
用于计算不同事件之间的平均持续时间的SQL查询

我需要有关构建SQL查询的帮助:
这是我用来存储测试运行统计信息的postgres表。
CREATE TABLE logs
(
id bigint NOT NULL,
test_id int,
state text,
start_date timestamp with time zone,
end_date timestamp with time zone,
CONSTRAINT logs_pkey PRIMARY KEY (id)
)
此表包含测试开始时间、结束时间和状态。我需要计算由于测试失败而使用的时间间隔。即测试失败和下一个立即测试开始之间的时间间隔。
即对于每个测试失败的记录,获取end_date并获取同一测试的下一个即时记录的start_date。计算时间差。将所有此类失败记录的持续时间相加,并按失败次数计算。以获得平均值。
例子:
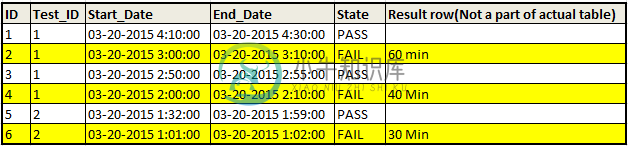
假设我有下面的数据表,只有5列,最后一列失败状态下的持续时间应该是我查询的一部分。
i、 e我总共有3条失败记录,两条用于测试1,一条用于测试2。因此,总时间=130分钟/3=大约43.3分钟将以秒为单位。
有人能给我这个SQL查询吗?
共有1个答案

如前所述,这可以使用窗口功能轻松完成:
select id,
test_id,
start_date,
end_date,
state,
case
when state = 'FAIL' then lag(start_date) over (partition by test_id order by start_date desc) - end_date
else null
end as time_diff
from logs
order by test_id, start_date desc;
SQLFiddle:http://sqlfiddle.com/#!15/0d40f/2
-
问题内容: 我有一个表,其中有两列开始时间和结束时间。我能够计算每一行的持续时间,但我也想获得总持续时间。这该怎么做。 谢谢 问题答案: 您的列的数据类型为TIMESTAMP,如下所示: 从一个时间戳减去另一个时间戳会导致一个INTERVAL数据类型: 并且不能对INTERVAL数据类型求和。这是一个令人讨厌的限制: 为了规避此限制,您可以使用秒数进行转换和计算,如下所示: 然后它们是可以累加的普
-
问题内容: 我有一条流经多个系统的消息,每个系统都会记录消息的进入和退出以及时间戳和uuid messageId。我通过以下方式提取所有日志: 结果,我现在有以下事件: 我想生成一个报告(最好是堆积的条或列),用于每个系统的时间: 做这个的最好方式是什么?Logstash过滤器?kibana计算字段? 问题答案: 您只能使用Logstash 过滤器来实现此目的,但是,您必须实质性地重新实现该过滤器
-
问题内容: 我有一组呼叫详细记录,从这些记录中,我可以确定每个系统每小时的平均并发活动呼叫(精确到一分钟)。如果查询从晚上7点到晚上8点,则应该看到该小时(对于每个系统)在该小时内的平均并发呼叫数(每分钟的并发呼叫数平均值)。 因此,我需要一种方法来检查7:00-7:01、7:01-7:02等的活动呼叫计数,然后对这些数字求平均值。如果呼叫的时间和持续时间在当前要检查的分钟内,则认为该呼叫处于活动
-
我想用基于历史事件的流计算Flink中基于窗口的平均值(或我定义的任何其他函数),因此流必须是事件时间(而不是基于处理时间): 我已经了解了如何在摄入时添加时间戳: 但是当我进行计算(应用函数)时,当我只是以与没有EventTime时相同的方式进行计算时,它就不起作用了。我读过一些关于我必须设置的水印的东西: 有没有人举一个简单的Scala例子? 尊敬的安德烈亚斯
-
我想计算Java中两小时(HH:mm:ss)之间的时间差(持续时间)。在这里,我读了几个关于这个主题的主题,但我的问题有点不同。 我也不能使用。 示例: ode: 结果:
-
我有一些能量计,将继续产生计数器值,这是一个累积指标。即不断增加,直到计数器复位。 有一个实时ETL作业,它在事件时间的两个连续值之间进行减法。 例如。 此外,有时事件可能没有按顺序接收。 如何使用Apache Flink流式API实现?最好使用Java中的示例。