
使用Microsoft认知语音Websocket进行连续语音识别-Xamarin

我正在尝试使用适用于Xamarin Android的Microsoft认知语音从麦克风构建连续语音识别。我认为没有Xamarin的库,所以我稍微修改了“Xamarin。认知。BingSpeech”库(endpoint等)以使其正常工作。我有一些问题
我想通过以下教程连接到microsoft web套接字https://docs.microsoft.com/en-us/azure/cognitive-services/speech/api-reference-rest/websocketprotocol.
我尝试使用基本的HttpClient发送HTTPREQUEST,得到了101交换机协议的结果(我想我成功了吗?)。
更新:我的HTTP请求是:
System.Net.ServicePointManager.SecurityProtocol = SecurityProtocolType.Tls12 | SecurityProtocolType.Ssl3;
var request = new HttpWebRequest(uriBuilder.Uri);
request.Headers.Add("Authorization", new System.Net.Http.Headers.AuthenticationHeaderValue(Bearer, AuthClient.Token).ToString());
request.Accept=MimeTypes.Json;
request.Host = SpeechEndpoint.Host;
request.Connection = "Upgrade";
request.Headers.Add("Upgrade", "Websocket");
request.KeepAlive = true;
request.Method = "GET";
request.CookieContainer = new CookieContainer();
request.AllowAutoRedirect = true;
request.Date = DateTime.Now;
request.CachePolicy = new System.Net.Cache.RequestCachePolicy(System.Net.Cache.RequestCacheLevel.CacheIfAvailable);
request.Headers.Add("Sec-WebSocket-Key", "dGhlIHNhbXBsZSBub25jZQ==");
request.Headers.Add("Sec-WebSocket-Version", "13");
request.Headers.Add("Sec-WebSocket-Protocol", "chat, superchat");
request.Headers.Add("X-ConnectionId",xConnectionId = Guid.NewGuid().ToString().ToUpper());
在制作HTTPRequest后,我正在尝试连接到websocket,但我总是得到“无法连接到远程服务器”,没有任何错误代码或任何东西。(wss://xxxxxxxx)。
Uri wsuri = new Uri(AppConfig.BINGWSSURI);
await _socketclient.ConnectAsync(wsuri, CancellationToken.None);
Log.Info("WSOCKETFINISH", _socketclient.State.ToString());
我想实现的第二件事是使用二进制消息将音频从麦克风传输到websocket,所以我必须
- 从麦克风录制(我正在使用插件录音机)
- 把它切成小块
- 使用websocket异步流式传输小片段
我想要实现的是:使用Microsoft认知语音和听写模式的麦克风进行语音到文本转换,因此我需要部分结果,而不是等待录制完成。
共有1个答案

我想你想把演讲转换成文本<自从Xamarin以来。认知的BingSpeech需要您录制语音并将其作为文件或流发送到服务器。我想你可以尝试使用Android语音。它还可以将文本转换为语音。这里有一个例子。
如果你想使用Xamarin。认知的BingSpeech,您可以使用音频录制器插件录制语音,并使用BingSpeechAPClient发送到服务器。例如:
BingSpeechApiClient bingSpeechClient = new BingSpeechApiClient ("My Bing Speech API Subscription Key");
var audioFile = "/a/path/to/my/audio/file/in/WAV/format.wav";
var simpleResult = await bingSpeechClient.SpeechToTextSimple (audioFile);
Or
var simpleResult = await bingSpeechClient.SpeechToTextSimple (stream, <sample rate>, <audio record Task>);
下面是Xamarin的例子。认知的宾语。
更新时间:
我总是得到“无法连接到远程服务器”,没有任何错误代码或任何东西。
您在标题中缺少一些有价值的东西。
>
您需要生成一个UUID并将其添加到头中。例如:<代码>客户端。选项。SetRequestHeader(“X-ConnectionId”,System.Guid.NewGuid()。ToString())
授权
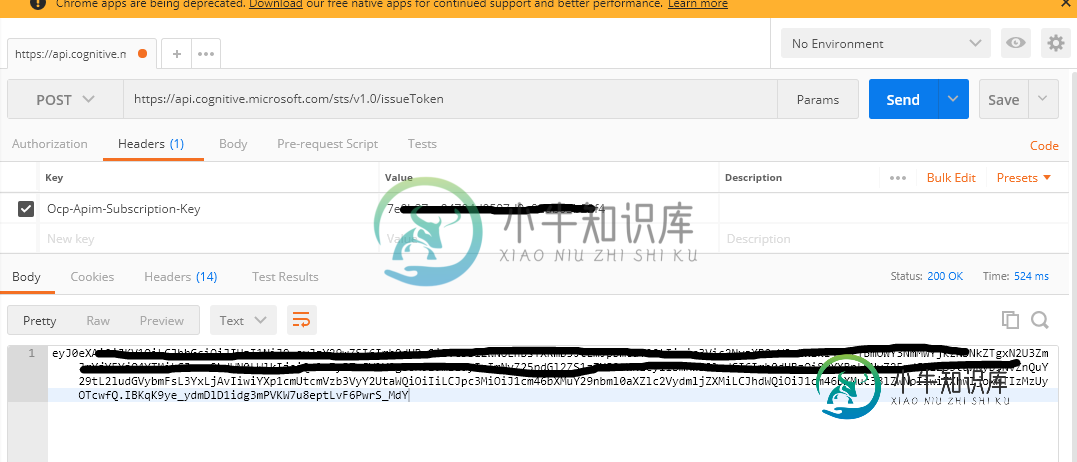
您需要将订阅密钥发布到https://api.cognitive.microsoft.com/sts/v1.0/issueToken.你可以用邮递员来做这件事。然后在标题中添加返回值。
客户选项。SetRequestHeader(“授权”,“eyJ0eXAiOiJKV1Q…uW72PAOBRcUvqY”);
所以我需要部分结果而不是等录音完成
您可以使用GetAudioFileStream()方法。例如:
var audioRecordTask = await recorder.StartRecording();
using (var stream = recorder.GetAudioFileStream ())
{
//this will get the recording audio data as it continues to record
}
更新2:websoket部件代码:
var client = new ClientWebSocket();
client.Options.UseDefaultCredentials = true;
client.Options.SetRequestHeader("X-ConnectionId", System.Guid.NewGuid().ToString());
client.Options.SetRequestHeader("Authorization", "eyJ0eXAiOiJKV1QiL....16pbFPOWT3VHXot8");
var a = client.ConnectAsync(new Uri("wss://speech.platform.bing.com/speech/recognition/Dictation/cognitiveservices/v1"), CancellationToken.None);
a.Wait();
注意:使您的授权值保持最新。
-
我在Bing语音API的文档中看到,可以将录音麦克风输入流式传输到REST服务(https://docs.microsoft.com/en-us/azure/cognitive-services/speech/home): 实时连续识别。语音识别API使用户能够实时将音频转录成文本,并支持接收目前已识别单词的中间结果。 然而,我找不到一个示例来说明如何使用Xamarin表单以跨平台的方式实现这一点
-
如何使用REST API(带javascript SDK)Bing语音API实现连续语音识别? 使用do Javascript SDK示例:https://github.com/Microsoft/Cognitive-Speech-STT-JavaScript只能用麦克风转录短句
-
我知道“x-webkit-speech”能够进行某种语音识别,实际上识别效果很好。 我发现“x-webkit-语音”有利于开发Q 然而,我正在寻找的是一种在浏览器中执行连续语音识别的方法。例如,如果我在网上听到一个讲座,我想实时转录教授正在谈论的内容。 是否可以使用“x-webkit-speech”?我的感觉是,“x-webkit-speech”在检测到一段很短的静默期时会自动停止,这很烦人。我知
-
[信息]:#安装纯Python模块 [信息]:需求(SpeechRecognition,pyaudio)没有菜谱,试图用pip安装它们 [信息]:如果失败,这可能意味着模块已经编译了组件,需要一个配方。 工作:pid 3095的线程后台线程异常:n/python2.7-u-c“导入设置...(和509更多) 回溯(最近调用的最后一次): 文件“/usr/lib/python2.7/threadin
-
我想在phonegap中创建应用程序,在Android和IOS中使用连续语音识别。我的应用程序应该等待用户的声音,当他/她说“下一步”时,应用程序应该更新屏幕并执行一些操作。 我发现这个插件:https://github.com/macdonst/SpeechRecognitionPlugin而且它工作得非常快。但在语音识别启动几秒钟后,语音识别器停止工作,但并没有语音。是否有任何方法或标志,如i
-
我有一个实现识别侦听器(RecognitionListener)的活动。要使其连续,每次我再次启动侦听器时: 但是,它需要一些时间(大约半秒钟)才能开始,所以有半秒钟的间隙,没有人在听。因此,我怀念那段时差中所说的话。 另一方面,当我使用谷歌的语音输入时,代替键盘来口述消息——这个时间间隔不存在。意思是——有一个解决方案。 这是什么? 谢谢