
RavenDB Sql复制和Postgres uuid

我已经使用Postgres/Npgsql设置了Sql复制。
我们在Ravendb中使用GUID作为ID。只要Postgres中我的id列的类型是varchar,一切都正常,但如果我将其设置为uuid,这应该是与Guid匹配的正确类型,它就会失败。
对于id以外的其他列,它也会失败。
Postgres日志给我:
运算符不存在:uuid=字符34处的文本提示:没有与给定名称和参数类型匹配的运算符。您可能需要添加显式类型转换。
Postgres架构如下所示:
CREATE TABLE public.materiels
(
id uuid NOT NULL,
type character varying(50),
nummer integer,
...
CONSTRAINT materiels_pkey PRIMARY KEY (id)
)
将第一行替换为
id character varying(50) NOT NULL
将使其工作。
我的复制设置如下所示:
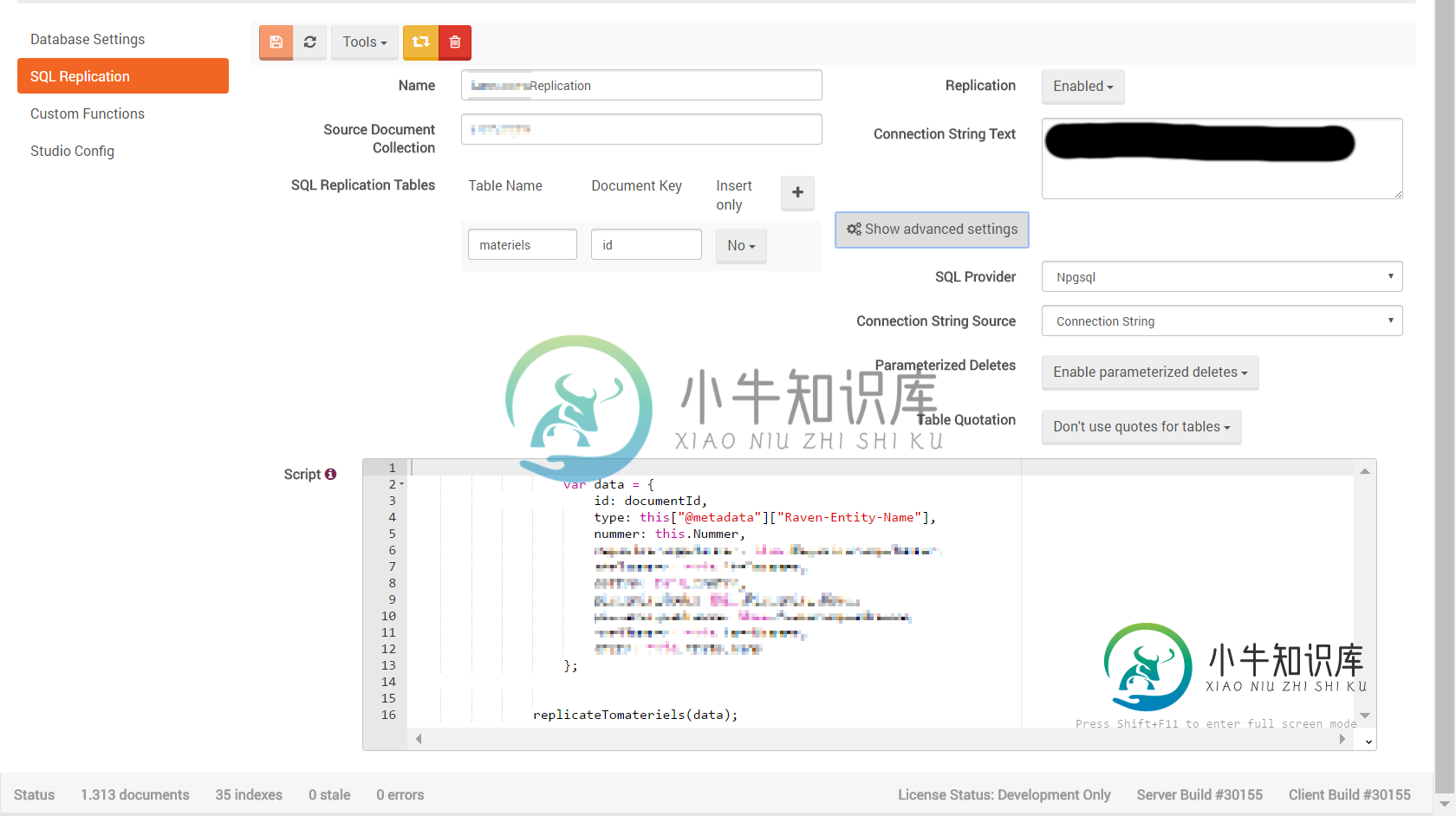
共有1个答案

如果要将UUID与文本进行比较,则需要为此创建操作符。解决错误的方法如下所示:
CREATE FUNCTION uuid_equal_text(uuid, text)
RETURNS boolean
LANGUAGE SQL IMMUTABLE
AS
$body$
SELECT $1 = $2::uuid
$body$;
CREATE OPERATOR =(
PROCEDURE = uuid_equal_text,
LEFTARG = uuid,
RIGHTARG = text);
编辑:这个问题的作者自己建议的替代解决方案:
CREATE CAST (text AS uuid)
WITH INOUT
AS IMPLICIT;
-
我对Cassandra来说是个新手,这篇文章解释了分片和复制,我被困在了一个点上- 我在本地计算机上配置了一个包含6个Cassandra节点的集群。我创建了一个新的关键字空间“TestKeyspace”,复制因子为6,并在关键字空间“Employee”中创建了一个表,主键是名为rid的自动增量数字。我无法理解这些数据将如何分区和复制。我想知道的是,既然我将复制因子保持为6,并且数据将分布在多个节点
-
问题内容: 您能告诉我Java克隆是什么意思吗?什么是深层复制和浅层复制,请举例说明 问题答案: 我强烈建议阅读有效的Java第二版中的第11项
-
本文向大家介绍C#复制和深度复制的实现方法,包括了C#复制和深度复制的实现方法的使用技巧和注意事项,需要的朋友参考一下 深度复制与浅表复制的区别在于,浅表复制只复制值类型的值,而对于实例所包含的对象依然指向原有实例。 运行结果: 一、List<T>对象中的T是值类型的情况(int 类型等) 对于值类型的List直接用以下方法就可以复制: 二、List<T>对象中的T是引用类型的情况(例如自定义的实
-
问题内容: 为什么以下内容没有将文件复制到目标文件夹? 问题答案: 如果您打算将找到的文件复制到/ home / shantanu / tosend中,则可以将cp的参数顺序颠倒过来: 注意:find命令使用 {} 作为匹配文件的占位符
-
与原始类型相比,对象的根本区别之一是对象是“通过引用”被存储和复制的,与原始类型值相反:字符串,数字,布尔值等 —— 始终是以“整体值”的形式被复制的。 如果我们稍微看一下复制值时发生了什么,就很容易理解了。 让我们从原始类型开始,例如一个字符串。 这里我们将 message 复制到 phrase: let message = "Hello!"; let phrase = message; 结果我
-
下面列出了完整的代码,我正在将数据透视表中DB10单元格的数据复制到Checklist表中的第N列--还要注意Checklist表中的行是动态的,每周增长3018行...这是减慢处理时间的部分(我对其进行了计时,在运行代码时完成处理需要大约8分钟)这部分是减慢处理速度的地方: 完整代码: