
在Cassandra中使用用户定义函数时读取超时

我们有一个单节点Cassandra集群(Apache),在AWS上有2个VCPU和大约16 GB的RAM。我们有大约28 GB的数据上传到Cassandra。
现在Cassandra可以很好地使用主键进行选择和分组查询,但是当使用用户定义的函数在非主键上使用聚合函数时,它会给出一个超时。
为了详细说明-我们对3年数据的年份、月份和日期进行了分区。现在,例如,如果两列是-Bill_ID和Bill_Amount,我们希望通过使用UDFBill_IDBill_Amount。
这里有点困惑,因为我相信如果信息说它收到了1个响应,为什么它应该在收到它的情况下给出超时消息?为什么我们会得到超时,而且只有在使用用户定义函数时才会这样?
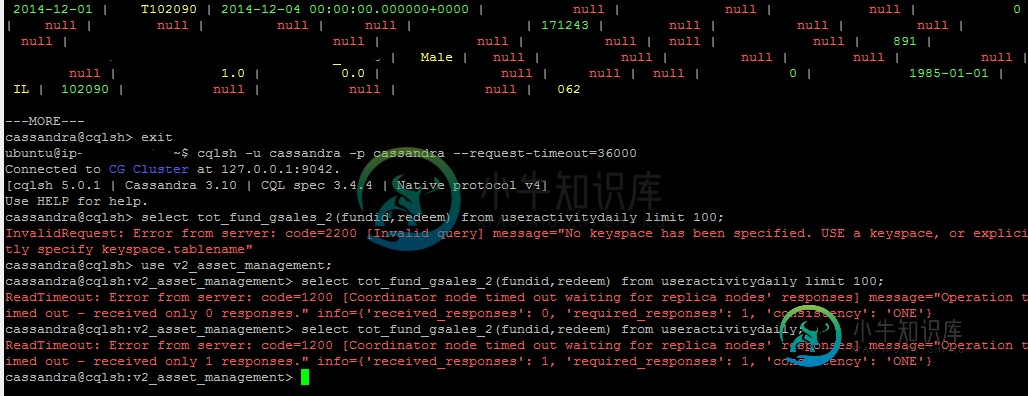
ReadTimeout: Error from server: code=1200 [Coordinator node timed out waiting for replica nodes' responses] message="Operation timed out - received only 1 responses." info={'received_responses': 1, 'required_responses': 1, 'consistency': 'ONE'}
我们将yaml文件中的读取超时时间增加到高达10分钟。
编辑-添加查询的屏幕截图。设置--请求超时之前显示的结果,并使用UDF发布该结果。该表有1.5亿行,超过1095个分区,仅用于3年的数据,主键是年、日和月。
共有1个答案

尝试在客户端增加超时,例如cqlsh:
cqlsh--请求超时=3600
-
我在我的cassandra db中实现了用户定义的聚合函数average,如链接https://docs.datastax.com/en/dse/5.1/cql/cql/cql_using/usecreateuda.html所述 创建或替换对空输入调用的函数avgState(state Tuple ,val int)返回元组 语言Java为“if(val!=NULL){state.SetInt(0
-
我正在测试Cassandra中的UDF/UDA特性,看起来不错。但我在使用它时没有什么问题。 1) 在卡桑德拉。yaml,有人提到启用沙箱是为了避免邪恶代码,那么我们是否违反了规则,启用此支持(标志)会产生什么后果? 2)与在客户端读取数据和编写聚合逻辑相比,在Cassandra中使用UDF/UDA有什么优势? 3)此外,除了JAVA之外,是否有一种语言支持可用于编写UDF/UDA的nodejs、
-
问题内容: 我想使用串行com端口进行通信,并且每次调用read函数调用时都想实现超时。 编辑: 我正在使用Linux OS。如何使用选择函数调用实现? 问题答案: select()有5个参数,首先是最高的文件描述符+ 1,然后是fd_set用于读取,一个用于写入,一个用于异常。最后一个参数是struct timeval,用于超时。错误时返回-1,超时时返回0或设置的集合中文件描述符的数量。
-
我对Spring Boot cassandra web应用程序有问题。随着数据的增长,它开始出现,现在它是一个非常常见的场景。 所有查询有时都不起作用,返回。几秒钟后它又开始工作了,几秒钟后它就不工作了。所以web应用程序不断返回或响应。相同的查询始终在中工作。 我正在使用: Spring启动启动程序 sping-boo-starter-data-cassandra#2.1.3 Cassandra
-
我对卡桑德拉的数据建模有一个疑问,希望能在这里提出一些建议。 我们正在尝试构建一个多租户应用程序,我们希望数据结构由用户定义。用户可以定义数据源、字段数量、数据类型、顺序等,然后基于此结构上载数据。既然Cassandra不支持混合数据类型列表,我们如何在Cassandra之上设计这样的应用程序呢。当前集合类型为映射(相同类型)/集/列表(相同类型)。此外,是否可以基于用户定义的实体查询数据? 目前
-
谁能解释一下为什么我的Cassandra集群中每隔4-5分钟就会出现读取超时。我几乎可以始终如一地看到这一点,并能够始终如一地再现这一点。 读取吞吐量保持在每秒 1 个请求,集群中没有发生写入或压缩。读取超时在 cassandra.yaml 文件中配置为 5 秒。我正在使用datastax java驱动程序2.1.14。 超时期间的跟踪不起作用。在cqlsh中第二次手动读取同一行密钥成功。看看这个