
Keras最简单的NN模型:索引training.py误差

我读过这个例子https://github.com/fchollet/keras/blob/master/examples/mnist_mlp.py并决定在我的基础上使用这个想法,因为这是Keras最简单的神经网络。
这是我的基地https://drive.google.com/file/d/0B-B3QUQOzGZ7WVhzQmRsOTB0eFE/view(你可以下载我的csv文件,它只有83Kb)
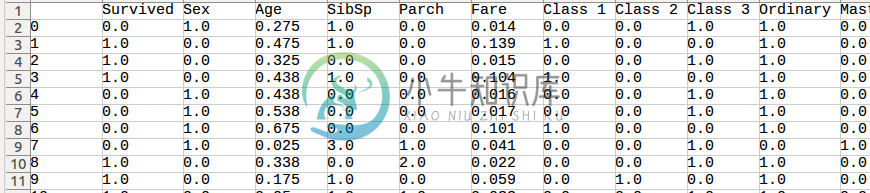
基础形状=(891,23)
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop, Adam
import numpy as np
import pandas as pd
from sklearn.cross_validation import train_test_split
from keras.utils.vis_utils import model_to_dot
from IPython.display import SVG
from keras.utils import plot_model
base = pd.read_csv("mt.csv")
import pandas as pd
for col in base:
if col != "Fare" and col != "Age":
base[col]=base[col].astype(float)
X_train = base
y_train = base["Survived"]
del X_train["Survived"]
print("X_train=",X_train.shape)
print("y_train=", y_train.shape)
输出:X\U列=(891,22)y\U列=(891,)
from sklearn.cross_validation import train_test_split
X_train, X_test , y_train, y_test = train_test_split(X_train, y_train, test_size=0.3, random_state=42)
batch_size = 4
num_classes = 2
epochs = 2
print(X_train.shape[1], 'train samples')
print(X_test.shape[1], 'test samples')
输出:22个序列样本22个测试样本
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model = Sequential()
model.add(Dense(40, activation='relu', input_shape=(21,)))
model.add(Dropout(0.2))
#model.add(Dense(20, activation='relu'))
#odel.add(Dropout(0.2))
model.add(Dense(2, activation='sigmoid'))
model.summary()
出:
致密\u 1(致密)(无,40)880
dropout\u 1(dropout)(无,40)0
dense_2(密集)(无,2)82
model.compile(loss='binary_crossentropy',
optimizer=Adam(),
metrics=['accuracy'])
plot_model(model, to_file='model.png')
SVG(model_to_dot(model).create(prog='dot', format='svg'))
print("X_train.shape=", X_train.shape)
print("X_test=",X_test.shape)
history = model.fit(X_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(X_test, y_test))
Traceback(最近一次调用):文件new.py,第67行,validation_data=(X_test,y_test))
文件"minicon da3/lib/python3.6/site-pack/keras/models.py",第845行,适合initial_epoch=initial_epoch)
文件"miniconda3/lib/python3.6/site-包/keras/引擎/training.py",第1405行,适合batch_size=batch_size)
文件"minicon da3/lib/python3.6/site-pack/keras/Engine/training.py",第1295行,_standardize_user_dataexception_prefix='模型输入')
文件“miniconda3/lib/python3.6/site packages/keras/engine/training.py”,第133行,位于\u standarding\u input\u data str(array.shape)中
ValueError:检查模型输入时出错:期望dense_1_input具有形状(无,21),但得到具有形状(623,22)的数组[在5.1秒内完成,退出代码为1]
我如何解决这个错误?我尝试将输入形状更改为(20,)或(22,)等,但没有成功。
例如,如果input\u shape=(22,)我有一个错误:文件“miniconda3/lib/python3.6/site packages/pandas/core/index.py”,行1873,在maybe\u convert\u index raiser中(“索引超出界限”)
共有1个答案

input\u shape应与数据中的特征数相同,并且在您的情况下应为input\u shape=(22,)。
IndexError是由于熊猫数据帧中的一些不同索引,因此使用as_matrix()将您的数据帧转换为numpy矩阵:
history = model.fit(X_train.as_matrix(), y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(X_test.as_matrix(), y_test))
-
本文向大家介绍简单介绍下MYSQL的索引类型,包括了简单介绍下MYSQL的索引类型的使用技巧和注意事项,需要的朋友参考一下 一、介绍一下索引的类型 Mysql常见索引有:主键索引、唯一索引、普通索引、全文索引、组合索引 PRIMARY KEY(主键索引) ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` ) UNIQUE(唯一索引) ALTER
-
我正在建立一个简单的神经网络。数据是一个231长的向量,它是一个热编码的向量。每个231个长向量被分配一个8个长的热编码标签。 到目前为止,我的代码是: 问题是输出层是8个单位,但是我的标签不是单个单位,它们是一个热编码的8个长矢量。如何将此表示为输出? 错误消息是: 无法用非浮点dtype构建密集层 完全回溯:
-
问题内容: 我部署了一个keras模型,并通过flask API将测试数据发送到该模型。我有两个文件: 首先:My Flask应用程序: 第二:文件Im用于将json数据发送到api端点: 我从Flask收到有关Tensorflow的回复: ValueError:Tensor Tensor(“ dense_6 / BiasAdd:0”,shape =(?, 1),dtype = float32)不
-
Keras有两种类型的模型,序贯模型(Sequential)和函数式模型(Model),函数式模型应用更为广泛,序贯模型是函数式模型的一种特殊情况。 两类模型有一些方法是相同的: model.summary():打印出模型概况,它实际调用的是keras.utils.print_summary model.get_config():返回包含模型配置信息的Python字典。模型也可以从它的config
-
Keras有两种类型的模型,顺序模型(Sequential)和泛型模型(Model) 两类模型有一些方法是相同的: model.summary():打印出模型概况 model.get_config():返回包含模型配置信息的Python字典。模型也可以从它的config信息中重构回去 config = model.get_config() model = Model.from_config(con
-
我正在尝试使用 VGG16 编码器构建 U-Net 模型。这是模型代码。 我收到以下错误。 ValueError:图断开连接:无法获取张量张量的值("input_1: 0",形状=(无,512,512,3),dtype=float32)在层"input_1"。 注意:是VGG16型号的输入层