
如何在R中正确裁剪()栅格数据范围

我正在尝试裁剪一些栅格数据并进行一些计算(特别是获得平均海面温度)。
但是,当比较在进行计算之前裁剪光栅数据的范围时,我得到的结果与在裁剪结果数据之前进行计算的结果相同。
光栅数据的原始范围是-180、180、90、90(xmin、xmax、ymin、ymax),我需要将其裁剪到由纬度和经度坐标定义的任何所需区域。
这是我正在使用的脚本进行测试:
library(raster) # Crop raster data
library(stringr)
# hadsstR functions ----------------------------------------
load_hadsst <- function(file = "./HadISST_sst.nc") {
b <- brick(file)
NAvalue(b) <- -32768 # Land
return(b)
}
# Transform basin coordinates into numbers
morph_coords <- function(coords){
coords[1] = ifelse(str_extract(coords[1], "[A-Z]") == "W", - as.numeric(str_extract(coords[1], "[^A-Z]+")),
as.numeric(str_extract(coords[1], "[^A-Z]+")) )
coords[2] = ifelse(str_extract(coords[2], "[A-Z]") == "W", - as.numeric(str_extract(coords[2], "[^A-Z]+")),
as.numeric(str_extract(coords[2], "[^A-Z]+")) )
coords[3] = ifelse(str_extract(coords[3], "[A-Z]") == "S", - as.numeric(str_extract(coords[3], "[^A-Z]+")),
as.numeric(str_extract(coords[3], "[^A-Z]+")) )
coords[4] = ifelse(str_extract(coords[4], "[A-Z]") == "S", - as.numeric(str_extract(coords[2], "[^A-Z]+")),
as.numeric(str_extract(coords[4], "[^A-Z]+")) )
return(coords)
}
# Comparison test ------------------------------------------
hadsst.raster <- load_hadsst(file = "~/Hadley/HadISST_sst.nc")
x <- hadsst.raster
nms <- names(x)
months <- c("01","02","03","04","05","06","07","08","09","10","11","12")
coords <- c("85E", "90E", "5N", "10N")
coords <- morph_coords(coords)
years = 1970:1974
range = 5:12
# Crop before calculating mean
x <- crop(x, extent(as.numeric(coords[1]), as.numeric(coords[2]),
as.numeric(coords[3]), as.numeric(coords[4])))
xMeans <- vector(length = length(years)-1,mode='list')
for (ix in seq_along(years[1:length(years)])){
xMeans[[ix]] <- mean(x[[c(sapply(range,function(x) grep(paste0(years[ix],'.',months[x]),nms)))]], na.rm = T)
}
mean.brick1 <- do.call(brick,xMeans)
# Calculate mean before cropping
x <- hadsst.raster
xMeans <- vector(length = length(years)-1,mode='list')
for (ix in seq_along(years[1:length(years)])){
xMeans[[ix]] <- mean(x[[c(sapply(range,function(x) grep(paste0(years[ix],'.',months[x]),nms)))]], na.rm = T)
}
mean.brick2 <- do.call(brick,xMeans)
mean.brick2 <- crop(mean.brick2, extent(as.numeric(coords[1]), as.numeric(coords[2]),
as.numeric(coords[3]), as.numeric(coords[4])))
# Compare the two rasters
mean.brick1 - mean.brick2
这是平均值的输出。brick1-平均值。砖2:
class : RasterBrick
dimensions : 5, 5, 25, 5 (nrow, ncol, ncell, nlayers)
resolution : 1, 1 (x, y)
extent : 85, 90, 5, 10 (xmin, xmax, ymin, ymax)
coord. ref. : +proj=longlat +datum=WGS84
data source : in memory
names : layer.1, layer.2, layer.3, layer.4, layer.5
min values : 0, 0, 0, 0, 0
max values : 0, 0, 0, 0, 0
如您所见,两个光栅砖完全相同,这对于任意选择坐标都是不可能的,如下面的小矩阵所示:
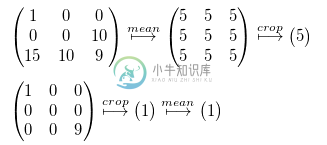
我做错了什么吗?在计算之前裁剪数据应该会明确地给我不同的结果。
共有1个答案

好的,我将继续我在上一个问题中的帖子:
我们从完整的hadst开始。光栅brick(为了有一个可复制的示例,可以在我之前的回答中使用我的解决方案的第一部分创建)。
因此,该数据集的维度为180、360、516,即180行、360列和516个时间层。
从技术上讲,光栅是一个矩阵,这可能是它的样子:
只是一堆矩阵层(准确地说是516),其中每个像素完全对齐。这里我只有三个示例层,其余的由三个点表示。
因此,如果我们进行时间平均,我们基本上提取单个像素的所有值,并取它们的平均值(或任何其他平均操作)。此处用红色方块表示。
这也说明了为什么裁剪不影响时间平均:
如果我们说橙色方块是我们感兴趣的范围,并且我们在平均之前执行裁剪操作,那么我们基本上会丢弃这个方块周围的所有值。之后,我们再次获取所有层上每个像素的所有值,并执行平均值。
现在应该清楚了,为什么丢弃橙色正方形周围的像素无关紧要。您还可以计算它们的平均值,然后丢弃这些值,只剩下橙色正方形的值。如果你已经确定不需要它们进行进一步的计算,那就没有任何实际意义了。无论如何,正方形内的值不会受到影响。
当我们谈论空间平均时,它通常意味着对单个层内的像素进行平均,在这种情况下,可能是对橙色矩形内的值进行平均。
这有两种常见的操作
- 焦点平均(也称为邻域平均)
- 聚合
焦点平均将为每个像素取定义数量的相邻像素的所有值的平均值(最常见的是3x3正方形,其中要定义的像素是中心像素)。
聚合实际上是取一些像素并将它们组合成一个更大的像素。这意味着不仅该像素的值将被平均,而且生成的光栅将具有更少的单个像素和更粗糙的分辨率。
好的,来为您提供实际的解决方案:
我假设您有一个由范围aoi定义的感兴趣区域:
aoi <- extent(xmin,xmax,ymin,ymax)
您要做的第一件事是裁剪初始块以减少计算负担:
hadsst.raster_crp <- crop(hadsst.raster,aoi)
下一步是时间平均,我们使用我在另一篇文章的解决方案中定义的函数:
hadsst.raster_crp_avg <- hadSSTmean(hadsst.raster_crp, 1969:2011, first.range = 11:12, second.range = 1:4)
好了,现在你有了你感兴趣区域的时间平均值。下一步取决于你的最终目标是什么。据我所知,你只需要为你感兴趣的区域建立一个时间平均值。
如果是这种情况,那么现在可能是离开实际光栅域并继续使用基本R的正确时间:
res <- lapply(1:nlayers(hadsst.raster_crp_avg),function(ix) mean(as.matrix(hadsst.raster_crp_avg[[ix]])))
这将为您提供一个列表,其中包含与砖块hadsst.raster_crp_avg一样多的元素。
使用lappy,我们迭代各个层,将每个层转换为一个矩阵,然后计算所有元素的平均值,为整个感兴趣区域的每个平均时间步留下一个值。
更进一步,您可以使用unlist将其转换为向量并将其添加到data.frame或执行您喜欢的任何其他操作。
希望这是清楚的,这就是你想要的。
最好的
-
我有50多个需要裁剪的光栅文件(ASCII格式)。我已经以ASCII格式从ArcMap导出了遮罩,并将其加载到R中。如何使其适用于一行中的所有光栅,并以与之前相同的名称导出它们(当然是在不同的文件夹中,以避免覆盖)? 我知道光栅软件包中有裁剪功能,但到目前为止我从未使用过。我只是把它们堆放起来做进一步的栖息地分析。 到目前为止,我的代码:
-
我正在尝试使用R中的“grainchanger”包将分辨率更高的光栅聚合为分辨率更高的光栅。 我有10公里的英国网格轮廓,我已经从shapefile转换为光栅。 我还有一张英国的栅格土地覆盖图。 我需要查看土地覆盖图中每10公里见方的土地覆盖%s。 当我尝试使用grainchanger包聚合此内容时,会出现以下错误: 我想这是因为我的10km栅格光栅是正方形,而土地覆盖地图没有填充。 如何更改土地
-
问题内容: JDK的String.trim()方法非常幼稚,仅删除ascii控制字符。 Apache Commons的StringUtils.strip()稍好一些,但使用了JDK的Character.isWhitespace(),后者无法将不间断的空格识别为whitespace。 那么,用Java修剪字符串的最完整,与Unicode兼容,安全和正确的方法是什么? 顺便说一句,有没有比我应该使用的
-
我被指派了从中剪裁光栅的任务。来自的nc文件。tif文件。 编辑(来自注释):我想提取临时值。来自的信息。nc,因为我需要检查特定区域的年平均温度。要进行比较,必须在完全相同的区域进行比较。这个nc文件比之前选中的区域大,因此我需要将其“剪裁”到。如果我有。这个tif数据的格式为0 | 1,其中为0(或.tif小于.nc)。nc数据应“剪辑”。最后,我想保留。nc数据,但在范围内。tif同时仍保留
-
本文向大家介绍R加载多层栅格,包括了R加载多层栅格的使用技巧和注意事项,需要的朋友参考一下
-
我在javafx上工作,要求是当任何按钮在屏幕上被点击时,屏蔽/剪辑特定的屏幕。当按钮被点击时,在我们收到响应之前,我应该限制用户访问页面中的其他选项/按钮。用户需要等待,直到请求得到处理。当请求得到处理时,我需要禁用/屏蔽/剪辑我的主窗口(我不确定确切的术语)。我怎么能这样做? 我用的是java 1.7_25