
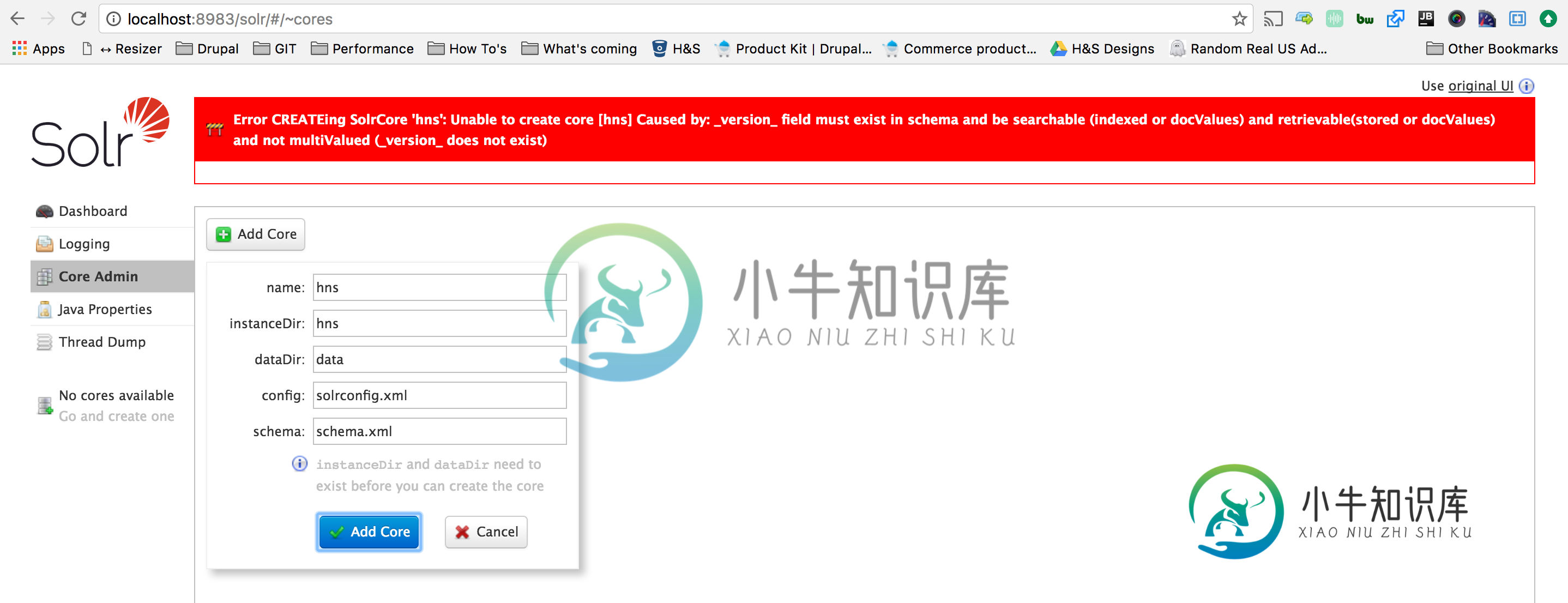
_version_字段必须存在于模式中并且可以搜索:Solr 6.2.0

我所面对的问题与较早前提出的问题相似。但是,即使重启solr服务器,我也无法解决这个错误。
如参考问题中所述,我已检查了所有内容。
- 架构版本为1.6
- 没有类型或字段标记。
这是我的模式。xml文件:
<?xml version="1.0" ?>
<schema name="test" version="1.6">
<fieldType name="int" class="solr.TrieIntField" precisionStep="0" omitNorms="true" positionIncrementGap="0"/>
<fieldType name="float" class="solr.TrieFloatField" precisionStep="0" omitNorms="true" positionIncrementGap="0"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" omitNorms="true" positionIncrementGap="0"/>
<fieldType name="double" class="solr.TrieDoubleField" precisionStep="0" omitNorms="true" positionIncrementGap="0"/>
<fieldType name="tint" class="solr.TrieIntField" precisionStep="8" omitNorms="true" positionIncrementGap="0"/>
<fieldType name="tfloat" class="solr.TrieFloatField" precisionStep="8" omitNorms="true" positionIncrementGap="0"/>
<fieldType name="tlong" class="solr.TrieLongField" precisionStep="8" omitNorms="true" positionIncrementGap="0"/>
<fieldType name="tdouble" class="solr.TrieDoubleField" precisionStep="8" omitNorms="true" positionIncrementGap="0"/>
<!-- Field type demonstrating an Analyzer failure -->
<fieldType name="failtype1" class="solr.TextField">
<analyzer type="index">
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="0" catenateWords="0"
catenateNumbers="0" catenateAll="0"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- Demonstrating ignoreCaseChange -->
<fieldType name="wdf_nocase" class="solr.TextField">
<analyzer>
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="0" catenateWords="0"
catenateNumbers="0" catenateAll="0" splitOnCaseChange="0" preserveOriginal="0"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="wdf_preserve" class="solr.TextField">
<analyzer>
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="0" generateNumberParts="1" catenateWords="0"
catenateNumbers="0" catenateAll="0" splitOnCaseChange="0" preserveOriginal="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
<fieldType name="string" class="solr.StrField" sortMissingLast="true"/>
<!-- format for date is 1995-12-31T23:59:59.999Z and only the fractional
seconds part (.999) is optional.
-->
<fieldType name="date" class="solr.TrieDateField" precisionStep="0"/>
<fieldType name="tdate" class="solr.TrieDateField" precisionStep="6"/>
<!-- solr.TextField allows the specification of custom
text analyzers specified as a tokenizer and a list
of token filters.
-->
<fieldType name="text" class="solr.TextField">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StandardFilterFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="nametext" class="solr.TextField">
<analyzer class="org.apache.lucene.analysis.core.WhitespaceAnalyzer"/>
</fieldType>
<fieldType name="teststop" class="solr.TextField">
<analyzer>
<tokenizer class="solr.LowerCaseTokenizerFactory"/>
<filter class="solr.StandardFilterFactory"/>
</analyzer>
</fieldType>
<!-- fieldTypes in this section isolate tokenizers and tokenfilters for testing -->
<fieldType name="lowertok" class="solr.TextField">
<analyzer>
<tokenizer class="solr.LowerCaseTokenizerFactory"/>
</analyzer>
</fieldType>
<fieldType name="keywordtok" class="solr.TextField">
<analyzer>
<tokenizer class="solr.MockTokenizerFactory" pattern="keyword"/>
</analyzer>
</fieldType>
<fieldType name="standardtok" class="solr.TextField">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
</analyzer>
</fieldType>
<fieldType name="lettertok" class="solr.TextField">
<analyzer>
<tokenizer class="solr.LetterTokenizerFactory"/>
</analyzer>
</fieldType>
<fieldType name="whitetok" class="solr.TextField">
<analyzer>
<tokenizer class="solr.MockTokenizerFactory"/>
</analyzer>
</fieldType>
<fieldType name="HTMLstandardtok" class="solr.TextField">
<analyzer>
<charFilter class="solr.HTMLStripCharFilterFactory"/>
<tokenizer class="solr.StandardTokenizerFactory"/>
</analyzer>
</fieldType>
<fieldType name="HTMLwhitetok" class="solr.TextField">
<analyzer>
<charFilter class="solr.HTMLStripCharFilterFactory"/>
<tokenizer class="solr.MockTokenizerFactory"/>
</analyzer>
</fieldType>
<fieldType name="standardtokfilt" class="solr.TextField">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StandardFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="standardfilt" class="solr.TextField">
<analyzer>
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.StandardFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="lowerfilt" class="solr.TextField">
<analyzer>
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="lowerpunctfilt" class="solr.TextField">
<analyzer>
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1"
catenateNumbers="1" catenateAll="1" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="patternreplacefilt" class="solr.TextField">
<analyzer type="index">
<tokenizer class="solr.MockTokenizerFactory" pattern="keyword"/>
<filter class="solr.PatternReplaceFilterFactory"
pattern="([^a-zA-Z])" replacement="_" replace="all"
/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.MockTokenizerFactory" pattern="keyword"/>
</analyzer>
</fieldType>
<fieldType name="patterntok" class="solr.TextField">
<analyzer>
<tokenizer class="solr.PatternTokenizerFactory" pattern=","/>
</analyzer>
</fieldType>
<fieldType name="porterfilt" class="solr.TextField">
<analyzer>
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- fieldType name="snowballfilt" class="solr.TextField">
<analyzer>
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.SnowballPorterFilterFactory"/>
</analyzer>
</fieldType -->
<fieldType name="engporterfilt" class="solr.TextField">
<analyzer>
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="custengporterfilt" class="solr.TextField">
<analyzer>
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="stopfilt" class="solr.TextField">
<analyzer>
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true"/>
</analyzer>
</fieldType>
<fieldType name="custstopfilt" class="solr.TextField">
<analyzer>
<tokenizer class="solr.MockTokenizerFactory"/>
</analyzer>
</fieldType>
<fieldType name="lengthfilt" class="solr.TextField">
<analyzer>
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.LengthFilterFactory" min="2" max="5"/>
</analyzer>
</fieldType>
<fieldType name="charfilthtmlmap" class="solr.TextField">
<analyzer>
<charFilter class="solr.HTMLStripCharFilterFactory"/>
<tokenizer class="solr.MockTokenizerFactory"/>
</analyzer>
</fieldType>
<fieldType name="subword" class="solr.TextField" multiValued="true" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1"
catenateNumbers="1" catenateAll="0"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="0"
catenateNumbers="0" catenateAll="0"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="numericsubword" class="solr.TextField" multiValued="true" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.WordDelimiterFilterFactory" splitOnNumerics="0" splitOnCaseChange="0" generateWordParts="1"
generateNumberParts="0" catenateWords="0" catenateNumbers="0" catenateAll="0"/>
<filter class="solr.StopFilterFactory"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.WordDelimiterFilterFactory" splitOnNumerics="0" splitOnCaseChange="0" generateWordParts="1"
generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0"/>
<filter class="solr.StopFilterFactory"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="protectedsubword" class="solr.TextField" multiValued="true" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.WordDelimiterFilterFactory" splitOnNumerics="0" splitOnCaseChange="0" generateWordParts="1"
generateNumberParts="1" catenateWords="0" catenateNumbers="0" catenateAll="0"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- more flexible in matching skus, but more chance of a false match -->
<fieldType name="skutype1" class="solr.TextField">
<analyzer type="index">
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1"
catenateNumbers="1" catenateAll="0"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="0" generateNumberParts="0" catenateWords="1"
catenateNumbers="1" catenateAll="0"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- less flexible in matching skus, but less chance of a false match -->
<fieldType name="skutype2" class="solr.TextField">
<analyzer type="index">
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="0" generateNumberParts="0" catenateWords="1"
catenateNumbers="1" catenateAll="0"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="0" generateNumberParts="0" catenateWords="1"
catenateNumbers="1" catenateAll="0"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- less flexible in matching skus, but less chance of a false match -->
<fieldType name="syn" class="solr.TextField">
<analyzer>
<tokenizer class="solr.MockTokenizerFactory"/>
</analyzer>
</fieldType>
<fieldType name="unstored" class="solr.StrField" indexed="true" stored="false"/>
<fieldType name="textgap" class="solr.TextField" multiValued="true" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.MockTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="uuid" class="solr.UUIDField"/>
<!-- Try out some point types -->
<fieldType name="xy" class="solr.PointType" dimension="2" subFieldType="double"/>
<fieldType name="x" class="solr.PointType" dimension="1" subFieldType="double"/>
<fieldType name="tenD" class="solr.PointType" dimension="10" subFieldType="double"/>
<!-- Use the sub field suffix -->
<fieldType name="xyd" class="solr.PointType" dimension="2" subFieldSuffix="_d1"/>
<fieldType name="geohash" class="solr.GeoHashField"/>
<fieldType name="latLon" class="solr.LatLonType" subFieldType="double"/>
<!-- some per-field similarity examples -->
<!-- specify a Similarity classname directly -->
<!--
<fieldType name="sim1" class="solr.TextField">
<analyzer>
<tokenizer class="solr.MockTokenizerFactory"/>
</analyzer>
<similarity class="org.apache.lucene.misc.SweetSpotSimilarity"/>
</fieldType>
-->
<!-- specify a Similarity factory -->
<!--
<fieldType name="sim2" class="solr.TextField">
<analyzer>
<tokenizer class="solr.MockTokenizerFactory"/>
</analyzer>
<similarity class="org.apache.solr.search.similarities.CustomSimilarityFactory">
<str name="echo">is there an echo?</str>
</similarity>
</fieldType>
-->
<!-- don't specify any sim at all: get the default -->
<!--
<fieldType name="sim3" class="solr.TextField">
<analyzer>
<tokenizer class="solr.MockTokenizerFactory"/>
</analyzer>
</fieldType>
-->
<field name="id" type="int" indexed="true" stored="true" multiValued="false" required="false"/>
<field name="signatureField" type="string" indexed="true" stored="false"/>
<field name="uuid" type="uuid" stored="true"/>
<field name="name" type="nametext" indexed="true" stored="true"/>
<field name="text" type="text" indexed="true" stored="false"/>
<field name="subject" type="text" indexed="true" stored="true"/>
<field name="title" type="nametext" indexed="true" stored="true"/>
<field name="weight" type="float" indexed="true" stored="true" multiValued="false"/>
<field name="bday" type="date" indexed="true" stored="true" multiValued="false"/>
<field name="title_stemmed" type="text" indexed="true" stored="false"/>
<field name="title_lettertok" type="lettertok" indexed="true" stored="false"/>
<field name="syn" type="syn" indexed="true" stored="true"/>
<!-- to test property inheritance and overriding -->
<field name="shouldbeunstored" type="unstored"/>
<field name="shouldbestored" type="unstored" stored="true"/>
<field name="shouldbeunindexed" type="unstored" indexed="false" stored="true"/>
<!-- Test points -->
<!-- Test points -->
<field name="home" type="xy" indexed="true" stored="true" multiValued="false"/>
<field name="x" type="x" indexed="true" stored="true" multiValued="false"/>
<field name="homed" type="xyd" indexed="true" stored="true" multiValued="false"/>
<field name="home_ns" type="xy" indexed="true" stored="false" multiValued="false"/>
<field name="work" type="xy" indexed="true" stored="true" multiValued="false"/>
<field name="home_ll" type="latLon" indexed="true" stored="true" multiValued="false"/>
<field name="home_gh" type="geohash" indexed="true" stored="true" multiValued="false"/>
<field name="point10" type="tenD" indexed="true" stored="true" multiValued="false"/>
<!-- test different combinations of indexed and stored -->
<field name="bind" type="boolean" indexed="true" stored="false"/>
<field name="bsto" type="boolean" indexed="false" stored="true"/>
<field name="bindsto" type="boolean" indexed="true" stored="true"/>
<field name="isto" type="int" indexed="false" stored="true"/>
<field name="iind" type="int" indexed="true" stored="false"/>
<field name="ssto" type="string" indexed="false" stored="true"/>
<field name="sind" type="string" indexed="true" stored="false"/>
<field name="sindsto" type="string" indexed="true" stored="true"/>
<!-- test combinations of term vector settings -->
<field name="test_basictv" type="text" termVectors="true"/>
<field name="test_notv" type="text" termVectors="false"/>
<field name="test_postv" type="text" termVectors="true" termPositions="true"/>
<field name="test_offtv" type="text" termVectors="true" termOffsets="true"/>
<field name="test_posofftv" type="text" termVectors="true"
termPositions="true" termOffsets="true"/>
<!-- fields to test individual tokenizers and tokenfilters -->
<field name="teststop" type="teststop" indexed="true" stored="true"/>
<field name="lowertok" type="lowertok" indexed="true" stored="true"/>
<field name="keywordtok" type="keywordtok" indexed="true" stored="true"/>
<field name="standardtok" type="standardtok" indexed="true" stored="true"/>
<field name="HTMLstandardtok" type="HTMLstandardtok" indexed="true" stored="true"/>
<field name="lettertok" type="lettertok" indexed="true" stored="true"/>
<field name="whitetok" type="whitetok" indexed="true" stored="true"/>
<field name="HTMLwhitetok" type="HTMLwhitetok" indexed="true" stored="true"/>
<field name="standardtokfilt" type="standardtokfilt" indexed="true" stored="true"/>
<field name="standardfilt" type="standardfilt" indexed="true" stored="true"/>
<field name="lowerfilt" type="lowerfilt" indexed="true" stored="true"/>
<field name="lowerfilt1" type="lowerfilt" indexed="true" stored="true"/>
<field name="lowerfilt1and2" type="lowerfilt" indexed="true" stored="true"/>
<field name="patterntok" type="patterntok" indexed="true" stored="true"/>
<field name="patternreplacefilt" type="patternreplacefilt" indexed="true" stored="true"/>
<field name="porterfilt" type="porterfilt" indexed="true" stored="true"/>
<field name="engporterfilt" type="engporterfilt" indexed="true" stored="true"/>
<field name="custengporterfilt" type="custengporterfilt" indexed="true" stored="true"/>
<field name="stopfilt" type="stopfilt" indexed="true" stored="true"/>
<field name="custstopfilt" type="custstopfilt" indexed="true" stored="true"/>
<field name="lengthfilt" type="lengthfilt" indexed="true" stored="true"/>
<field name="wdf_nocase" type="wdf_nocase" indexed="true" stored="true"/>
<field name="wdf_preserve" type="wdf_preserve" indexed="true" stored="true"/>
<field name="numberpartfail" type="failtype1" indexed="true" stored="true"/>
<field name="nullfirst" type="string" indexed="true" stored="true" sortMissingFirst="true" multiValued="false"/>
<field name="subword" type="subword" indexed="true" stored="true"/>
<field name="subword_offsets" type="subword" indexed="true" stored="true" termOffsets="true"/>
<field name="numericsubword" type="numericsubword" indexed="true" stored="true"/>
<field name="protectedsubword" type="protectedsubword" indexed="true" stored="true"/>
<field name="sku1" type="skutype1" indexed="true" stored="true"/>
<field name="sku2" type="skutype2" indexed="true" stored="true"/>
<field name="textgap" type="textgap" indexed="true" stored="true"/>
<field name="timestamp" type="date" indexed="true" stored="true" default="NOW" multiValued="false"/>
<field name="multiDefault" type="string" indexed="true" stored="true" default="muLti-Default" multiValued="true"/>
<field name="intDefault" type="int" indexed="true" stored="true" default="42" multiValued="false"/>
<!--
<field name="sim1text" type="sim1" indexed="true" stored="true"/>
<field name="sim2text" type="sim2" indexed="true" stored="true"/>
<field name="sim3text" type="sim3" indexed="true" stored="true"/>
-->
<field name="tlong" type="tlong" indexed="true" stored="true"/>
<field name="_version_" type="long" indexed="true" stored="true"/>
<!-- Dynamic field definitions. If a field name is not found, dynamicFields
will be used if the name matches any of the patterns.
RESTRICTION: the glob-like pattern in the name attribute must have
a "*" only at the start or the end.
EXAMPLE: name="*_i" will match any field ending in _i (like myid_i, z_i)
Longer patterns will be matched first. if equal size patterns
both match, the first appearing in the schema will be used.
-->
<dynamicField name="*_i" type="int" indexed="true" stored="true"/>
<dynamicField name="*_i1" type="int" indexed="true" stored="true" multiValued="false"/>
<dynamicField name="*_s" type="string" indexed="true" stored="true"/>
<dynamicField name="*_s1" type="string" indexed="true" stored="true" multiValued="false"/>
<dynamicField name="*_l" type="long" indexed="true" stored="true"/>
<dynamicField name="*_l1" type="long" indexed="true" stored="true" multiValued="false"/>
<dynamicField name="*_t" type="text" indexed="true" stored="true"/>
<dynamicField name="*_b" type="boolean" indexed="true" stored="true"/>
<dynamicField name="*_f" type="float" indexed="true" stored="true"/>
<dynamicField name="*_f1" type="float" indexed="true" stored="true" multiValued="false"/>
<dynamicField name="*_d" type="double" indexed="true" stored="true"/>
<dynamicField name="*_d1" type="double" indexed="true" stored="true" multiValued="false"/>
<dynamicField name="*_dt" type="date" indexed="true" stored="true"/>
<dynamicField name="*_dt1" type="date" indexed="true" stored="true" multiValued="false"/>
<!-- some trie-coded dynamic fields for faster range queries -->
<dynamicField name="*_ti" type="tint" indexed="true" stored="true"/>
<dynamicField name="*_ti1" type="tint" indexed="true" stored="true" multiValued="false"/>
<dynamicField name="*_tl" type="tlong" indexed="true" stored="true"/>
<dynamicField name="*_tl1" type="tlong" indexed="true" stored="true" multiValued="false"/>
<dynamicField name="*_tf" type="tfloat" indexed="true" stored="true"/>
<dynamicField name="*_tf1" type="tfloat" indexed="true" stored="true" multiValued="false"/>
<dynamicField name="*_td" type="tdouble" indexed="true" stored="true"/>
<dynamicField name="*_td1" type="tdouble" indexed="true" stored="true" multiValued="false"/>
<dynamicField name="*_tds" type="tdouble" indexed="true" stored="true" multiValued="false"/>
<dynamicField name="*_tdt" type="tdate" indexed="true" stored="true"/>
<dynamicField name="*_tdt1" type="tdate" indexed="true" stored="true" multiValued="false"/>
<dynamicField name="*_sI" type="string" indexed="true" stored="false"/>
<dynamicField name="*_sS" type="string" indexed="false" stored="true"/>
<dynamicField name="t_*" type="text" indexed="true" stored="true"/>
<dynamicField name="tv_*" type="text" indexed="true" stored="true"
termVectors="true" termPositions="true" termOffsets="true"/>
<dynamicField name="tv_mv_*" type="text" indexed="true" stored="true" multiValued="true"
termVectors="true" termPositions="true" termOffsets="true"/>
<dynamicField name="*_p" type="xyd" indexed="true" stored="true" multiValued="false"/>
<!-- special fields for dynamic copyField test -->
<dynamicField name="dynamic_*" type="string" indexed="true" stored="true"/>
<dynamicField name="*_dynamic" type="string" indexed="true" stored="true"/>
<!-- for testing to ensure that longer patterns are matched first -->
<dynamicField name="*aa" type="string" indexed="true" stored="true"/>
<dynamicField name="*aaa" type="int" indexed="false" stored="true"/>
<!-- ignored becuase not stored or indexed -->
<dynamicField name="*_ignored" type="text" indexed="false" stored="false"/>
<dynamicField name="*_mfacet" type="string" indexed="true" stored="false" multiValued="true"/>
<!-- make sure custom sims work with dynamic fields -->
<!--
<dynamicField name="*_sim1" type="sim1" indexed="true" stored="true"/>
<dynamicField name="*_sim2" type="sim2" indexed="true" stored="true"/>
<dynamicField name="*_sim3" type="sim3" indexed="true" stored="true"/>
-->
<defaultSearchField>text</defaultSearchField>
<uniqueKey>id</uniqueKey>
<!-- copyField commands copy one field to another at the time a document
is added to the index. It's used either to index the same field different
ways, or to add multiple fields to the same field for easier/faster searching.
-->
<copyField source="title" dest="title_stemmed"/>
<copyField source="title" dest="title_lettertok"/>
<copyField source="title" dest="text"/>
<copyField source="subject" dest="text"/>
<copyField source="lowerfilt1" dest="lowerfilt1and2"/>
<copyField source="lowerfilt" dest="lowerfilt1and2"/>
<copyField source="*_t" dest="text"/>
<copyField source="id" dest="range_facet_l"/>
<copyField source="range_facet_f" dest="range_facet_d"/>
<!-- dynamic destination -->
<copyField source="*_dynamic" dest="dynamic_*"/>
</schema>
如果有区别的话,我得到了模式。来自的xml文件https://github.com/apache/lucene-solr/blob/master/solr/solrj/src/test-files/solrj/solr/collection1/conf/schema.xml
共有1个答案

您需要有如下字段定义:
<field name="_version_" type="long" indexed="true" stored="true" multiValued="false"/>
并确保更新了模式。在重新启动所有节点之前,使用zkcli在Zookeeper中创建xml文件。
-
问题内容: 我正在使用最新版本的elasticsearch-php以及最新版本的MongoDB和ElasticSearch。 我需要对可以包含一个或多个值的多个字段进行搜索。例: country_code应为NL,BE或DE,并且类别应包含AA01,BB01,CC02或ZZ11 我以为我会按照以下方式解决它(PHP): 但是结果甚至还不能接近我期望返回的数据。 有时 $ countries 和/或
-
问题内容: 在文档中,某些类型(例如数字和日期)指定存储默认为no。但是该字段仍然可以从json中检索。 令人困惑。这是否表示_source? 有没有办法根本不存储字段,而只是对其建立索引并进行搜索? 问题答案: 默认情况下,不存储任何字段类型。只有领域。这意味着您始终可以取回发送给搜索引擎的内容。即使您要求特定的字段,elasticsearch也会为您解析该字段并将其退还给您。 您可以根据需要禁
-
除了查询之外,两者的提取看起来完全相同: 第一个查询返回: 但第二个查询返回错误: 但我得到了同样的错误
-
应用内搜索 当应用内包含大量信息的时候,用户希望能够通过搜索快速地定位到特定内容。 最基本的搜索包括以下过程: 打开一个搜索文本框 输入查询并提交 显示搜索结果集 然而,可以通过加入一些增强功能来显著提升搜索体验: 启用语音搜索 提供基于用户最近历史查询的搜索建议,即使是在输入查询之前 提供满足应用数据中实际结果的自动完成搜索建议 应用内搜索中有两种主要的模式:持久性搜索(persistent s
-
我使用Elastic5.4,想要查询包含多种类型文档的索引。(类型a和类型b)。下面是索引中的示例文档: 文件: 映射: 我的查询是在任何类型的任何字段中搜索所有包含“John”的文档,并突出显示找到匹配的字段。这个查询是按照弹性文档构造的。我的模式映射将ngram_analyzer配置为分析器,而不是模式中所有字符串类型字段的默认分析器。 如何在结果中返回高亮显示?
-
现在,据我所知,我必须使用两个QueryParser,因为我需要使用两个不同的分析器来搜索两个字段,每个字段一个。我想不出怎么把它们结合起来。我想要的是一个TopDoc,其中的结果是排序的相关性得分,这是一些组合的2相关性得分从搜索的文件名字段和搜索的内容字段。Lucene7.4是否为您提供了轻松解决此问题的方法? 附:这是我很长一段时间以来的第一个帖子,如果不是永远的话。请注明任何格式或内容问题