
求mysql取某条件下id及前一条,后一条数据?

数据表结构如下
id,date(时间戳),categoryid(类型id)
数据查询
select id,categoryid,date from table order by categoryid asc,date desc
以上查询会返回n条数据,然后通过程序遍历可以取某id前一id,及后一id,但是有的时候可能会查询到上万条数据,相对来说效率不高,有没有mysq查询最高效的其它方法?
共有3个答案

类似博客分页?上一篇下一篇?
假设预知当前中间数据ID为 x
(select * from table where id < x order by id desc limit 1)union all(select * from table where id > x order by id asc limit 1);
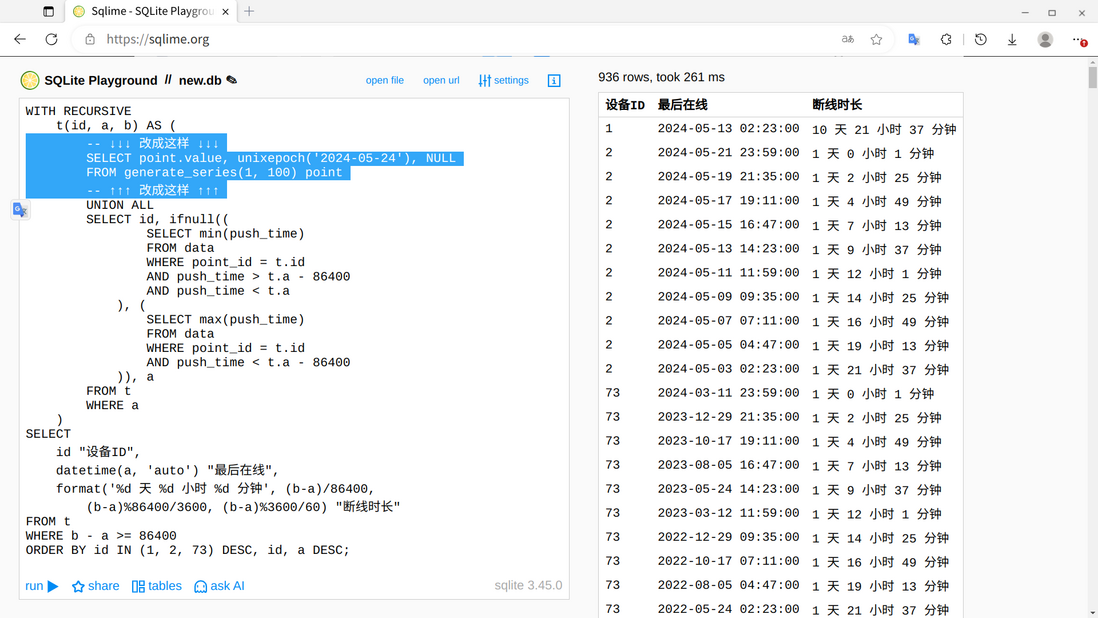
之前写过,在一亿设备推送记录里(每分钟一次,长达两年),找哪些设备超过一天没反应。
里面有用到类似你说的,《不断找 24 小时内最早记录,找不到则 24 小时外最晚记录》。
效率上,浏览器里都能 0.2 秒,查 7W+ 次。本机只需 0.1 秒。
你可以参考下,可能有帮助。

在MySQL中,为了高效地获取某条记录的前一条和后一条记录,可以使用LEAD和LAG窗口函数(在MySQL 8.0及更高版本中可用)。这些函数允许你访问结果集中的前一行和后一行的值,而无需对整个结果集进行排序和遍历。
以下是一个使用LEAD和LAG函数来获取指定id的前一条和后一条记录的示例查询:
SELECT id, categoryid, date, LAG(id) OVER (ORDER BY categoryid ASC, date DESC) AS prev_id, LAG(date) OVER (ORDER BY categoryid ASC, date DESC) AS prev_date, LEAD(id) OVER (ORDER BY categoryid ASC, date DESC) AS next_id, LEAD(date) OVER (ORDER BY categoryid ASC, date DESC) AS next_dateFROM your_table_nameORDER BY categoryid ASC, date DESC;在这个查询中,LAG函数用于获取前一条记录的id和date,而LEAD函数用于获取后一条记录的id和date。OVER子句定义了窗口函数的排序顺序,这里我们按照categoryid升序和date降序进行排序。
请注意,你需要将your_table_name替换为你的实际表名。
这个查询将返回整个排序后的结果集,并且对于每一行都包含了前一条和后一条记录的id和date。如果你只对某个特定id感兴趣,你可以在这个查询的基础上添加一个WHERE子句来过滤结果。例如,如果你想要获取id = 123的前一条和后一条记录,你可以这样做:
SELECT id, categoryid, date, prev_id, prev_date, next_id, next_dateFROM ( SELECT id, categoryid, date, LAG(id) OVER (ORDER BY categoryid ASC, date DESC) AS prev_id, LAG(date) OVER (ORDER BY categoryid ASC, date DESC) AS prev_date, LEAD(id) OVER (ORDER BY categoryid ASC, date DESC) AS next_id, LEAD(date) OVER (ORDER BY categoryid ASC, date DESC) AS next_date FROM your_table_name ORDER BY categoryid ASC, date DESC) AS subqueryWHERE id = 123;这个查询首先执行内部子查询来获取整个结果集以及前一条和后一条记录的id和date,然后在外部查询中添加一个WHERE子句来过滤出id = 123的那一行。
-
获取当前数据的上一条,下一条的 MySQL 代码: 代码是一言生成的,测试达到了效果,想问问数据库大佬,这段代码如果对大量数据的查询会影响性能吗,像这一行: 数据库结构: id time ···一些其他列 2 12345660 ··· 3 12345640 ··· 5 12345670 ··· 查询id=2,以time排序: id time ···一些其他列 record_type 3 12345
-
问题内容: 我正在使用mysql并遇到一些问题。我想检索插入的最后一行。 <<以下是详细>> 以下是我创建表格的方式。 我在其中插入了四个值,如下所示 当我执行时,我得到如下输出 当我尝试下面的代码时, 我得到如下输出。 但是,当我使用代码时,出现错误 使用时,表中没有任何数据。 链接以播放数据 注意: 这里我使用4只是为了获得所需的输出。稍后我可以从查询中获取 如果我只想查看最后一条记录,请建议
-
本文向大家介绍用一条mysql语句插入多条数据,包括了用一条mysql语句插入多条数据的使用技巧和注意事项,需要的朋友参考一下 假如有一个数据表A: id name title addtime 如果需要插入n条数据 : 之前我的想法会是,通过数据构造多条插入语句,循环调用 。如: 之后发现了sql的insert语句可以一次插入多条:
-
问题内容: 我正在尝试将其编译。.我有一个带有firstname和lastname字段的表,并且我有一个字符串,例如“ Bob Jones”或“ Bob Michael Jones”等。 事实是,例如我姓鲍勃,姓迈克尔·琼斯 所以我想 但是它说未知列“ firstlast” ..有人可以帮助吗? 问题答案: 您提供的别名用于查询的输出-它们本身在查询中不可用。 您可以重复表达: 或包装查询
-
我正在使用hibernate在car和person表之间进行一对一映射。但一个人可能有车,也可能没有车。现在,在使用hibernate标准从person表中获取记录时,我只想获取那些拥有汽车的人,即person表中存在相应汽车表条目的条目。如何使用hibernate标准/别名实现这一点? 下面是一段代码。请提供获取结果所需的条件或别名:
-
问题内容: 对于这样的表: 什么是正确的一次查询插入以下操作: 给定用户,插入新记录并返回新记录。但是,如果已经存在,则只需返回。 我知道PostgreSQL 9.5中针对的新语法,但是鉴于我需要返回,因此我无法弄清楚它是否有帮助(如果有的话)。 似乎和不属于在一起。 问题答案: UPSERT的实现非常复杂,以确保不会发生并发写访问。看一下这个Postgres Wiki ,它在最初的开发过程中用作