
javascript - 使用正则表达式从html片段中提取文本,可匹配到多行但却只能捕获到最后一行,如何解决?

正则表达式
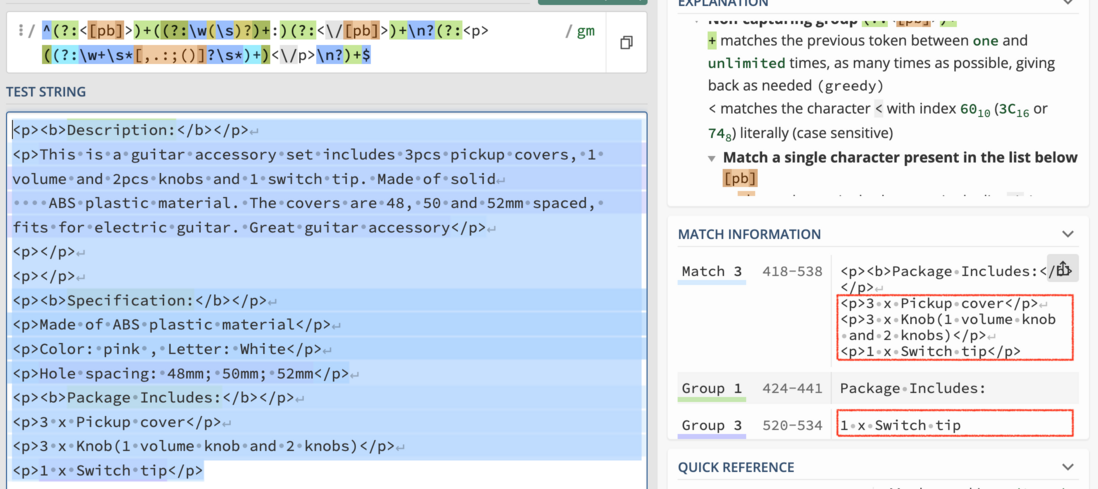
/^(?:<[pb]>)+((?:\w(\s)?)+:)(?:<\/[pb]>)+\n?(?:<p>((?:\w+\s*[,.:;()]?\s*)+)<\/p>\n?)+$/gm- 多行目标字符串
<p><b>Description:</b></p>
<p>This is a guitar accessory set includes 3pcs pickup covers, 1 volume and 2pcs knobs and 1 switch tip. Made of solid
ABS plastic material. The covers are 48, 50 and 52mm spaced, fits for electric guitar. Great guitar accessory</p>
<p></p>
<p></p>
<p><b>Specification:</b></p>
<p>Made of ABS plastic material</p>
<p>Color: pink , Letter: White</p>
<p>Hole spacing: 48mm; 50mm; 52mm</p>
<p><b>Package Includes:</b></p>
<p>3 x Pickup cover</p>
<p>3 x Knob(1 volume knob and 2 knobs)</p>
<p>1 x Switch tip</p>- 匹配及捕获效果:
共有4个答案

想捕获多行就把括号调整一下呗
/^(?:<[pb]>)+((?:\w\s?)+:)(?:<\/[pb]>)+\n?((?:<p>(?:(?:\w+\s*[,.:;()]?\s*)+)<\/p>\n?)+)$/gm
用 xpath 匹配,香很多啊?
$ xidel test.html -e '/html/body/p/text()' --output-format json结果:
[
[
"This is a guitar accessory set includes 3pcs pickup covers, 1 volume and 2pcs knobs and 1 switch tip. Made of solid\n ABS plastic material. The covers are 48, 50 and 52mm spaced, fits for electric guitar. Great guitar accessory",
"Made of ABS plastic material",
"Color: pink , Letter: White",
"Hole spacing: 48mm; 50mm; 52mm",
"3 x Pickup cover",
"3 x Knob(1 volume knob and 2 knobs)",
"1 x Switch tip"
]
]
- 不要用正则匹配 HTML 这种强结构且高兼容性的文本,有很多现成的 DOM 树工具可以用。
- 中间的组本来就不能自动解开成数组,自己想办法分解吧。

您提供的正则表达式有几个问题,这导致它不能正确地捕获您想要的多行文本。首先,正则表达式通常不建议用于解析HTML,因为HTML是一种复杂的嵌套结构,而正则表达式更擅长于处理线性文本。但是,如果您只是想要一个简单的解决方案,并且HTML结构是固定的,您可以尝试修改正则表达式来捕获所需的文本。
以下是针对您给出的HTML片段的一个简化正则表达式,它将尝试捕获<p>标签之间的文本:
/<p>([\s\S]*?)<\/p>/gm这里的关键点是[\s\S]*?,它匹配任何字符(包括换行符),并且是非贪婪的(*?),这意味着它会尽可能少地匹配字符。这很重要,因为如果它是贪婪的(*),它将匹配尽可能多的字符,包括所有<p>标签之间的内容。
然而,请注意,这个正则表达式将捕获每个<p>标签的内容,而不是将它们组合在一起。如果您想要捕获连续的<p>标签的内容(例如,从“Description:”到“Great guitar accessory”),您将需要更复杂的逻辑,可能是使用正则表达式来查找起始和结束标签,然后使用编程逻辑来提取和组合这些标签之间的文本。
以下是使用JavaScript和DOM解析器来提取文本的一个例子,这通常是处理HTML内容的更可靠方法:
// 假设htmlString是包含HTML的字符串
var htmlString = '<p><b>Description:</b></p><p>This is a guitar ...'; // 您的HTML字符串
var parser = new DOMParser();
var doc = parser.parseFromString(htmlString, "text/html");
// 查找所有<p>标签并提取文本
var paragraphs = doc.getElementsByTagName('p');
var text = [];
for (var i = 0; i < paragraphs.length; i++) {
// 移除任何HTML标签并添加到结果数组中
text.push(paragraphs[i].textContent || paragraphs[i].innerText);
}
// 如果您想合并所有段落文本到一个字符串中
var allText = text.join('\n');
console.log(allText);这种方法可以确保您正确地处理所有HTML元素,并且不会受到正则表达式在复杂HTML结构上的限制。
-
问题内容: 我想从一般的HTML页面中提取所有文本(是否显示)。 我想 删除 任何HTML标记 任何JavaScript 任何CSS样式 是否有一个正则表达式(一个或多个)可以实现? 问题答案: 您不能真正用正则表达式解析HTML。太复杂了。RE根本无法正确处理部分。此外,某些常见的HTML之类的东西将在浏览器中作为适当的文本工作,但可能会使天真的RE感到困惑。 有了合适的HTML解析器,您会更快
-
我有一个多行文本,我想从这里匹配单词“Description Amount”和以逗号作为分隔符的随机数字之间的文本。 示例输入: 预期产出: 输入示例: 预期产出: 输入包含多个换行符的变量。我使用了以下正则表达式: 但还需要改进。谢谢你。
-
问题内容: 我正在尝试使用Java匹配多行文本。当我将类与修饰符一起使用时,我可以匹配,但不能. 使用和使用相同的模式似乎无效。 我确定我缺少什么,但不知道是什么。正则表达式不是很好。 这就是我尝试过的 问题答案: 首先,你在错误的假设下使用修饰符。 或告诉Java接受锚点并在每行的开头和结尾进行匹配(否则,它们仅在整个字符串的开头/结尾进行匹配)。 或告诉Java也允许点与换行符匹配。 其次,在
-
问题内容: 原始数据是: 我想匹配一条线,但是不能使用 但是,我可以使用match 。 我该如何搭配 问题答案: 默认情况下,和分别匹配输入的开始和结束。您需要使用启用多行模式,这会导致并匹配行的开始和结束: 演示: 产生以下输出: 编辑我 没有任何匹配的事实是因为默认情况下,和不匹配。如果您通过启用了DOT-ALL ,也使匹配了它们,那么您将看到整个输入字符串都被匹配了: 编辑二 在这种情况下,
-
我有一个正则表达式,它应该将< code>[img]foo.bar[/img]重写为< code > 一个可行的例子是https://www.regex101.com/r/mJ9sM0/1
-
问题内容: var ss= “ ddd”; var arr= ss.match( /<pre.*?<\/pre>/gm ); alert(arr); // null 我希望可以拾取PRE块,即使它跨越换行符也是如此。我以为’m’标志可以做到。才不是。 所以解决方案是: 有谁不那么神秘吗? 编辑:这是重复的,但是由于它比我的更难找到,因此我不会删除。 它建议作为“多行点”。我仍然不明白的是为什么不起
-
问题内容: 是的,您没看错。我需要能够从正则表达式 生成 随机文本的内容。因此,文本应该是随机的,但要与正则表达式匹配。看来它不存在,但我可能是错的。 仅举一个例子:该库将能够以“ ”作为输入,并生成诸如以下示例: abc abbbc bac 等等 更新:我自己创建了一些东西:Xeger。查看http://code.google.com/p/xeger/。 问题答案: 我刚刚创建了一个库来进行此操
-
给定下面的字符串 [NeMo(PROD)]10.10.100.100(EFA-B-3)[博科FC-Switch]传感器:电源#1(SNMP自定义表)关闭(无此名称(SNMP错误#2)) 我尝试获取多个匹配项以提取以下值: 因为我是正则表达式的初学者,所以我试图定义一些“规则”: 提取第一个圆括号内的第一个值,例如PROD 提取第一个闭合方括号和第二个开口圆括号之间的值,例如10.10.100.10