
如何正确调用minimax方法(使用alpha-beta修剪)

这是我的极小极大方法,它实现了alpha beta修剪和记忆:
public int[] newminimax499(int a, int b){
int bestPos=-1;
int alpha= a;
int beta= b;
int currentScore;
//boardShow();
String stateString = "";
for (int i=0; i<state.length; i++)
stateString += state[i];
int[] oldAnswer = oldAnswers.get(stateString);
if (oldAnswer != null)
return oldAnswer;
if(isGameOver2()!='N'){
int[] answer = {score(), bestPos};
oldAnswers.put (stateString, answer);
return answer;
}
else{
for(int x:getAvailableMoves()){
if(turn=='O'){ //O is maximizer
setO(x);
//System.out.println(stateID++);
currentScore = newminimax499(alpha, beta)[0];
//revert(x);
if(currentScore>alpha){
alpha=currentScore;
bestPos=x;
}
/*if(alpha>=beta){
break;
}*/
}
else { //X is minimizer
setX(x);
//System.out.println(stateID++);
currentScore = newminimax499(alpha, beta)[0];
//revert(x);
if(currentScore<beta){
beta=currentScore;
bestPos=x;
}
/*if(alpha>=beta)
break;*/
}
revert(x);
if(alpha>=beta)
break;
}
}
if(turn=='O'){
int[] answer = {alpha, bestPos};
oldAnswers.put (stateString, answer);
return answer;
}
else {
int[] answer = {beta, bestPos};
oldAnswers.put (stateString, answer);
return answer;
}
}
作为一个测试游戏,在我的主要方法中,我在某处放置一个X(X是玩家),然后调用newminimax499查看我应该在哪里放置O(计算机):
public static void main(String[] args) {
State3 s=new State3(3);
int [] result=new int[2];
s.setX(4);
result=s.newminimax499(Integer.MIN_VALUE, Integer.MAX_VALUE);
System.out.println("Score: "+result[0]+" Position: "+ result[1]);
System.out.println("Run time: " + (endTime-startTime));
s.boardShow();
}
}
该方法返回计算机应该在何处播放它的O(在本场景中为6),因此我按照指示放置O,自己播放X,调用newminimax499并再次运行代码以查看O要在何处播放,依此类推。
public static void main(String[] args) {
State3 s=new State3(3);
int [] result=new int[2];
s.setX(4);
s.setO(6);//Position returned from previous code run
s.setX(2);
s.setO(8);//Position returned from previous code run
s.setX(3);
result=s.newminimax499(Integer.MIN_VALUE, Integer.MAX_VALUE);
System.out.println("Score: "+result[0]+" Position: "+ result[1]);
System.out.println("Run time: " + (endTime-startTime));
s.boardShow();
}
在这次特殊的运行之后,我得到了结果
Score: 10 Position: 7
这很好。然而,在我的GUI中,这不是newminimax的调用方式。在那里,电路板不会在每次放置新的X或O时重置。如果我像前面的例子那样将其放在main方法中,它会像这样(请记住,它是完全相同的输入序列):
public static void main(String[] args) {
State3 s=new State3(3);
int [] result=new int[2];
s.setX(4); //Player makes his move
result=s.newminimax499(Integer.MIN_VALUE, Integer.MAX_VALUE);//Where should pc play?
s.setO(result[1]);//PC makes his move
s.setX(2);//Player makes his move
result=s.newminimax499(Integer.MIN_VALUE, Integer.MAX_VALUE);//Where should PC make his move?
s.setO(result[1]);//PC makes his move
s.setX(3);//Player makes his move
result=s.newminimax499(Integer.MIN_VALUE, Integer.MAX_VALUE);
System.out.println("Score: "+result[0]+" Position: "+ result[1]);
System.out.println("Run time: " + (endTime-startTime));
s.boardShow();
}
现在,当以这种方式调用该方法时(在GUI中也是这样调用的),它将返回:
Score: 0 Position: 5
这意味着它没有采取获胜的动作,而是阻止了对手。以这种方式玩了几场游戏后,很明显PC实际上输了。那么为什么这两种调用newximax499的方式会返回不同的结果呢?
这是它在GUI上的外观:
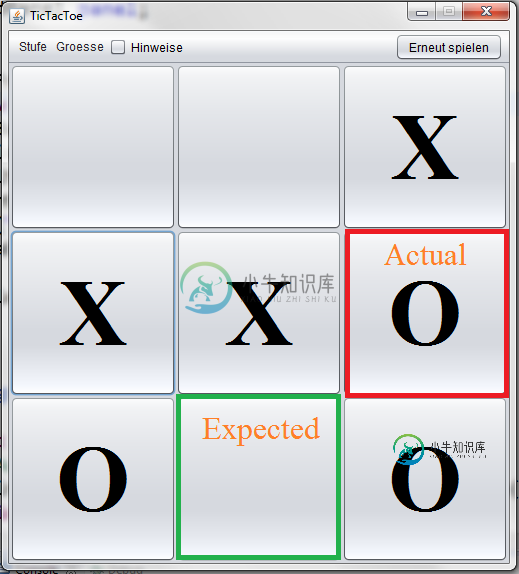
注意:运行程序所需的所有方法都可以在本文中找到。
共有2个答案

在玩弄了一堆想法后,我终于找到了答案,所以不妨把它贴出来。这里讨论的方法newminimax499试图实现记忆和alpha-beta修剪。出于某种原因,这两个实用程序似乎不兼容(或者至少我对这两个实用程序的实现使它们不兼容)。删除与记忆相关的部分后,该方法成为纯alpha-beta修剪minimax算法,运行良好,如下所示:
public int[] newminimax499(int alpha, int beta){
int bestPos=-1;
int currentScore;
if(isGameOver2()!='N'){
int[] answer = {score(), bestPos};
return answer;
}
else{
for(int x:getAvailableMoves()){
if(turn=='O'){ //O is maximizer
setO(x);
//System.out.println(stateID++);
currentScore = newminimax499(alpha, beta)[0];
if(currentScore>alpha){
alpha=currentScore;
bestPos=x;
}
}
else { //X is minimizer
setX(x);
//System.out.println(stateID++);
currentScore = newminimax499(alpha, beta)[0];
if(currentScore<beta){
beta=currentScore;
bestPos=x;
}
}
revert(x);
if(alpha>=beta)
break;
}
if(turn=='O'){
int[] answer = {alpha, bestPos};
return answer;
}
else {
int[] answer = {beta, bestPos};
return answer;
}
}
}
这种方法现在不仅可以工作(无论您在主方法中如何调用),而且它也比具有记忆的极小值快得多。该方法仅在7秒内计算4x4游戏中的第二步。而实现记忆的极小值在大约23秒内计算出来。

你在这里遇到的问题就像在国际象棋中使用换位表和阿尔法贝塔一样。我必须反驳你,因为它们不兼容!
正如我之前多次建议的那样,在尝试实现某些东西之前,请阅读相应的象棋编程wiki文章!
为了使memo和AB协同工作,您必须为memo表中的每个职位保存一个标志,以区分alpha cut节点、beta cut节点和precise节点。
相信我,我从经验中知道他们一起工作;)
-
在我的方法newminimax49中,我有一个minimax算法,它利用了本文中建议给我的记忆和其他一般性改进。该方法使用一个简单的启发式电路板评估函数。我的问题基本上是关于alpha-beta修剪,即我的minimax方法是否使用alpha-beta修剪。据我所知,我相信这是真的,然而,我用来实现它的东西似乎太简单了,不可能是真的。此外,其他人建议我使用alpha-beta剪枝,正如我所说的,我
-
我试图让Alpha-beta修剪工作,但与我的Minimax函数相比,它给了我完全错误的动作。这是我的极大极小函数,它现在工作得很好。 这是我的Alphabeta修剪函数 两者都使用相同的评估,不确定这里出了什么问题。谢谢你的帮助。
-
我目前正在从事我的第一个C项目,并选择使用基于Minimax的AI编写一个Connect Four(又名Score 4),更具体地说是基于Alpha-Beta修剪方法。 到目前为止,我了解到AB修剪包含在一个递归算法中,该算法考虑了一个alpha和一个beta参数,这是您在游戏树中找不到的“极限”。此外,我们定义了最大化和最小化玩家,前者是第一个开始玩游戏的玩家。最后,还有一个“深度”,我把它理解
-
我在写国际象棋的最小化算法。 对于不带alpha-beta修剪的minimax和带alpha-beta修剪的minimax,我得到了不同的最终结果值。 下面是我的伪代码。有人能帮我吗? 极小极大() αβ() 董事会代表董事会。对于每一次移动,我都在传递的董事会对象的副本上移动,然后将这个临时董事会传递给进一步的调用。 evaluateBoard(董事会b)接收董事会并根据给定董事会情景计算分数。
-
我试图在我的极小值中添加阿尔法贝塔修剪,但我不明白我哪里出错了。 目前,我正在经历5000次迭代,根据一个朋友的说法,我应该经历大约16000次迭代。当选择第一个位置时,它返回-1(一个损失),而它应该能够在这一点上肯定返回0(一个平局),因为它应该能够从一个空的棋盘中抽签,但是我看不到我哪里出错了,因为我跟着我的代码走似乎没问题 奇怪的是,如果我在我的检查中切换返回α和β(以实现返回0),计算机
-
我正在使用minimax算法为connect four编写AI。为了增加深度,我正在使用alpha-beta修剪。然而,我的代码得到了错误的结果。我很难找出哪里出了问题。