
Apache Spark:核数与执行程序数的关系

我试图理解在Yarn上运行Spark作业时,核数和执行器数的关系。
测试环境如下:
- 数据节点数:3
- 数据节点计算机规范:
- CPU:Core i7-4790(内核数:4,线程数:8)
- RAM:32GB(8GB x 4)
- HDD:8TB(2TB x 4)
输入数据
- 类型:单文本文件
- 大小:165GB
- 行数:454,568,833
输出
-
null
>
50分钟15秒
55分48秒
31分23秒
有关信息,performance monitor屏幕截图如下:
- (1)的神经节数据节点摘要-作业于04:37启动。
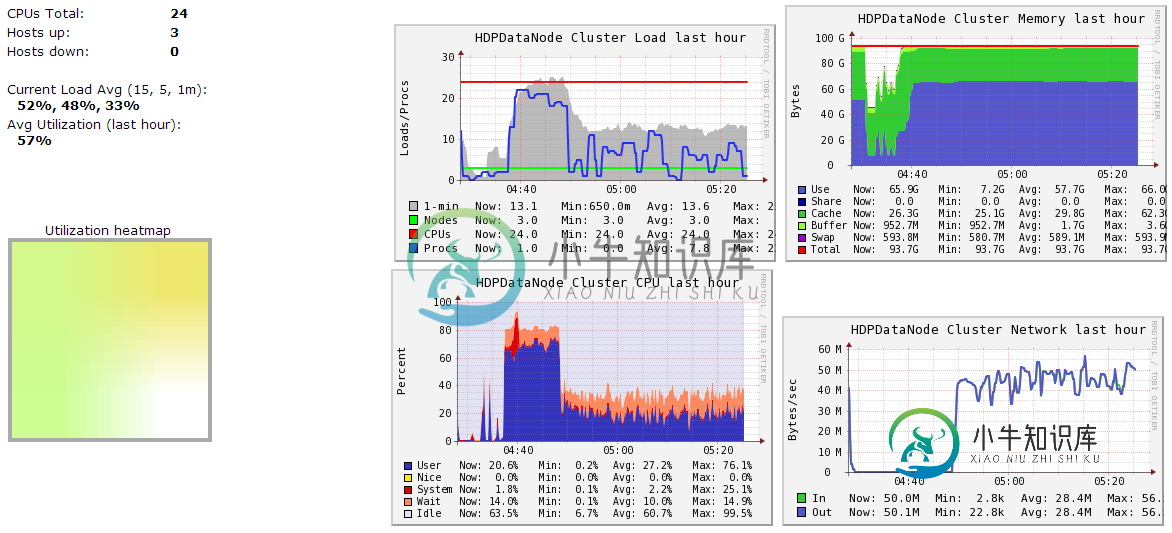
- (3)的神经节数据节点摘要-作业于19:47开始。请忽略该时间之前的图形。
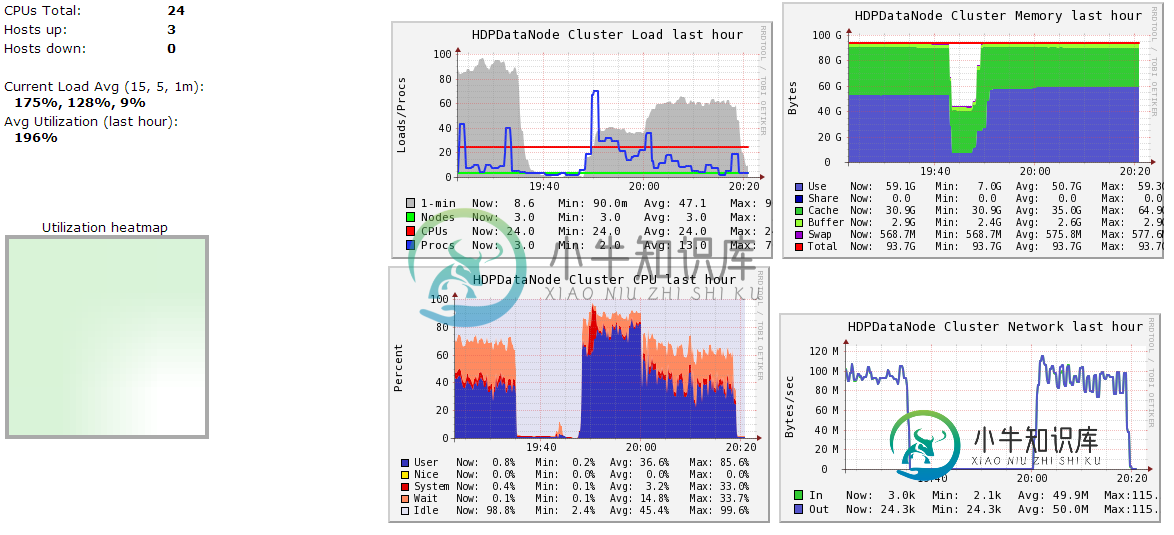
-
null
共有1个答案

为了使所有这些更具体,这里有一个配置Spark应用程序以尽可能多地使用集群的工作示例:假设一个集群有六个运行NodeManagers的节点,每个节点配备16个核心和64GB内存。NodeManager容量,yarn.NodeManager.resource.memory-MB和yarn.NodeManager.resource.cpu-vcores,可能应该分别设置为63*1024=64512(兆字节)和15。我们避免将100%的资源分配给纱容器,因为节点需要一些资源来运行OS和Hadoop守护进程。在这种情况下,我们为这些系统进程留下一个千兆字节和一个核心。Cloudera Manager通过计算这些信息并自动配置这些纱线属性来提供帮助。
可能的第一个冲动是使用--数量执行器6--执行器核心15--执行器存储器63G。然而,这是错误的做法,因为:
63GB+执行器内存开销不适合Nodemanagers的63GB容量。应用程序主机将占用其中一个节点上的一个核,这意味着该节点上没有空间容纳15个核的执行器。每个执行器有15个核心可能会导致不良的HDFS I/O吞吐量。
更好的选择是使用-num-executors17-executor-cores5-executor-memory19g。为什么?
这个配置会在所有节点上产生三个执行器,但带有AM的节点除外,该节点将有两个执行器。--执行器--内存导出为(每个节点63/3个执行器)=21。21*0.07=1.47。21~1.47~19。
Cloudera博客中的一篇文章给出了解释,文章名为How-to:Tune Your Apache Spark Jobs(Part 2)。
-
我提出了一个关于Spark的非常愚蠢的问题,因为我想澄清我的困惑。我对Spark非常陌生,仍在努力理解它在内部是如何工作的。 比方说,如果我有一个输入文件列表(假设1000),我想在某个地方处理或写入,并且我想使用coalesce将我的分区数减少到100。 现在我用12个执行器运行这个作业,每个执行器有5个内核,这意味着它运行时有60个任务。这是否意味着,每个任务将在一个单独的分区上独立工作? 回
-
关于Spark中的性能调优,我有两个问题: > 我理解在spark作业中控制并行性的一个关键因素是正在处理的RDD中存在的分区的数量,然后控制处理这些分区的执行器和内核。我能假定这是真的吗: 执行程序的 #个*#个执行程序核心的<=#个分区。也就是说,一个分区总是在一个执行器的一个核中处理。执行器核数超过分区数是没有意义的 我知道每个执行器拥有高数量的内核可能会对HDFS写操作产生影响,但是我的第
-
请先用以下条款验证我: 执行器:它的将运行在上。每个节点可以有多个执行器。 核心:它是内的一个线程,运行在上。每个执行器可以有多个内核或线程。 > 当我们提交火花作业时,它意味着什么?我们是否将工作移交给Yarn或resource manager,它将分配资源给集群中的并执行它?它是正确的理解…? 在spark集群中用于提交作业的命令中,有一个设置执行者数量的选项。 那么这些执行器+核的数量将会是
-
问题内容: 许多次我听说最好将线程池中的线程数保持在该系统中的内核数以下。具有比核心数多两倍或更多的线程不仅浪费,而且还可能导致性能下降。 那些是真的吗?如果不是,那么揭露这些主张的基本原则是什么(特别是与Java有关)? 问题答案: 许多次我听说最好将线程池中的线程数保持在该系统中的内核数以下。具有比核心数多两倍或更多的线程不仅浪费,而且还可能导致性能下降。 这些主张 作为一般性陈述 是不正确的
-
Apache Spark:核心数与执行器数 由于每个案例都不一样,我又问了一个类似的问题。 我正在运行一个cpu密集型的应用程序,具有相同数量的核心和不同的执行器。以下是观察结果。 更新 案例3:执行器-12个,每个执行器的核心数-1个,执行器内存-3个,数据处理量-10 GB,分区-36个,作业持续时间:81分钟
-
问题内容: 在PyCharm中,运行脚本后,它会自动将其杀死: C:\ Users \ Sean.virtualenvs \ Stanley \ Scripts \ python.exe C:/Users/Sean/PycharmProjects/Stanley/Stanley.py 流程结束,退出代码为0 脚本启动后如何与之交互?由于缺少更好的措辞方式,我该如何获取 脚本运行一次后提示? PyC