含一些标记。我需要找到这些标记的交叉点,如果单个标记匹配,还需要从集合test1获取整个文档。 令人惊讶的是,这并没有返回任何结果。但是,当我尝试使用单个文档时,它是有效的: 但这是我需要的一部分。我也需要交集。所以我尝试了这个: 但它只返回“a”,而“a”和“b”都在
-
Hadoop 集成 - spark streaming交互
Apache Spark 是一个高性能集群计算框架,其中 Spark Streaming 作为实时批处理组件,因为其简单易上手的特性深受喜爱。在 es-hadoop 2.1.0 版本之后,也新增了对 Spark 的支持,使得结合 ES 和 Spark 成为可能。 目前最新版本的 es-hadoop 是 2.1.0-Beta4。安装如下: wget http://d3kbcqa49mib13.clo
-
similarity - 获取数组交集
返回存在于两个数组中的元素数组。 使用 Array.filter() 移除不在 values 中的值,使用 Array.includes() 确定。 const similarity = (arr, values) => arr.filter(v => values.includes(v)); similarity([1, 2, 3], [1, 2, 4]); // [1,2]
-
Java流收集到Map
我使用的是java 11,我有一个名为MyObject的对象列表,看起来像这样 我想使用流将这些对象收集到地图中 我试着用收集器来做。toMap(),但似乎不可能做到这一点 我的问题是可以制作一张地图吗
-
收集的实施。流()
我已经在JDK 1.8上工作了几天,遇到了一些类似的代码: 现在,对于一直在使用流()的人来说,它可能看起来既简单又干净,但我找不到实现方法的实际类。 当我说列表时,我有以下问题。流(): 我从哪里获取? 他们是如何在不实际“干扰”现有集合的情况下实现它的?(假设他们没有接触它们) 我确实试着浏览了java的文档。util。AbstractCollection和java。util。Abstract
-
集中式工作流
Centralized Workflow。项目的所有协作者把对项目的修改推送到统一的远程仓库,这就是集中式工作流。其它的 Git 工作流基本都是基于这种工作流程做了一些扩展。 项目的发起者在自己电脑上创建了一个本地仓库,他又为项目在远程创建了一个仓库,这个远程仓库就是所有协作者要把提交推送到的地方。这个远程仓库在谁家那创建都无所谓,可以用 Github,Coding.net,阿里云 Code,也可
-
监控集成流程
此章节针对于网聚宝业务监控集成流程作出说明。 主要内容包含: 添加依赖: 在 pom.xml 中引入 网聚宝监控客户端 的依赖。 dubbo.xml 配置: 在 dubbo 配置的 xml 文件下引入监控配置。 log4j 配置: 在 log4j.xml 中加入 监控的日志输出位置。 异常捕获方法调用: 在启动入口(main 函数)中加入方法调用。 (数据层)MyBatis plugin 配置:
-
两个或更多排序集的交集
问题内容: 我有两个排序集,并且想要进行交集,即。 关于效率,是否有比以下更好的方法: 问题答案: 您应该先使用ZCARD检查哪些元素较少,然后克隆并修剪较短的元素。 其次,您将剩下2个剩菜。您可以重复使用同一辅助程序,以加快清除速度。 我还想建议克隆使用DUMP和RESTORE,但是对于排序集的情况,ZUNIONSTORE实际上要快得多。这是一个100万个元素集的时间安排:
-
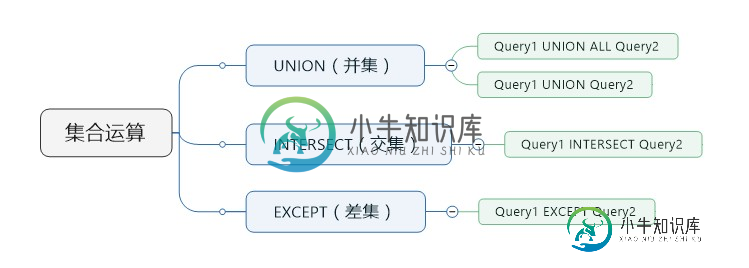 sql server 交集,差集的用法详解
sql server 交集,差集的用法详解本文向大家介绍sql server 交集,差集的用法详解,包括了sql server 交集,差集的用法详解的使用技巧和注意事项,需要的朋友参考一下 概述 为什么使用集合运算: 在集合运算中比联接查询和EXISTS/NOT EXISTS更方便。 并集运算(UNION) 并集:两个集合的并集是一个包含集合A和B中所有元素的集合。 在T-SQL中。UNION集合运算可以将两个输入查询的结果组合成一个