
javascript - 后端一次传过来2000万条数据,前端怎么处理?

要可视化展示设备数据,而这个设备数据非常多,一小时就能产生上百万条数据,传过来的json文件都有几百兆大小;
我使用的vue3 vite echarts chrome单标签4g内存爆了
使用原生html js echarts,然后直接引入这个json文件到渲染出来要 20秒左右,但是能够展示
不能取平均值等,降低采样来减小吗?
我们分了一个降采样的查询和不做任何处理的查询,这个就是那个不做处理的

原生js
<div id="main" style="width: 600px;height:400px;"></div>
<!-- <div id="tester" style="width:600px;height:250px;"></div> -->
<script src="https://cdn.jsdelivr.net/npm/echarts/dist/echarts.min.js"></script>
<!-- <script src="./plotly-2.32.0.min.js" charset="utf-8"></script> -->
<script src="./response.js"></script>
<script>
var chartDom = document.getElementById('main');
var myChart = echarts.init(chartDom);
var option;
const xx = data.data.dates
const yy = data.data.directionx
option = {
xAxis: { type: 'category', data: xx },
yAxis: { type: 'value' },
series: [{ data: yy, type: 'line', sampling: 'lttb' }]
};
option && myChart.setOption(option);
</script>部分数据:
{
"code": 0,
"msg": null,
"data": {
"directionx": [6.492834006493665E-4, 6.509656666877379E-4,],
"directiony": [5.452070495968005E-4, 5.45381096391632E-4,],
"dates": ["2024-07-11 13:43:00", "2024-07-11 13:44:00",],
"directionz": [5.630059477387331E-4, 5.6277585267251E-4,],
"info": ["[2,+)", "[1.6,2)", "[1.2,1.6)"]
},
"ok": true
}5个小时的数据:123云盘
vue方面我使用的vue-echarts
希望各位多给点建议或者评论,各个方面都可以
目前有的想法是:
1.iframe (尝试中)
2.流式处理,一次处理一部分,这样应该不会爆内存(没想好具体怎么实现)
3.流式传输,大范围时只有部分数据(反正像素点都被画满了,少了数据看起来也是一样的)当范围缩小时,再进一步拉取数据,类似与地图瓦片那种
尝试使用iframe,把数据传过去(想省去登录),但是加载不出来,但是如果只使用少量的条数就可以,很奇怪,说明东西已经拿到只差渲染了,原生js不是能成功吗?
<iframe id="myIframe" src="../chart/echart.html"></iframe>
<script src="./response.js"></script>
<script>
const iframe = document.getElementById('myIframe');
iframe.onload = function () {
iframe.contentWindow.postMessage(data, '*');
};
</script><div id="main" style="width: 600px;height:400px;"></div>
<script src="https://cdn.jsdelivr.net/npm/echarts/dist/echarts.min.js"></script>
<script>
var chartDom = document.getElementById('main');
var myChart = echarts.init(chartDom);
let option;
window.addEventListener('message', function (event) {
const data = event.data;
document.getElementById('title').innerHTML = '123';
const xx = data.data.dates.slice(0,1000)
const yy = data.data.directionx.slice(0,1000)
option = {
xAxis: { type: 'category', data: xx },
yAxis: { type: 'value' },
series: [{ data: yy, type: 'line', sampling: 'lttb' }]
};
option && myChart.setOption(option);
});
</script>共有5个答案

从传输的角度,可以精简下格式,甚至不一定是 json,把大小降下来,假如 200M,gzip 先降到 60M,再通过精简或者压缩方法,可能可以更小。
从渲染角度,可能你的数据是 reactive 的,所以内存爆了?你可以尝试下不 reactive 试试。

来个偏门做法:
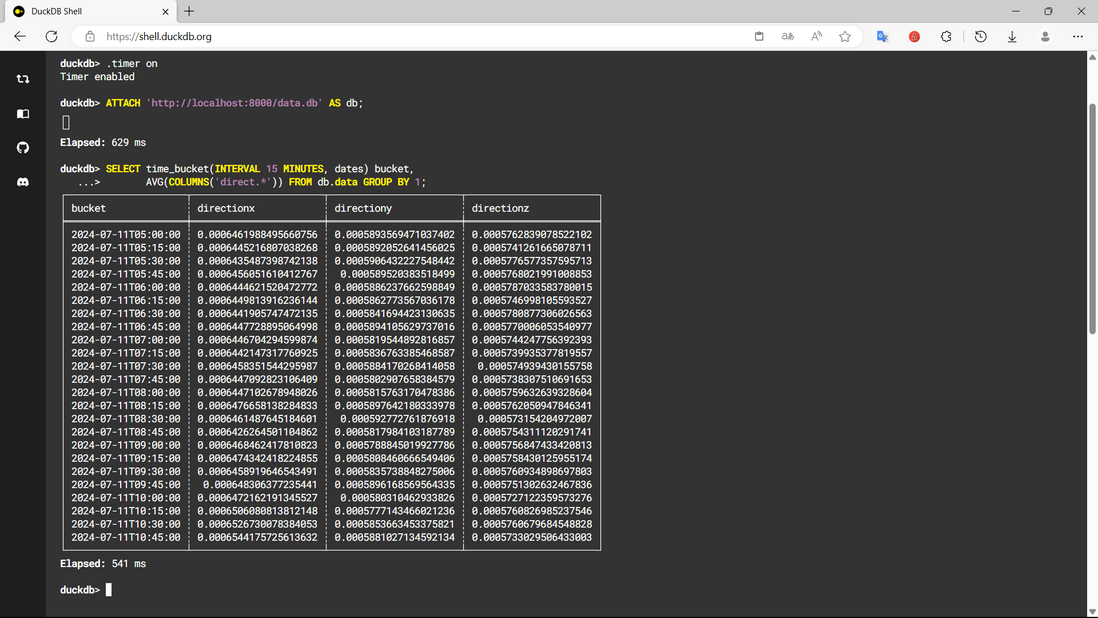
如果你愿意引入 7 MB (gzip) 的 duckdb 模块,
你可以将这 240 MB 数据,转成 50 MB 的数据库,
前端花 0.5 s,将任意时间范围、时间间隔,降采样数据后,再展示出来。
转换方法
(约 8 秒。若用 csv 会更快,也支持 stdin 流式读取)
./duckdb data.db '
CREATE TABLE data (
dates DATETIME,
directionx DOUBLE,
directiony DOUBLE,
directionz DOUBLE
);
INSERT INTO data (directionx, directiony, dates, directionz)
SELECT unnest(COLUMNS(data.* EXCLUDE info))
FROM read_json("response.json", maximum_object_size=256<<20);
'前端查询截图

我有一个想法,让后端把每一个小时的数据提取出较大差值的峰值,显示出来就可,反正看这种图表,看峰值的较多。这样一下就省去了许多条数据量。

把后端打一顿,让他做分页。2000 万条数据前端不可能处理的了的。

回答
处理大量数据,尤其是在前端,通常需要采用一些策略来避免内存不足和性能问题。对于你提到的情况,以下是几个建议:
1. 流式处理或分块加载
- 正如你提到的,流式处理或分块加载是一种有效的策略。你可以将后端返回的数据分割成多个小块,并在需要时逐个加载和渲染。
- 你可以在后端设置API来返回数据的一个子集(例如,基于时间戳的范围或分页),并在前端根据需要请求这些数据。
2. 使用Web Workers
- Web Workers 允许你在浏览器后台线程中运行JavaScript,从而避免阻塞UI线程。你可以将数据处理逻辑放入Web Worker中,以减少对主线程的影响。
3. 虚拟滚动/渲染
- 对于大量数据的可视化,通常不需要一次性渲染所有数据点。你可以使用虚拟滚动或虚拟渲染技术来仅渲染当前可见的数据点。当用户滚动或缩放视图时,可以动态地加载和渲染新的数据点。
4. 数据聚合/下采样
- 尽管你提到不能降低采样或减小数据,但在某些情况下,对数据进行聚合或下采样可能是必要的。这可以通过计算平均值、最大值、最小值等来减少数据点的数量,同时保留数据的整体趋势。
5. 使用更适合大数据可视化的库
- ECharts 是一个非常强大的可视化库,但它可能不是处理大量数据的最佳选择。你可以考虑使用其他专为大数据可视化设计的库,如 Deck.gl、Three.js 结合 Plotly.js 等。
6. 优化数据传输
- 尽量减少数据传输的大小。考虑使用更有效的数据格式(如GZIP压缩的JSON),或仅传输必要的数据(而不是整个JSON文件)。
7. 使用服务器端渲染
- 如果可能的话,考虑使用服务器端渲染来生成图像或图表,并将其作为静态文件或图像发送到前端。这样,前端就无需处理大量数据或执行复杂的渲染逻辑。
8. 关于使用iFrame的建议
- 使用iFrame时,请确保你正确地处理了跨域问题(如果适用)。此外,iFrame可能会增加页面加载时间和复杂性,因此请仔细评估其是否适合你的用例。
9. 其他注意事项
- 考虑在前端实施内存管理和清理机制,以确保不再需要的数据被及时释放。
- 监控和测试你的应用程序的性能和内存使用情况,以便及时发现并解决潜在问题。
希望这些建议能对你有所帮助!
-
用户勾选某一个分类,一次性查询该分类里的所有商品信息,并创建价格任务。 业务员在价格操作的时候,对刚才创建的所有商品信息进行价格操作,根据基准价做涨幅,每个商品都有不同的基准价,现在的问题就是数据量太大,如果一次性操作一万条商品数据,还要根据基准价做涨幅,有什么好的方法?前端如果展示的话,每条商品的涨幅后价格都要显示,请问该怎么操作比较好,后端这边应该怎么进行处理大批量的数据?
-
本文向大家介绍JavaScript如何一次性展示几万条数据,包括了JavaScript如何一次性展示几万条数据的使用技巧和注意事项,需要的朋友参考一下 有一位同事跟大家说他在网上看到一道面试题:“如果后台传给前端几万条数据,前端怎么渲染到页面上?”,如何回答? 于是办公室沸腾了, 同事们讨论开了, 你一言我一语说出自己的方案。 有的说直接循环遍历生成html插到页面上;有的说应该用分页来处理;还有
-
后端返回双精度数据,前端无法正常显示,js只支持浮点数。除了后台转字符串,前端循环添加toFixed,还有别的好的方法吗?
-
比如series有3个对象,里面每个都有data,后台请求数据后,只能通过setOptions的方法设置数据吗?另外顺序呢?只能根据之前写好的顺序填充吗?
-
获取当前数据的上一条,下一条的 MySQL 代码: 代码是一言生成的,测试达到了效果,想问问数据库大佬,这段代码如果对大量数据的查询会影响性能吗,像这一行: 数据库结构: id time ···一些其他列 2 12345660 ··· 3 12345640 ··· 5 12345670 ··· 查询id=2,以time排序: id time ···一些其他列 record_type 3 12345
-
25min 处面 1.项目,说说你项目中的某一个功能如何实现的,有什么亮点。 2.说说重载和重写 3.内连接和外连接,左外连接的话哪个字段是空的 4.如果有一个任务来了,线程池怎么运行 5.线程池的返回值 6.hashset怎么判断重复 7.list和set说说 8.说说有哪些list 9.说说java设计模式 10.单例模式的饿汉式和懒汉式,怎么样可以防止反射。 11.volatile关键字说说