
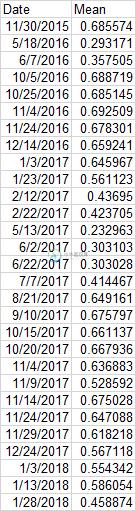
从框架中的一系列数据中找出值和日期

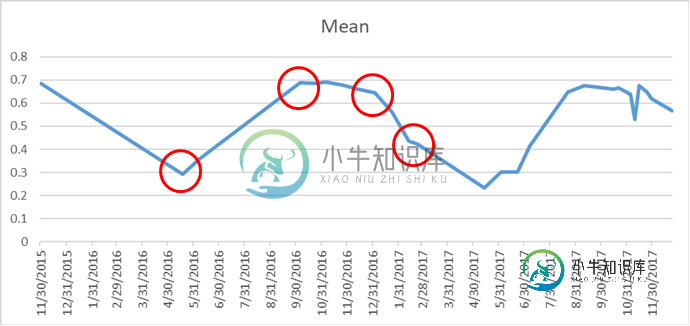
我正在用python pandas编写一个脚本,在这里我必须找到值和日期的第一个下降点,然后在它达到最大点的地方,在下降值和日期之前。然后是下降点值和日期。在我下面展示的图表中,我标记了一个红色圆圈,从中我想要得到日期和值。我有一个脚本,但我需要提到获取值的日期,但我想提取日期和值,任何帮助都将不胜感激。
代码:
import pandas as pd
df = pd.read_csv(r"D:\Data\2015_20.csv", parse_dates=["Date"])
df = df[["Date", "Mean"]]
df = df.set_index("Date")
z1 = df['2016-04-28' : '2017-02-22'].min()
z2 = df['2017-05-13' : '2018-02-02'].max()
z3 = df['2018-03-19' : '2019-03-04'].max()
print("2016", '%.2f'%z1)
print("2017", '%.2f'%z2)
print("2018", '%.2f'%z3)
共有1个答案

您可以使用argrelextrema查找本地最小值和最大值:
from scipy.signal import argrelextrema
np.random.seed(0)
rs = np.random.randn(200)
xs = [0]
for r in rs:
xs.append(xs[-1] * 0.9 + r)
df = pd.DataFrame(xs, columns=['data'], index=pd.date_range('2000-01-01',periods=len(xs)))
n = 5 # number of points to be checked before and after
# Find local peaks
df['min'] = df.iloc[argrelextrema(df.data.values, np.less_equal,
order=n)[0]]['data']
df['max'] = df.iloc[argrelextrema(df.data.values, np.greater_equal,
order=n)[0]]['data']
df['min_date'] = df.index.where(df['min'].notna())
df['max_date'] = df.index.where(df['max'].notna())
print (df.head(15))
data min max min_date max_date
2000-01-01 0.000000 0.000000 NaN 2000-01-01 NaT
2000-01-02 1.764052 NaN NaN NaT NaT
2000-01-03 1.987804 NaN NaN NaT NaT
2000-01-04 2.767762 NaN NaN NaT NaT
2000-01-05 4.731879 NaN NaN NaT NaT
2000-01-06 6.126249 NaN 6.126249 NaT 2000-01-06
2000-01-07 4.536346 NaN NaN NaT NaT
2000-01-08 5.032800 NaN NaN NaT NaT
2000-01-09 4.378163 NaN NaN NaT NaT
2000-01-10 3.837128 NaN NaN NaT NaT
2000-01-11 3.864013 NaN NaN NaT NaT
2000-01-12 3.621656 3.621656 NaN 2000-01-12 NaT
2000-01-13 4.713764 NaN NaN NaT NaT
2000-01-14 5.003425 NaN NaN NaT NaT
2000-01-15 4.624757 NaN NaN NaT NaT
编辑:
来自真实数据的解决方案:
df['Date'] = pd.to_datetime(df['Date'])
df = df.set_index('Date')
from scipy.signal import argrelextrema
n = 5
s1 = df.iloc[argrelextrema(df.Mean.values, np.less_equal,
order=n)[0]]['Mean']
s2 = df.iloc[argrelextrema(df.Mean.values, np.greater_equal,
order=n)[0]]['Mean']
s = s1.append(s2).sort_index()
print (s)
Date
2016-05-18 0.293171
2016-11-04 0.692509
2017-05-13 0.232963
2017-09-10 0.675797
2017-11-09 0.528592
2018-04-03 0.189523
2018-11-09 0.713351
Name: Mean, dtype: float64
s.to_csv('out.csc')
-
我有一张800万行的大桌子。此表有15列带有数值,但这些值只能是0,并且只能是该列特有的另一个数值。我想根据特定值为这些列中的每一列创建两个新列。这些新值总是特定于列。 这是我的数据外观的虚拟示例: 这是我想要的输出 对应关系始终相同,即中1的值为,中2的值为,中3的值为。 我知道我可以用这样的东西 但我的真实数据有15列,需要大量的复制粘贴,有没有干净的方法?
-
我有一个包含两列的数据框架(DF1) 和另一个像这样的数据帧(DF2) 我必须将DF2中的各个字符串值替换为它们在DF1中的相应值…例如,在操作之后,我应该取回这个数据框。 我尝试了多种方法,但似乎无法找到解决方案。
-
我有两个pyspark数据帧 DF1 : df2: 我想向df1添加一个列Location_Id,从df2获取匹配的Id,如下所示: 我如何才能做到这一点?
-
我正在寻找以下问题的矢量化解决方案。有些客户可以同时拥有两种不同产品x或y中的一种。我想识别同一客户的产品x后面跟有产品y的所有行。在这种情况下,产品x的< code>to_date将与产品y的< code>from_date相同。下面是一个示例: 所需的输出如下所示: 到目前为止,我的方法是使用 dplyr 按对 data.frame 进行分组。但是我不知道如何在中检查中相等的值。
-
问题内容: 我有一个名称为的csv文件。我打开并使用以下方法创建了一个熊猫: 其中,是字符串对象的python列表。示例(实际列表的长度为22): 在ipython提示符下,如果我键入并按Enter键,则不会获得带有列和值的数据框,如Pandas网站上的示例所示。相反,我获得有关数据框的信息。我得到: 如果我键入,那么我确实会获得该列的预期值。我有两个问题: (1)在pandas网站上的示例中(例
-
我有两个熊猫数据框 步骤1:根据df1中唯一的“val”在df2中创建列,如下所示: 步骤2:对于flag=1的行,AA_new将计算为var1(来自df2)*组“A”和val“AA”的df1的'cal1'值*组“A”和val“AA”的df1的'cal2'值,类似地,AB_new将计算为var1(来自df2)*组“A”和val“AB”的df1的'cal1'值*组“A”和val“AB”的df1的'c