
使用Selenium和python在网页上查找文本,然后直接在其下方获取文本

我很抱歉,如果这是一个糟糕的解释,但我不知道如何更好地表达它。
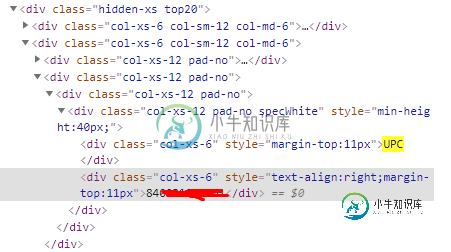
从图像中,你可以看到有一个叫做UPC的文本,在它的正下方有一个数字。我想把号码直接放在刚果爱国者联盟下面。我想通过在网站上搜索文本“UPC”来找到它,如果可能的话,直接在它下面找到它。
共有2个答案

注意:find\u element\u by.*命令不推荐使用。请改用find_element()
要打印编号840
您可以使用以下任一定位器策略:
>
使用selenium3方法和xpath:
print(driver.find_element_by_xpath("//div[contains(., 'UPC')]//following-sibling::div[1]").text)
使用selenium4方法和xpath:
print(driver.find_element(By.XPATH, "//div[contains(., 'UPC')]//following-sibling::div[1]").text)
理想情况下,您需要为位于()的元素的可见性引入WebDriverWait,并且您可以使用以下任一定位器策略:
>
使用selenium3方法和xpath:
print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.XPATH, "//div[contains(., 'UPC')]//following-sibling::div[1]"))).text)
使用selenium4方法和xpath:
print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.XPATH, "//div[contains(., 'UPC')]//following-sibling::div[1]"))).text)
您可以找到有关如何使用Selenium-Python检索WebElement文本的相关讨论

如果您是此页面的所有者,最好使用唯一的元素id来定位它们。无论如何,还有另一个解决办法。正如在selenium文档中编写的那样,您可以使用css选择器,只需使用“next element”css选择器“~”。它可以是这样的:
content = driver.find_element_by_css_selector('div:contains("UPC") ~ div')
您可以在这里阅读更多关于CSS选择器的信息
祝你好运
更新:正确答案是:
driver.find_element(By.XPATH, '//div[text()="UPC"]/following-sibling::div')
-
问题内容: 如何使用Selenium检查当前页面上是否存在给定的文本字符串? 问题答案: 代码是这样的:
-
要替换文本的元素:
-
问题内容: 当我转到某个网页时,我正在尝试查找某个元素和一段文本: 这不起作用:( 它给出了复合类名的错误…) 所以我尝试了这个:( 但是我不确定它是否有效,因为我不太了解在selenium中使用CSS选择器的正确方法…) 找到span元素后,我想找到其中的数字 (内容) 。 CSS选择器,类名和查找元素文本的任何帮助都将非常有用! 谢谢。 哦! 我的另一个问题是,其中有多个确切的span元素,但
-
问题内容: 我整天一直在搜寻,找不到答案,因此如果已经回答了,请提前道歉。 我正在尝试从大量不同的网站中获取所有可见的文本。原因是我要处理文本以最终对网站进行分类。 经过几天的研究,我认为硒是我最好的机会。我发现一种使用Selenium来捕获所有文本的方法,不幸的是同一文本被多次捕获: 该内部条件环路消除同一文本多次读取的问题的尝试-但是,它没有,只是作为计划在某些网页的工作。(这也使脚本慢很多)
-
问题内容: 我正在尝试使用Selenium WebDriver获取文本,这是我的代码。请注意,我不想使用XPath,因为在我的情况下,每次重新启动网页时ID都会更改。 我的代码: HTML: 我怎样才能解决这个问题? 问题答案: 你只想。 然后,您可以在验证 后 进行验证,不要尝试传递您 期望的 内容。
-
我试图使用Selenium WebDriver获取文本,这是我的代码。请注意,我不想使用XPath,因为在我的情况下,每次重新启动网页时都会更改ID。 我的代码: HTML: 我怎样才能解决这个问题?