
selenium-通过h1和p文本查找文章

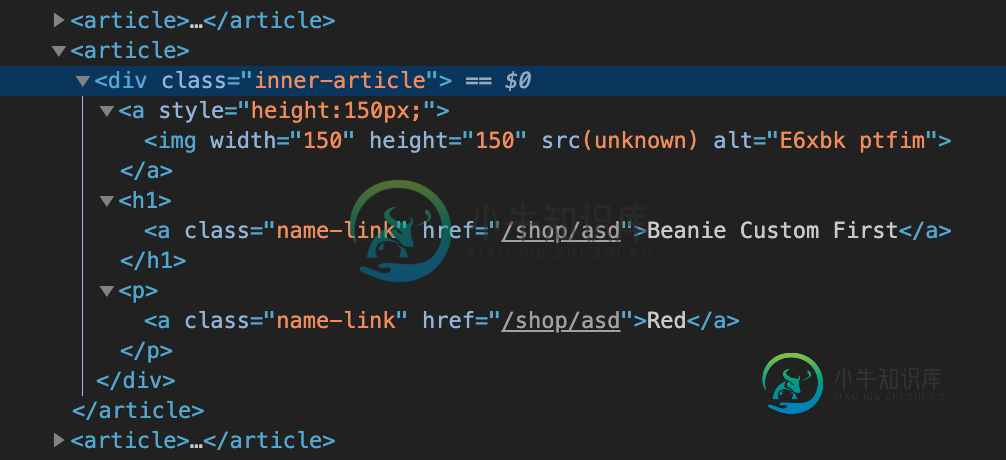
如何在网站上找到像下图一样的h1和p文本的文章?
我试过这个,在那里我可以找到所有的文章,我不知道如何找到这一个与文本在h1和文本在p。然后我想点击这个。
text = driver.find_elements_by_xpath("//article/div[contains(@class,'inner-article')]/h1")
共有2个答案

text = driver.find_elements_by_xpath("//article/div[contains(@class,'inner-article')][h1/a[contains(text(),"Beanie")]][p/a[contains(text(),"Red")]]")
您可以使用上面的xpath,它将检查父元素title/div是否有子元素h1/a和p/a,文本分别为Beanie和Red
在w3chool中,html编辑器位于iframe中,因此在尝试查找元素之前,请在seelnium测试中切换到iframe

要提取并打印文本Beanie Custom First和Red,您需要为位于()的元素的可见性引入WebDriverWait,并且您可以使用以下任一定位器策略:
>
使用CSS_SELECTOR和text属性:
>
print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "article.inner-article h1 > a.name-link[href='/shop/asd']"))).text)
印刷红:
print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "article.inner-article p > a.name-link[href='/shop/asd']"))).text)
使用XPATH和get\u attribute():
>
print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.XPATH, "//article[@class='inner-article']//h1/a[@class='name-link' and @href='/shop/asd']"))).get_attribute("innerHTML"))
印刷红:
print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.XPATH, "//article[@class='inner-article']//p/a[@class='name-link' and @href='/shop/asd']"))).get_attribute("innerHTML"))
注意:您必须添加以下导入:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
您可以找到有关如何使用Selenium-Python检索WebElement文本的相关讨论
链接到有用的文档:
get\u attribute()method获取元素的给定属性或属性
-
我有一个大的超文本标记语言电子邮件表,我正在尝试查找特定电子邮件的名称,然后在此元素中选择一个按钮。我可以通过XPATH轻松找到表体: 那么在这个表中有多行(tr),是否可以在所有表行中搜索文本? 我得到的最接近的结果是: 不幸的是,这无法定位元素。 我知道我可以简单地复制XPATH以定位特定的tr,但是出于自动化目的,我尝试传递一个字符串,然后在所有tr中搜索我的特定文本。
-
问题内容: 当我转到某个网页时,我正在尝试查找某个元素和一段文本: 这不起作用:( 它给出了复合类名的错误…) 所以我尝试了这个:( 但是我不确定它是否有效,因为我不太了解在selenium中使用CSS选择器的正确方法…) 找到span元素后,我想找到其中的数字 (内容) 。 CSS选择器,类名和查找元素文本的任何帮助都将非常有用! 谢谢。 哦! 我的另一个问题是,其中有多个确切的span元素,但
-
我正在学习powershell,并尝试编写一个脚本,通过字符串查找目录中的文件,然后对找到的文件进行查找和替换。我想将文件列表存储为一个变量,然后循环遍历文件并替换特定的字符串。这是我的脚本和错误,如果你有任何想法,它将非常感谢。谢谢! 错误 Get-Content:无法将参数绑定到参数“path”,因为它为null。在C:\scripts\script.ps1:5 char:18+(Get-Co
-
我在pager类中找到了元素, 也试过这个,在chrome中它用黄色标记我需要的东西,但selenium驱动程序找不到
-
问题内容: 我的网页中有9行6列的表格。我想搜索文本“ MakeGoodDisabled- Programwise_09_44_38_461(n)”并获取单元格的xpath。我使用了以下内容,但由于无法在页面上找到文本而失败。你能帮忙吗?我正在使用Selenium Webdriver Junit对此进行编码。 问题答案: 我的意图是在表中查找文本并在同一行中获取相应的下一列值。我以为我将用所需的列
-
我注意到,在selenium webdriver中查找xpath元素的函数text()在这种情况下不起作用: 如您所见,文本“Selecionar”位于按钮标记内,但在文本后还有其他标记,在本例中,当我尝试使用此模式通过xpath查找元素时://*[text()='Selecionar']未找到任何元素。 你们都知道在这种情况下,假设使用元素按钮的文本(因为在其他情况下,它将是唯一的选项),如何查