
提高SQL性能:多次插入或更新多个表

将excel的大数据导入到MySQL数据库需要很长时间,那么如何提高性能呢?
Excel数据喜欢以下内容:
学生表
床单课程
MySQL的表喜欢如下:
学生桌
CREATE TABLE IF NOT EXISTS `student`(
`id` INT UNSIGNED AUTO_INCREMENT,
`name` VARCHAR(100) NOT NULL,
`status` INT,
`course_id` INT NOT NULL,
PRIMARY KEY ( `id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
资源表
CREATE TABLE IF NOT EXISTS `course`(
`id` INT UNSIGNED AUTO_INCREMENT,
`reference_id` INT UNSIGNED,
`course_code` VARCHAR(100) NOT NULL,
`course_qulity` INT NOT NULL,
PRIMARY KEY ( `id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
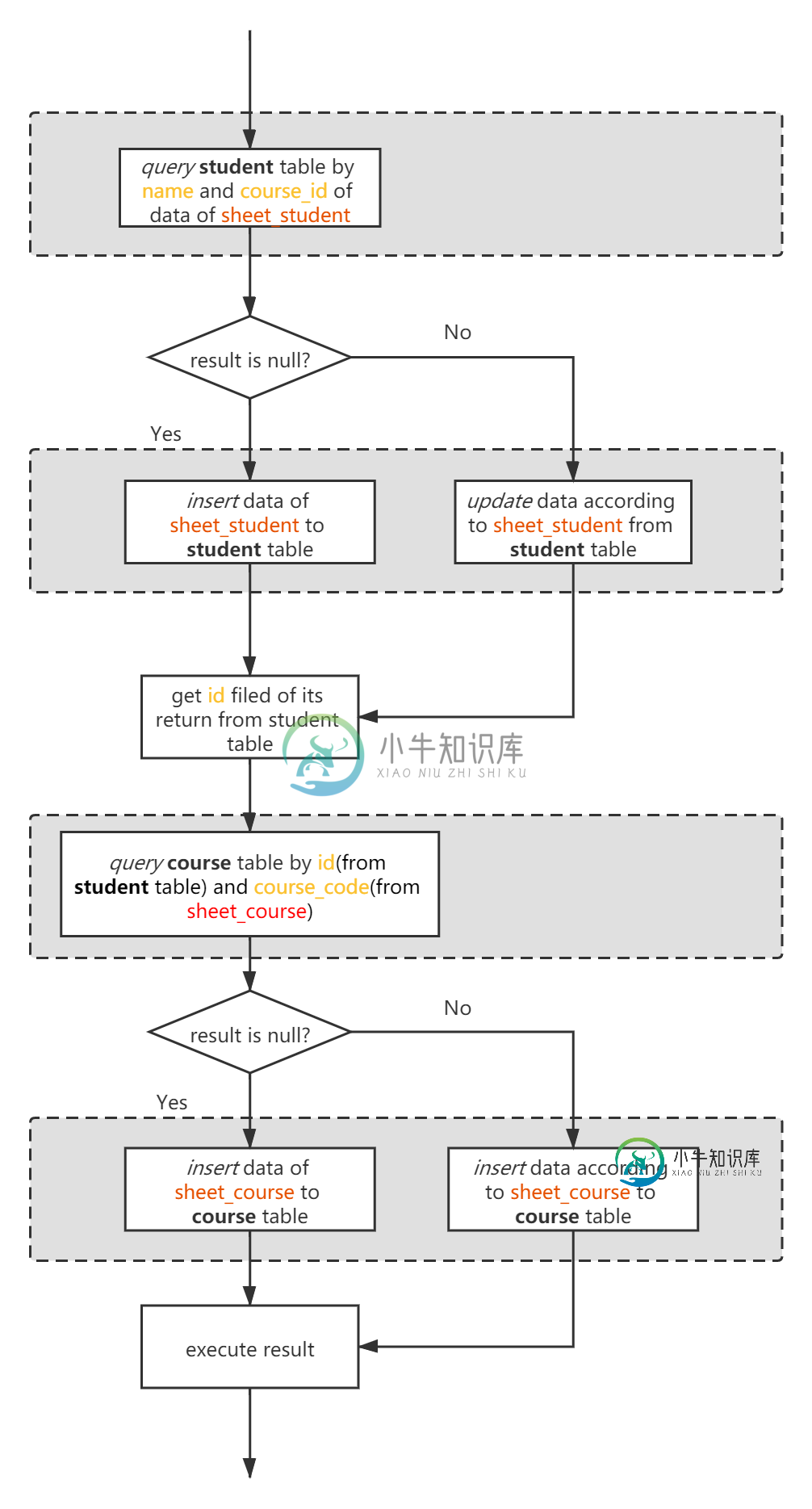
图像的浅灰色区域可能会得到改善,但我不知道如何对其进行优化。使用内部联接查询学生表和课程表是一种很好的方法。但是插入和更新操作无法工作。
excel数据太大时,导入过程将花费很长时间。
更新
当同一个excel多次导入时,MySQL的数据会根据excel数据进行更新<和student表中的code>namecourse\u id字段确定行数据是否唯一<代码>参考id和课程表中的课程字段确定行数据是否唯一。
共有2个答案

加快导入/插入/更新的一些想法:
>
在块中插入数据-为了优化插入速度,将许多小操作合并到一个大操作中。理想情况下,您可以建立一个连接,一次发送许多新行的数据,并将所有索引更新和一致性检查延迟到最后。在实践中,您可以使用这种查询结构插入记录组,例如在每条INSERT语句中插入1000条记录,而不是一次对一条记录执行INSERT:
将值(value1,value2)(value1,value2)插入到表名称(列列表)中。。。(价值1、价值2)
从附近的位置加载数据—如果要将GB或TB的数据加载到远程服务器,请记住,无论实际将记录插入数据库需要多长时间,SQL客户端都需要将该数据传输到该服务器。因此,网络可能是一个重要的瓶颈。此外,打开和关闭每个插入(或一组插入)上的连接,对于大型SQL转储而言,可能会花费大量时间。因此,理想情况下,您应该将文件传输到数据库服务器一次,然后从本地文件系统加载它。

如果可以使用一条语句对整个表(或表的子集)执行操作,则数据库运行速度会快得多。一次做一排事情是很慢的。两个批处理语句可以替换流程图。
- 将每个Excel工作表转储到CSV文件中。
- 将每个CSV加载到MySQL中的暂存表中。
- 使用批处理操作来清除数据(如果需要)。
- 使用批处理操作将数据复制到实际表中。
第四步中的“批量”是指
INSERT INTO ... SELECT ... FROM ...;
或者(正如托尔斯坦所提到的)
INSERT INTO ... SELECT ... FROM ...
ON DUPLICATE KEY UPDATE ...;
或者有时,这里的两步过程可能是有用的。
-
问题内容: 我的数据包含约30 000条记录。而且我需要将此数据插入到MySQL表中。我将这些数据按包进行分组(按1000分组),并创建多个插入,如下所示: 如何优化此插入的性能?每次可以插入1000条以上的记录吗?每行包含大小约为1KB的数据。谢谢。 问题答案: 您需要检查mysql服务器配置,尤其是检查缓冲区大小等。 您可以从表中删除索引(如果有的话),以使其更快。一旦数据输入,就创建索引。
-
问题内容: 在一个表(jdbc / connector-mysql数据库)中插入1000行的最佳/最省时的方法是什么?(它是一个缓冲区,每次充满时都需要转储到数据库中) 1-一个自动生成/固定的SQL语句? 2 3-存储过程 4-通过文件批量插入数据? 5-(您的解决方案) 问题答案: LOAD DATA INFILE语句可能是提高性能的最佳选择。(来自上面的选项列表中的#4)尽管由于您需要创建中
-
问题内容: 如果我需要通过一个“动作”来更新或插入到多个表中,请调用一个保存信息的示例,其中有多个包含“信息”的表。 出于参数考虑,可以说我们有下表: 姓名地址汽车工作 每次调用保存信息时,都会将其中的每个表插入其中。 哪个更好: 获取必须写入名称表的数据。调用InsertOnSubmit并调用SubmitChanges 获取必须写入地址表的数据。调用InsertOnSubmit并调用Submit
-
问题内容: 好的,可以说我要插入100行,每行大约有150列(我知道听起来很多列,但是我需要将此数据存储在一个表中)。插入将随机发生(即,每当一组用户决定上载包含数据的文件时),每月大约20次。但是,数据库将在连续负载下处理大型企业应用程序的其他功能。这些列是varchars,int以及其他各种类型。 将这些插入物包装在一个事务中(而不是一次运行一次)的性能增益会变大,变小还是介于两者之间? 为什
-
我有一个数据模型,在一个实体和11个其他实体之间有一对多的关系。这12个实体一起代表一个数据包。我遇到的问题是,在这些关系的“多”端发生的插入数量。其中一些可以有多达100个单独的值,因此要在数据库中保存一个完整的数据包,最多需要500次插入。 我在InnoDB表中使用MySQL 5.5。现在,通过对数据库的测试,我发现在处理批插入时,它可以轻松地每秒执行15000次插入(对于加载数据,插入次数甚
-
问题内容: 我正在寻找一种对重复键Update(例如SQL Server 2005中的操作)执行插入的解决方案。此操作可能会插入或更新大量条目。SQL Server 2008有一个整洁的操作MERGE,可以很好地完成它,问题是我们只能使用SQL Server2005。 我研究了标准的解决方案,但是它们都不是很好,因为它们假定只有一个入口已更新/插入。 有谁知道在旧版SQL Server中复制MER