
无法正确转换tf。coral TPU量化格式的keras模型

我正在尝试转换一个tf。keras模型基于mobilenetv2,使用最新的tf加密进行转置卷积。这是转换代码
#saved_model_dir='/content/ksaved' # tried from saved model also
#converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter = tf.lite.TFLiteConverter.from_keras_model(reshape_model)
converter.experimental_new_converter=True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
converter.representative_dataset = representative_dataset_gen
tflite_quant_modell = converter.convert()
open("/content/model_quant.tflite", "wb").write(tflite_quant_modell)
转换是成功的(在google colab);但它在末端对操作员进行了量化和去量化(如在netron上看到的)。似乎支持所有运营商。代表性的数据集图像在生成器中是Float32,默认情况下,模型具有4通道Float32输入。看起来我们需要一个UINT8输入和输出珊瑚TPU内部模型。如何才能恰当地进行这种转换呢?
参考:-
>
权重和激活的全整数量化
如何量化优化tflite模型的输入和输出
珊瑚边缘TPU编译器无法转换tflite模型:模型未量化
我试过用tf。同胞。v1。清淡的。TFLiteConverter。从_keras_model_文件而不是v2版本。我在尝试量化最新tf 1.15(使用代表性数据集)中的模型时遇到错误:“op:TRANSPOSE_CONV尚不支持量化”和“内部编译器错误。中止!”使用tf2从coral tpu编译器。0量化tflite
Tflite模型@https://github.com/tensorflow/tensorflow/issues/31368
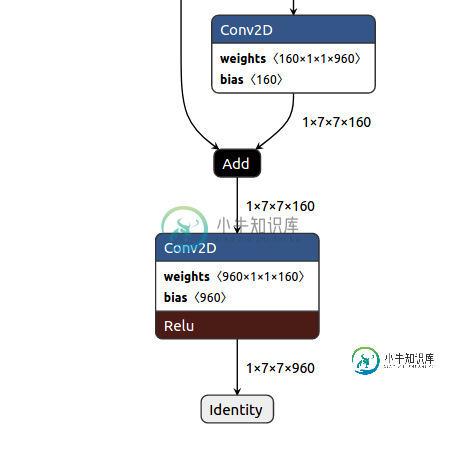
直到最后一个组成块(1x7x7x160)编译器错误(中止)没有给出任何有关潜在原因的信息,并且根据coral文档,所有类型的卷积层似乎都受支持。
珊瑚文件:https://coral.ai/docs/edgetpu/models-intro/#quantization
共有2个答案

我始终确保不使用实验转换器:
converter.experimental_new_converter = False

下面是量化keras模型的虚拟模型示例。注意,我使用的是严格的tf1。15作为示例,因为tf2。0已弃用:
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
使用来自keras模型的api。我认为最让人困惑的是,你仍然可以打电话给它,但什么也没发生。这意味着模型仍将接受浮点输入。我注意到您正在使用tf2。0,因为来自_keras_模型的是一个tf2。0 api。Coral仍然建议使用tf1。15用于现在转换模型。我建议降级tensorflow,或者干脆使用它(在保持tf2.0的同时,它可能会工作,也可能不会工作):
tf.compat.v1.lite.TFLiteConverter.from_keras_model_file
这里有更多。
-
我已经使用Keras来微调MobileNet v1。现在我有,我需要将其转换为TensorFlow Lite,以便在Android应用程序中使用。 我使用TFLite转换脚本。我可以在没有量化的情况下进行转换,但我需要更高的性能,所以我需要进行量化。 如果我运行此脚本: 它失败了: F tensorflow/contrib/lite/toco/tooling\u util。cc:1634]Arra
-
数字的Number类型和日期Date类型的格式化是默认安装了的,包括@NumberFormat注解和@DateTimeFormat注解。如果classpath路径下存在Joda Time依赖,那么完美支持Joda Time的时间格式化库也会被安装好。如果要注册定制的格式化器或转换器,请覆写addFormatters方法: @Configuration @EnableWebMvc public cl
-
问题内容: 我的号码是654987。它是数据库中的ID。我想将其转换为字符串。常规的Double.ToString(value)使它成为科学形式6.54987E5。我不想要的东西。 我发现的其他格式化功能会检查当前的语言环境,并添加适当的千位分隔符等。由于它是一个ID,我完全不能接受任何格式。 怎么做? [编辑]要澄清:我正在一个特殊的数据库上工作,该数据库将所有数字列都视为双精度。 Double
-
问题内容: 我正在尝试使用Android中的WebView上传文件。 这是使用的代码: 的 问题 是,当外部库,我 必须 使用()触发此方法的执行,如在fileChooserParams参数传递的MIME类型:。在允许的mime类型列表中,我看不到其中的大多数。 结果,我在LogCat中发现此错误: 如果我简单地添加,一切都将按预期工作! 现在的 问题 是:在我要提交给cordova-androi
-
我试图上传一个文件使用WebView在Android。 现在的问题是:在我要提交给Cordova-Android贡献者的合并请求中,我如何安全地将fileChooserParams转换为正确的格式?