
python - 这段代码为什么不能获取到数据?

from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
import time
# 设置 ChromeDriver
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 如果不想看到浏览器界面,启用headless模式
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
# 打开目标网站
url = 'https://www.us168168.com/#/houseRentingDetails?id=1860134671530127362'
driver.get(url)
# 等待动态内容加载
time.sleep(15) # 可以根据具体的页面加载时间调整
# 查找需要的元素
content = driver.find_element(By.TAG_NAME, "body").text # 获取页面的文本内容
print(content)
# 关闭浏览器
driver.quit()
共有1个答案

前提安装这些模块
1.selenium: 用于控制浏览器。
2.webdriver_manager: 用于自动下载和管理 ChromeDriver。
目前我重新写的代码
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import logging
# 配置日志
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")
def initialize_driver():
"""初始化Chrome浏览器驱动并返回实例。"""
options = webdriver.ChromeOptions()
options.add_argument('--disable-gpu')
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36")
return webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
def wait_for_page_load(driver, timeout=60):
"""等待页面完全加载"""
WebDriverWait(driver, timeout).until(
lambda d: d.execute_script('return document.readyState') == 'complete'
)
def scrape_content(driver, url, css_selector, timeout=20):
"""访问目标URL并抓取指定CSS选择器的内容。"""
try:
logging.info(f"正在访问 {url}")
driver.get(url)
# 等待页面加载完成
wait_for_page_load(driver)
logging.info(f"页面加载完成,当前页面 URL: {driver.current_url}")
# 检查是否重定向到错误的 URL
if driver.current_url == "data:,":
raise Exception("页面加载失败,URL 显示为 data:,")
# 等待目标元素加载并获取文本内容
element = WebDriverWait(driver, timeout).until(
EC.presence_of_element_located((By.CSS_SELECTOR, css_selector))
)
return element.text
except Exception as e:
logging.error(f"发生错误: {e}", exc_info=True)
return None
if __name__ == "__main__":
driver = None
try:
# 初始化浏览器驱动
driver = initialize_driver()
# 目标URL和CSS选择器
url = 'https://www.us168168.com/#/houseRentingDetails?id=1491098005497819137'
css_selector = "div.title"
# 抓取内容
content = scrape_content(driver, url, css_selector)
if content:
print("抓取到的内容:", content)
else:
print("未能抓取到内容")
finally:
if driver:
driver.quit()
logging.info("浏览器已关闭")运行结果
会打开一个浏览器窗口,然后正常加载页面,到获取数据那一步就空了,是不是目标网站做了防爬虫机制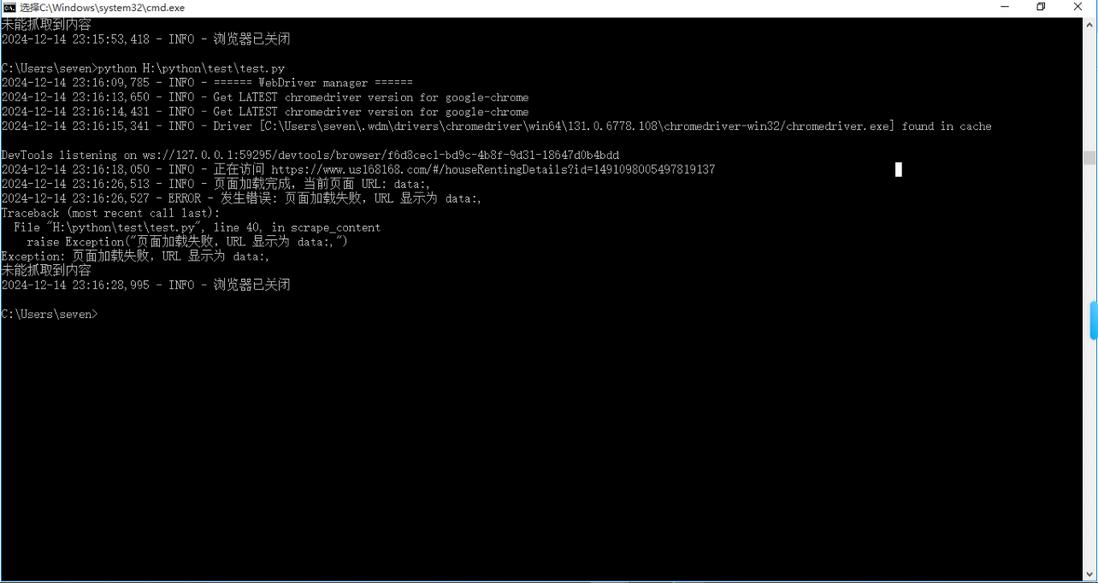
-
我有一些流处理代码,它接受一个单词流并对它们执行一些操作,然后将它们简化为一个,其中包含单词作为键,单词的出现次数作为值。为了代码的简洁性,我使用了jOOL库的类,其中包含许多有用的快捷方法。 类型中的方法不适用于参数 type未定义此处适用的 为什么的行为与有任何不同,我(也许是天真地)认为它是直接等效的,为什么编译器在使用它时不能处理它? (是的,我知道我可以通过将以前的应用程序移到操作中来删
-
我想了解为什么一段代码不会抛出NullPointerException。 请考虑以下代码: 方法被重复调用,同时以下代码在单独的线程中运行: 只有一个实例。 从不引发NullPointerException。 但是,当方法暂停时,即使暂停0毫秒,也会按预期引发NullPointerException: 我的理解是,在理论上,在检查和调用之间存在竞争条件。在实践中,如果不引入暂停(即从后续方法调用中
-
我正在尝试插入: 在: 但我不工作... 我试过: 为什么??
-
在方法或类范围内,下面的行编译(带有警告): 在类作用域中,变量获取其默认值,以下给出未定义引用错误: 这难道不是第一个应该以相同的未定义引用错误结束吗?或者第二行应该编译?或者我错过了什么?
-
这段代码是我用Java Swing制作的Tic-Tac-Toe程序的一部分。为什么在添加用于添加按钮的for语句时返回NullPointerException?
-
因此,下面的代码,从txt文件中取序列号作为参数,在我的计算机上正常工作。每个数字都写在一行上。下面是代码: 但它在CodeEval中不起作用。站点编译器是这么说的: Fontconfig错误:无法加载默认配置文件线程“main”java.awt.HeadLessException:未设置X11显示变量,但此程序执行了需要它的操作。在java.awt.GraphicsEnvironment.Che
-
问题内容: 我正在阅读有关ConcurrentModificationException以及如何避免它的信息。找到了一篇文章。该文章中的第一个清单具有与以下相似的代码,这显然会导致异常: 然后,它继续以各种建议解释如何解决该问题。 当我尝试重现它时,我没有遇到异常! 为什么我没有得到例外? 问题答案: 根据JavaAPI文档,Iterator.hasNext不会抛出。 检查后,您从列表中删除了一个
-
我试图制作一个简单的程序来查找列表的模式,但它只是抛出了范围外错误的索引。 谢谢