
AWS X射线(带SailsJS)没有将东西记录在正确的跟踪中?

我正在尝试在我的SailsJS应用程序中使用AWS X-Ray。我注意到缺少子段-我通过AWSXRay添加了自定义跟踪。CaptureAyncFunc,但注意到它们丢失了。经过仔细检查,我认为他们实际上找到了不同的线索。假设我稍后调用登录API,然后调用另一个API。我注意到我的登录API跟踪很奇怪
请注意,在请求应该结束后,会有相当多的调用。
这些请求实际上应该在另一个部分中:
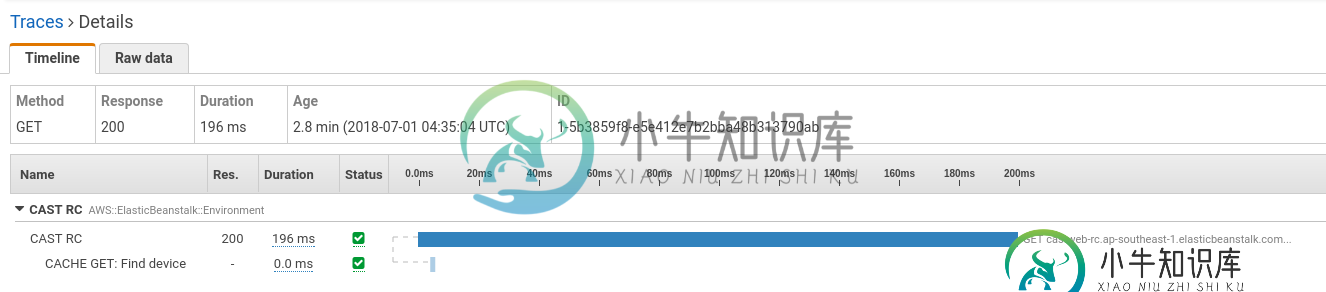
我认为它们应该出现在查找设备子段之后。为什么分段会如此混乱?
我的设置:在http中。js,
const AWSXRay = require('aws-xray-sdk');
const xrayEnabled = process.env.AWS_XRAY === 'yes'
module.exports.http = {
middleware: {
order: [
'startRequestTimer',
'cookieParser',
'session',
'myRequestLogger',
'bodyParser',
'handleBodyParserError',
'compress',
'methodOverride',
'poweredBy',
'awsXrayStart',
'router',
'awsXrayEnd',
'www',
'favicon',
'404',
'500',
],
awsXrayStart: xrayEnabled ? AWSXRay.express.openSegment(`cast-${process.env.NODE_ENV || 'noenv'}`) : (req, res, next) => next(),
awsXrayEnd: xrayEnabled ? AWSXRay.express.closeSegment() : (req, res, next) => next(),
然后我把我的promise包装成:
instrumentPromise(promise, name, metadata = {}) {
if (this.isXrayEnabled()) {
return new Promise((resolve, reject) => {
AWSXRay.captureAsyncFunc(name, (subsegment) => {
if (!subsegment) console.warn(`[XRAY] Failed to instrument ${name}`)
Object.keys(metadata).forEach(k => {
if (subsegment) subsegment.addMetadata(k, metadata[k])
})
console.time(`[XRAY TIME] ${name}`)
promise
.then((data) => {
if (subsegment) subsegment.close()
console.timeEnd(`[XRAY TIME] ${name}`)
resolve(data)
})
.catch(err => {
if (subsegment) subsegment.close()
console.timeEnd(`[XRAY TIME] ${name}`)
reject(err)
})
})
})
}
return promise
}
这里有我遗漏的信息吗?我做错了什么?
我尝试了手动模式,它更可靠,但我必须手动传递段。自动模式有什么问题?我有点猜测,它与异步自然节点没有很好的配合?就像SDK不能区分不同的异步请求一样?并且可能在错误的位置关闭或跟踪段?也就是说。。。它应该与express一起工作,为什么它不能按预期工作。。。
另一件事是X-Ray如何正确跟踪共享的mysql连接池?不同的段将使用相同的mysql池。我假设这根本无法正常工作?
共有1个答案

您遇到的问题似乎与CLS如何使用Promise处理上下文绑定有关。此PR中引入了一个选择加入的promise补丁https://github.com/aws/aws-xray-sdk-node/pull/11.它对repros和修复进行了全面讨论。这应该可以解决子段附加到错误跟踪的问题。
SDK确实支持捕获池。查询。您可以在这里看到示例https://www.npmjs.com/package/aws-xray-sdk-mysql.
-
我有一个Kafka实例和一个简单的Spring Boot应用程序,其中有一个REST控制器和一个bean。控制器接受一个简单的消息,并通过将其发送给Kafka。我想让记录一条信息消息,但缺少跟踪id和span id。在我看来,它应该包括在日志中。 我使用SpringCloud侦探和SpringKafka启动器。 消息本身通过Kafka主题成功发送到另一个正确获取跟踪标识的Spring Boot应用
-
为了使消费者保持活动(非常长的可变长度处理),我在后台线程中实现了一个空的poll()调用,如果我在poll()之间花费了太多时间,它将防止代理重新平衡。我已经将我的轮询间隔设置得很长,但我不想为了越来越长的处理而一直增加它。 什么是正确的投票没有记录?当前我正在调用poll(),然后重新查找poll call()中返回的每个分区的最早偏移量,这样主线程在处理完前面的消息后就可以正确地读取这些偏移
-
我希望通过使用一个新表来存储一个日志,其中记录了在每次更新/插入中进行更改的用户、日期以及任何更改的内容,从而实现对我的一个模型实体的历史记录跟踪/审核。 我使用EclipseLink作为我的JPA提供者,但我不想使用它的历史策略,因为提供者将来可能会改变。出于同样的原因,我不能使用Hibernate Envers。 我研究了SpringData提供的审计支持,但它似乎非常基本,它只允许您存储创建
-
我尝试了多种方法,但似乎没有任何效果 这就是我所做的, 创建Cloud9实例,启动maven应用程序,添加aws sdk java、x-ray core、x-ray instrumentor、x-ray sdk依赖项,创建DynamoDB客户端运行应用程序,插入数据,但未找到错误子段。手动添加段,错误消失,但没有跟踪 创建Spring Boot应用程序,添加了相同的依赖项,添加了Xray serv
-
问题内容: 有人问我是否可以跟踪MySQL数据库中记录的更改。因此,更改字段后,可以使用旧的还是新的字段以及日期。有没有功能或通用技术可以做到这一点? 如果是这样,我正在考虑做这样的事情。创建一个名为的表。它包含与 主 表相同的字段,但以新旧为前缀,但仅适用于那些实际更改的字段和a 。它将以索引。这样,可以运行报告以显示每个记录的历史记录。这是个好方法吗?谢谢! 问题答案: 真微妙 如果业务要求是
-
我有一些启用了跟踪的Python Lambda函数,它们是这样开始的: 有了这个跟踪,每个Lambda函数本身都可以工作,我可以看到通过boto3对DynamoDB或Kinesis的子服务调用。 但是如何在一个跟踪中将各种Lambda函数连接在一起呢?我正在考虑在第一个函数中生成一个唯一的字符串,并将其写入存储在Kinesis中的消息中。然后,另一个函数将从动觉信息中提取字符串并再次跟踪它。 如何