
使用PDFBox后的编码问题

我必须这么做
>
从pdf中提取文本,我大致使用了这个
f = IOUtility.getFileForPath(filePath);
RandomAccessFile randomAccessFile = new RandomAccessFile(f, "r");
PDFParser parser = new PDFParser(randomAccessFile);
parser.parse();
cosDoc = parser.getDocument();
pdfStripper = new PDFTextStripper();
pdDoc = new PDDocument(cosDoc);
pdfStripper.setStartPage(1);
pdfStripper.setEndPage(pdDoc.getNumberOfPages());
String parsedText = pdfStripper.getText(pdDoc);
缩放PDF
File PDFFile = IOUtility.getFileForPath(scaleConfig.getFilePath());
document = PDDocument.load(PDFFile);
for (PDPage page : document.getPages()) {
PDRectangle cropBox = page.getCropBox();
float tx = ((cropBox.getLowerLeftX() + cropBox.getUpperRightX()) * 0.03f) / 2;
float ty = ((cropBox.getLowerLeftY() + cropBox.getUpperRightY()) * 0.03f) / 2;
PDPageContentStream cs = new PDPageContentStream(document, page, PDPageContentStream.AppendMode.PREPEND, false, false);
cs.transform(Matrix.getScaleInstance(0.97f, 0.97f));
cs.transform(Matrix.getTranslateInstance(tx, ty));
cs.close();
}
document.save(scaleConfig.getTargetFilePath());
最后在pdf的每一页上写些东西。我使用此处提到的14种受支持字体之一https://pdfbox.apache.org/1.8/cookbook/workingwithfonts.html.在这种情况下,泰晤士报是新罗马的。
File PDFFile = IOUtility.getFileForPath(writeConfig.getFilePath());
document = PDDocument.load(PDFFile);
for (PDPage page : document.getPages()) {
PDFBoxHelper.fixRotation(document, page);
writeStringOnPage(document, page, writeConfig);
}
document.save(writeConfig.getTargetFilePath());
用WriteStringOnPage做
contentStream = new PDPageContentStream(document, page, PDPageContentStream.AppendMode.APPEND, false, true);
WriteCoordinates writeCoordinates = WriteCoordinateFactory.buildCoordinates(writeConfig, page.getMediaBox());
contentStream.beginText();
// lower left x and lower left y are different after rotation so use those for your calculation
contentStream.newLineAtOffset(writeCoordinates.getX(), writeCoordinates.getY());
contentStream.setFont(writeConfig.getFont(), writeConfig.getFontSize());
contentStream.setNonStrokingColor(writeConfig.getFontColor());
contentStream.showText(writeConfig.getToWrite());
contentStream.endText();
由于公司原因,我忽略了签名和捕获块。我总是关闭内容流。
大多数情况下,经过处理的PDF文件在Chrome PDF Viewer、Acrobat Reader中以及导入BMD后看起来都很好。但在某些特定情况下,我似乎有编码问题,某些部分没有正确显示。我在PDF上添加的所有文本始终正确显示。
我意识到PDF中只有粗体打印的文本显示错误,所以我使用Adobe Acrobat Reader查看所使用的字体。

Arial和Arial,粗体被嵌入并使用Idity-H编码。由于所有内容都写为粗体,我得出结论,所有用Arial,粗体编写的文本都显示错误。处理pdf后,其他一切仍然正常。我不能添加pdf,因为它有客户数据,但这里有一些示例:
- Rechnungs编号:--
如果在BMD中导入PDF而不进行PDFBox操作,则会正确显示。
我试图通过缩放和写作来缩小问题的范围,但问题两次都出现了。
我正在使用PDFBox 2.017和Java8。
当我只缩放pdf时也会发生错误,我使用PDFDebugger比较原始PDF:
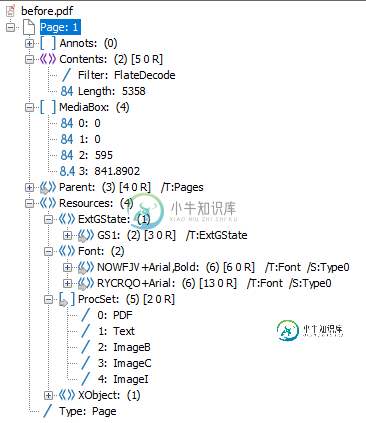
缩放后的pdf:
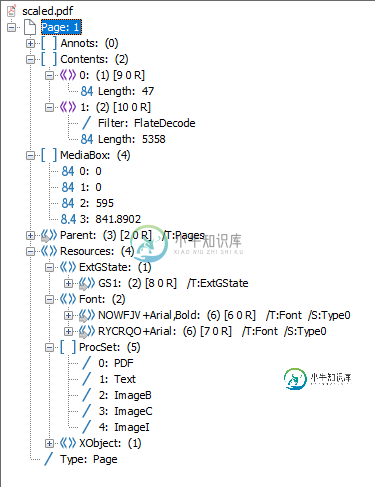
唯一不同/关闭的是内容条目。
当我打开缩放后的PDF时,单击字体部分和Arial粗体字体,我会收到很多关于unicode映射的警告。PDF在PDFDebugger中正确显示。

我既不是PDFBox方面的专家,也不是字体和编码方面的专家,因此非常感谢您的帮助!
共有1个答案

相关的区别是PDFBox序列化名称的方式不同。但是根据PDF规范的不同输出是等效的,所以您显然发现了WPViewPDF错误。
在原始PDF(raw.PDF)中,您可以找到名称NOWFJV Arial、Bold和NOWFJV Arial、Bold WinCharSetFFFF,在PDFBox操作的所有文件中,您可以找到内容流之外出现的所有名称,这些名称被NOWFJV Arial#2CBold和NOWFJV Arial#2CBold WinCharSetFFFF替换。
WPViewPDF无法正确显示使用这些更改名称的字体书写的文本。将PDF打回补丁,在这些名称中用逗号代替“#2C”后,WPViewPDF再次正确显示此类文本。
我假设WPViewPDF在内容流中找到NOWFJV Arial, Bold,并期望使用相同书写的名称在页面资源中找到匹配的字体定义,因此它无法识别名称NOWFJV Arial#2CBold。
根据PDF规范,
名称中的任何常规字符(NUMBER SIGN除外)都应写成本身或使用其2位十六进制代码,前面有NUMBER SIGN。
(ISO 32000-2,第7.3.5节“名称对象”)
因此,用“#2C”序列替换名称中的逗号是编写这些名称的一种完全有效的替代方法。
因此,不,它不是PDFBox错误,而是WPViewPDF错误。
-
我尝试使用PDFBox 2.0.0解析PDF的内容流。 这是处理它的代码的一部分: 问题是当我到达“(某个字符串)Tj”行时:这里是我的代码返回的输出示例: 正如您所看到的,“(有些字符串)Tj”行变成了“(”... 在eclipse的调试模式下,当程序到达该行时,“line”变量包含以下值: (与其他以秒结尾的字符串不同,“(”)后面没有任何内容) 如果扩展字符串值,则会得到以下字符数组: 一些
-
例如,我的一个测试使用以下Unicode字符(例如,U+2660到U+2663): 怎么修?
-
问题内容: 编码问题的简单测试程序: 这是我从debian命令箱中使用它时得到的信息,我不明白为什么在这里使用重定向会破坏该功能,因为当不使用它时我可以正确看到它。 有人可以帮助您了解我错过了什么吗?正确的方式来打印这些字符,以便在任何地方都可以使用? 使用配置有以下内容的debian Debian GNU / Linux 6.0.7(挤压): 编辑:从其他类似的问题,稍后从下面完成的指向中看到
-
我们在其中一个应用程序中使用pdfbox。一些叠加的PDF会导致输出和字体“损坏”。 下面是我用来覆盖pdf的示例代码。pdf有时具有不同的页数。我们将顶角变平,并将注释设置为只读。pdf页面旋转和bbox大小有时设置不同(尤其是扫描仪),所以我们试图纠正这一点。
-
我想把mathjax脚本添加到我的模板
-
我有这样一个csv文件 我在读书