
如何从硒中获取元素的属性?

我正在使用Python中的Selenium。我想获取的. val()
这是我的代码:
def test_chart_renders_from_url(self):
url = 'http://localhost:8000/analyse/'
self.browser.get(url)
org = driver.find_element_by_id('org')
# Find the value of org?
我该怎么做?Selenium文档似乎有很多关于选择元素的内容,但没有关于属性的内容。
共有3个答案

由于最近开发的Web应用程序使用JavaScript、jQuery、AngularJS、ReactJS等,因此,要通过Selenium检索元素的属性,您必须引导WebDriverWait将WebDriver实例与滞后的Web客户端(即Web浏览器)同步,然后再尝试检索任何属性。
一些示例:
>
从可见元素中检索任何属性(例如
attribute_value = WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.ID, "org"))).get_attribute("attribute_name")从交互元素中检索任何属性(例如<代码>attribute_value = WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.ID, "org"))).get_attribute("attribute_name")下面是超文本标记语言中常用的一些属性列表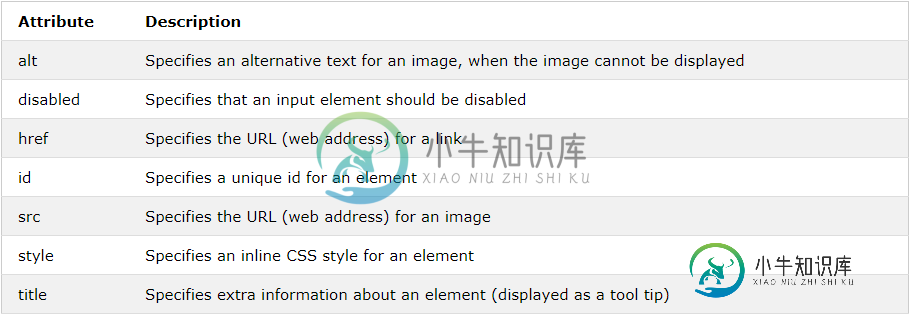
注意:HTML属性参考中列出了每个HTML元素的所有属性的完整列表

蟒蛇
element.get_attribute("attribute name")
Java语言
element.getAttribute("attribute name")
红宝石*
element.attribute("attribute name")
C类#
element.GetAttribute("attribute name");

您可能正在寻找get_attribute()。这里也显示了一个例子
def test_chart_renders_from_url(self):
url = 'http://localhost:8000/analyse/'
self.browser.get(url)
org = driver.find_element_by_id('org')
# Find the value of org?
val = org.get_attribute("attribute name")
-
问题内容: 我正在Python中使用Selenium。我想获取一个元素的,并检查它是否是我所期望的。 这是我的代码: 我怎样才能做到这一点?Selenium文档似乎有很多关于选择元素的内容,但是与属性无关。 问题答案: 您可能正在寻找。一个例子示此处以及
-
在火虫中,我有一个与此内容的链接: 如何使用“类名”访问链接(单击它)? 我尝试了以下方法: 但是我得到了错误: 线程“main” org.openqa.selenium中出现异常。InvalidSelectorException:给定的选择器cb_or_somename cb_area_0219无效或不产生WebElement 发生以下错误:InvalidSelectorError:不允许使用复
-
比起Ruby、Capybara和SitePrism,我更熟悉Java和Selenium,所以如果这个问题太多,我深表歉意。 Selenium有一个非常有用的类来管理Select标签,Selenium::WebDriver::Support::Select,它可以通过传递代表select的Selenium Element(Selenium::WebDriver::Element)来创建。我想得到一个
-
问题内容: 的HTML 码 问题答案: 我已经看到这个问题在过去大约一年左右的时间里弹出了几次,我想尝试编写此函数…所以就到这里了。它接受父元素,并删除每个子元素的textContent,直到剩下的是textNode为止。我已经在您的HTML上对其进行了测试,并且可以正常工作。 你叫它
-
问题内容: 第一个和第二个显示的内容只不过是一个空字符串,我认为应该是and 。但是,经过精心设置之后,第三个终于警报了。 但为什么?我如何才能正确检索该属性? 谢谢。 问题答案: 的属性直接映射到 属性,而不是所施加的样式。为此,您需要getComputedStyle。 我会认真考虑切换演示文稿并将其与逻辑完全分开。
-
我正在尝试使用以下结构单击element: 但是,这将抛出。 我当前正在使用:刮取(父)元素列表。这标识了正确的元素列表(按预期工作)。有了列表后,我应用以下函数: 使用: 而且 但是,这将触发。 我对此进行了几个小时的研究,基于几个帖子,我添加了“。”在两个斜杠之前,这表示相对于父级(而不是相对于整个DOM)。 如果我移除这个点,我总是得到页面上的第一个元素--而不是列表中每个父元素的子元素。