
Kubernetes Pod报告的内存使用量超过实际进程消耗量

我有一个库伯内特斯豆荚
- 请求的1500Mb内存
我有2个容器在这个pod内运行,一个是实际应用程序(重型Java应用程序)和一个轻量级日志托运人。
pod始终报告内存使用量为1.9-2Gb。因此,部署是可伸缩的(设置了自动伸缩配置,如果内存消耗,可伸缩POD
黄线表示应用程序内存使用情况
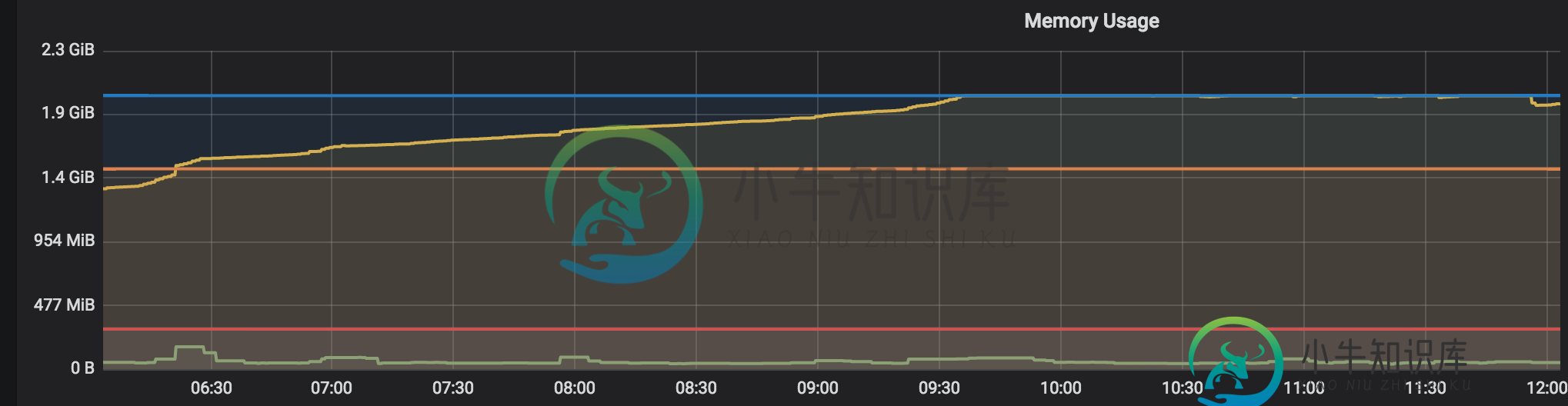
然而,在更深入的调查中,我发现了这一点。
在应用程序容器内的execing上,我运行了top命令,它报告了总共16431508 KiB或大约16Gb的可用存储器,这是机器上的可用存储器。
应用程序容器内部运行3个进程,其中根进程(应用程序)占用5.9%的内存,大致为0.92Gb。
日志传递程序只需要6Mb的内存。
现在,我不明白的是为什么我的pod总是报告如此高的使用指标。我错过了什么吗?由于意外的自动扩展,我们正在产生巨大的成本,并希望修复相同的问题。
共有2个答案

如果有人来到这里,请查看此问题,了解使用kubectl top与在容器内运行或释放的区别:检查kubernetes pod CPU和内存

在Linux中,未使用的内存被认为是浪费的内存,这就是为什么所有“空闲”RAM(即应用程序或内核本身未使用的内存)都被积极用于缓存IO操作、文件系统元数据等,但如果需要,会提供给您的应用程序。
您可以在此处获取有关容器内存消耗的详细信息:
/sys/fs/cgroup/memory/docker/{id}/memory.stat
如果要根据内存使用量来扩展集群,最好只计算应用程序大小,而不是容器内存使用量。
-
我有一个很小的java控制台应用程序,我想在内存使用方面进行优化。它是在Xmx设置为仅64MB的情况下运行的。根据不同的监视工具(htop、ps、pmap、Dynatrace)显示进程的总体内存使用量超过250MB。我主要在Ubuntu18上运行它(也在其他操作系统上测试)。 我使用了-xx:nativeMemoryTracking,java param和jcmd的本地内存跟踪,以找出为什么在堆之
-
我有一个JVM,它报告提交的堆内存约为8GB(其他部分应该在此之上)。但我的操作系统显示内存使用量约为5GB。我理解由于非堆、metaspace等原因,内存使用量可能会超过提交的内存,但是怎么可能使用量比JVM报告的要少呢? 本机内存跟踪器(NMT)的输出显示保留内存为~11 GB OS-Debian 9 爪哇-
-
我正在docker中运行一个java进程。我已经设置了xms(388m)和xmx(388m)。在应用程序启动后的某个时候,容器的内存消耗超过并达到了大部分~主机内存大小,容器被杀死。 < li >当我使用jprofiler连接到java进程时,我看到堆小于Xmx < li >但是,容器内顶部的命令显示< code>docker stats显示的内容 < li >当我在主机上运行相同的java进程时
-
问题内容: 我需要监视应用程序产生的线程消耗的内存量。如果贪婪的线程消耗太多内存,则想法是采取纠正措施。我已提到Java线程占用多少内存?。关于该链接的建议之一是在我尝试以下工作时使用。 我在四个线程上运行了很长时间。尽管作业不会连续地累积内存,但是所返回的值会不断增加,甚至不会下降。这意味着不会返回线程使用的堆上的实际内存量。它返回自线程启动以来在堆上为线程分配的内存总量。我的平台详细信息如下:
-
我需要监控应用程序生成的线程所消耗的内存量。如果贪婪的线程占用了太多内存,那么我们可以采取纠正措施。我提到了我的java线程需要多少内存?。关于该链接的建议之一是在ThreadMXBean中使用getThreadAllocatedBytes 我用以下作业试验了getThreadAllocatedBytes。 我在四个线程上运行了相当长的时间。虽然作业不会连续累积内存,但getThreadAlloc
-
如果我运行的Kafka集群的分区比我的单个消费者组拥有的消费者还多。对消息的排序或跨分区的消息的按时传递是否有任何保证? 简单示例: 2个分区,1个使用者 生产者通过一个密钥控制分区分配。 消息1进入并转到分区a 消息2进入并转到分区B 消息3进入并转到分区a 我知道消息1将在消息3之前被使用,因为它们在同一个分区中。但是第二条信息呢?是在消息3之前消费还是在消息3之后消费?还是会有变化?它可能在