
在我的python云函数中,我应该避免哪些事情来避免内存泄漏?

我的python Cloud函数每秒引发大约0.05个内存错误-每秒调用大约150次。我感觉我的函数留下了内存残差,一旦实例处理了许多请求,就会导致实例崩溃。为了使函数实例在每次被调用时不会占用“更多的分配内存”,您应该做或不应该做什么?我被指向文档,了解到我应该删除所有临时文件,因为这是在内存中编写的,但我认为我没有编写任何文件。
我函数的代码可以总结如下。
- 全局上下文:在Google云存储上获取一个文件,其中包含已知的机器人程序用户代理列表。实例化一个错误报告客户端
我相信我的实例正在逐渐消耗所有可用内存,因为我在Stackdriver中完成了以下图表:
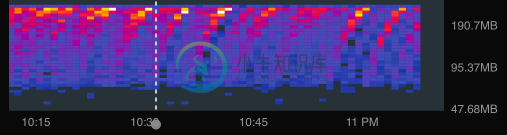
这是我的云函数实例内存使用的热图,红色和黄色表示我的大多数函数实例都在使用这一范围的内存。由于似乎出现的循环,我将其解释为逐渐填满实例的内存,直到它们崩溃并生成新实例。如果我提高分配给函数的内存,这个循环将保持不变,它只会提高循环后的内存使用上限。
这些请求包含有助于在电子商务网站上实施跟踪的参数。既然我复制了它,可能会有一个反模式,我在迭代时修改表单['products'],但我认为这与内存浪费无关?
from json import dumps
from datetime import datetime
from pytz import timezone
from google.cloud import storage
from google.cloud import pubsub
from google.cloud import error_reporting
from unidecode import unidecode
# this is done in global context because I only want to load the BOTS_LIST at
# cold start
PROJECT_ID = '...'
TOPIC_NAME = '...'
BUCKET_NAME = '...'
BOTS_PATH = '.../bots.txt'
gcs_client = storage.Client()
cf_bucket = gcs_client.bucket(BUCKET_NAME)
bots_blob = cf_bucket.blob(BOTS_PATH)
BOTS_LIST = bots_blob.download_as_string().decode('utf-8').split('\r\n')
del cf_bucket
del gcs_client
del bots_blob
err_client = error_reporting.Client()
def detect_nb_products(parameters):
'''
Detects number of products in the fields of the request.
'''
# ...
def remove_accents(d):
'''
Takes a dictionary and recursively transforms its strings into ASCII
encodable ones
'''
# ...
def safe_float_int(x):
'''
Custom converter to float / int
'''
# ...
def build_hit_id(d):
'''concatenate specific parameters from a dictionary'''
# ...
def cloud_function(request):
"""Actual Cloud Function"""
try:
time_received = datetime.now().timestamp()
# filtering bots
user_agent = request.headers.get('User-Agent')
if all([bot not in user_agent for bot in BOTS_LIST]):
form = request.form.to_dict()
# setting the products field
nb_prods = detect_nb_products(form.keys())
if nb_prods:
form['products'] = [{'product_name': form['product_name%d' % i],
'product_price': form['product_price%d' % i],
'product_id': form['product_id%d' % i],
'product_quantity': form['product_quantity%d' % i]}
for i in range(1, nb_prods + 1)]
useful_fields = [] # list of keys I'll keep from the form
unwanted = set(form.keys()) - set(useful_fields)
for key in unwanted:
del form[key]
# float conversion
if nb_prods:
for prod in form['products']:
prod['product_price'] = safe_float_int(
prod['product_price'])
# adding timestamp/hour/minute, user agent and date to the hit
form['time'] = int(time_received)
form['user_agent'] = user_agent
dt = datetime.fromtimestamp(time_received)
form['date'] = dt.strftime('%Y-%m-%d')
remove_accents(form)
friendly_names = {} # dict to translate the keys I originally
# receive to human friendly ones
new_form = {}
for key in form.keys():
if key in friendly_names.keys():
new_form[friendly_names[key]] = form[key]
else:
new_form[key] = form[key]
form = new_form
del new_form
# logging
print(form)
# setting up Pub/Sub
publisher = pubsub.PublisherClient()
topic_path = publisher.topic_path(PROJECT_ID, TOPIC_NAME)
# sending
hit_id = build_hit_id(form)
message_future = publisher.publish(topic_path,
dumps(form).encode('utf-8'),
time=str(int(time_received * 1000)),
hit_id=hit_id)
print(message_future.result())
return ('OK',
200,
{'Access-Control-Allow-Origin': '*'})
else:
# do nothing for bots
return ('OK',
200,
{'Access-Control-Allow-Origin': '*'})
except KeyError:
err_client.report_exception()
return ('err',
200,
{'Access-Control-Allow-Origin': '*'})
共有1个答案

有一些事情你可以尝试(理论上的答案,我还没有玩过CFs):
>
显式删除您在机器人程序处理路径上分配的临时变量,这些变量可能相互引用,从而阻止内存垃圾收集器释放它们(请参阅)https://stackoverflow.com/a/33091796/4495081)例如:nb\u产品,不需要的,表格,新表格,友好的名字。
如果不需要的总是相同的,请将其改为全局。
删除表单,然后将其重新分配给新表单(旧的表单对象保留);另外,删除新表单实际上不会节省太多,因为对象仍然由表单引用。即改变:
form = new_form
del new_form
进入
del form
form = new_form
在发布主题后返回之前,显式调用内存垃圾收集器。我不确定这是否适用于CFs,或者调用是否立即有效(例如,在GAE中,它不是,请参阅在App Engine后端实例上完成请求后何时释放内存?)。这也可能是过分的,可能会损害CF的性能,看看它是否/如何为您工作。
gc.collect()
-
问题内容: 有时是有用的,例如,如果我为网站上的所有链接(例如选择器)定义了通用样式,但是当我要覆盖某些规则时,可以有以下选择: 使用更具体(更长)的选择器 采用 哪种方法更好,可能有一些指导原则? 问题答案: 使用非常,非常谨慎- 它会覆盖刚才的一切,甚至是内联样式和混乱在低于显而易见的方式与样式规则“梯级”,让CSS的名字。它很容易使用不当,而且容易成倍增加,尤其是在滥用时。您可以轻松地得出一
-
问题内容: 所以我有这个C ++程序,它是通过Java程序中的JNI调用的,代码如下: 在倒数第二行中,从不释放而是返回,是否会导致最终的内存泄漏?反正有解决这个问题的方法吗? 还有可能不是返回字符串而是返回布尔值(由LogonUser函数返回),而不是jstring,而是添加了要在方法中传递的“ errormessage”引用,并更新了它?我的Java程序能否看到“ errormessage”的
-
问题内容: 有效的Java说: 内存泄漏的第三个常见来源是侦听器和其他回调。如果在客户端注册回调但未显式注销的情况下实现API,除非您采取某些措施,否则它们会累积。确保回调被及时垃圾回收的最佳方法是仅存储对其的弱引用,例如,通过仅将它们作为键存储在WeakHashMap中。 我是Java的初学者。有人可以教我如何在回调中创建弱引用,并告诉我它们如何解决内存泄漏问题吗?谢谢。 问题答案: 阅读这篇文
-
本文向大家介绍避免 Android中Context引起的内存泄露,包括了避免 Android中Context引起的内存泄露的使用技巧和注意事项,需要的朋友参考一下 Context是我们在编写Android程序经常使用到的对象,意思为上下文对象。 常用的有Activity的Context还是有Application的Context。Activity用来展示活动界面,包含了很多的视图,而视图又含有图片
-
我读了很多关于如何避免Android内存泄漏的文章,但我仍然不太确定我是否做对了。 我的应用程序由一个活动组成 问题1:这够了吗? 让我困惑的是,你可以在网上找到一个经典的“不去”的例子(http://www.curious-creature.org/2008/12/18/avoid-memory-leaks-on-android/): 我认为,一旦创建完成, 检索上下文,将其传递给手动创建的查看
-
我是android开发的新手,我刚刚从以下链接读到了Romain Guy的“避免android内存泄漏” http://www.curious-creature.org/2008/12/18/avoid-memory-leaks-on-android/ 然后我在我的android模拟器上用他著名的代码片段做了一个小测试 此代码应该在更改方向时泄漏第一个活动上下文。因此,我在emulator中运行了