
Seaborn混淆矩阵(热图)2种配色方案(正确的对角线与错误的Rest)

在混淆矩阵中,对角线表示预测标签与正确标签匹配的情况。所以对角线是好的,而所有其他单元格都是坏的。为了澄清非专家的CM中什么是好的,什么是坏的,我想给对角线一个不同于其他颜色的颜色。我想用Python实现这一点
基本上,我试图实现这个问题在R中的作用(ggplot2热图2不同的配色方案-混淆矩阵:与分类不同的配色方案中的匹配)
import numpy as np
import seaborn as sns
cf_matrix = np.array([[50, 2, 38],
[7, 43, 32],
[9, 4, 76]])
sns.heatmap(cf_matrix, annot=True, cmap='Blues') # cmap='OrRd'
这将导致此图像:
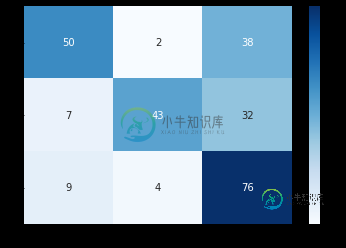
我想用例如cmap='OrRd'为非对角单元格着色。所以我想象会有2个色条,1个蓝色代表对角线,1个代表其他单元格。优选地,两个色条的值匹配(例如,0-70,而不是0-70和0-40)。我将如何处理这个问题?
以下不是用代码制作的,而是用照片编辑软件制作的:

共有2个答案

您可以先用彩色地图“OrRd”绘制热图,然后用彩色地图“Blues”覆盖热图,上面和下面的三角形值替换为NaN,请参见以下示例:
def diagonal_heatmap(m):
vmin = np.min(m)
vmax = np.max(m)
sns.heatmap(cf_matrix, annot=True, cmap='OrRd', vmin=vmin, vmax=vmax)
diag_nan = np.full_like(m, np.nan, dtype=float)
np.fill_diagonal(diag_nan, np.diag(m))
sns.heatmap(diag_nan, annot=True, cmap='Blues', vmin=vmin, vmax=vmax, cbar_kws={'ticks':[]})
cf_matrix = np.array([[50, 2, 38],
[7, 43, 32],
[9, 4, 76]])
diagonal_heatmap(cf_matrix)

您可以在调用heatmap()中使用mask=来选择要显示的单元格。使用对角线和非对角线单元格的两个不同遮罩,可以获得所需的输出:
import numpy as np
import seaborn as sns
cf_matrix = np.array([[50, 2, 38],
[7, 43, 32],
[9, 4, 76]])
vmin = np.min(cf_matrix)
vmax = np.max(cf_matrix)
off_diag_mask = np.eye(*cf_matrix.shape, dtype=bool)
fig = plt.figure()
sns.heatmap(cf_matrix, annot=True, mask=~off_diag_mask, cmap='Blues', vmin=vmin, vmax=vmax)
sns.heatmap(cf_matrix, annot=True, mask=off_diag_mask, cmap='OrRd', vmin=vmin, vmax=vmax, cbar_kws=dict(ticks=[]))
如果你想变得花哨,你可以创建轴使用GridSpec有一个更好的布局:
作为np导入Numpy作为sns导入海运
fig = plt.figure()
gs0 = matplotlib.gridspec.GridSpec(1,2, width_ratios=[20,2], hspace=0.05)
gs00 = matplotlib.gridspec.GridSpecFromSubplotSpec(1,2, subplot_spec=gs0[1], hspace=0)
ax = fig.add_subplot(gs0[0])
cax1 = fig.add_subplot(gs00[0])
cax2 = fig.add_subplot(gs00[1])
sns.heatmap(cf_matrix, annot=True, mask=~off_diag_mask, cmap='Blues', vmin=vmin, vmax=vmax, ax=ax, cbar_ax=cax2)
sns.heatmap(cf_matrix, annot=True, mask=off_diag_mask, cmap='OrRd', vmin=vmin, vmax=vmax, ax=ax, cbar_ax=cax1, cbar_kws=dict(ticks=[]))
-
请指导我的混淆矩阵的热图显示。我尝试了不同的图大小,但没有得到正确的显示。我的代码如下和屏幕截图
-
所有规则中不正确分类(见树)的总和是2097(来自895 700 428 74)。但是混淆矩阵是2121(来自1999 122)。有人能解释一下差异吗?为什么数字不同?
-
无法正确打印混淆矩阵和打印热图。在示例2e 2、e 4等中,某些块或列中的值正在打印。请在这方面帮助我 导入numpy作为np导入matplotlib.pyplot作为plt导入seaborn作为sns从keras导入pandas作为pd。模型从keras导入顺序。图层从keras导入卷积2D。图层从keras导入MaxPoolig2D。图层从keras导入展平。图层从sklearn导入稠密。度量
-
这得到了我想要的,但可能没有很好地扩展? 产量
-
如何分析Weka中的混淆矩阵,以获得准确度?我们知道,由于数据集不平衡,精度不准确。混淆矩阵如何“确认”准确性? 示例:a)准确率96.1728% b) 准确率:96.8% 等...
-
我正在对实际数据和来自分类器的预测数据进行多标签分类。实际数据包括三类(c1、c2和c3),同样,预测数据也包括三类(c1、c2和c3)。数据如下 在多标签分类中,文档可能属于多个类别。在上述数据中,1表示文档属于特定类,0表示文档不属于特定类。 第一行Actual\u数据表示文档属于c1类和c2类,不属于c3类。类似地,第一行predicted\u数据表示文档属于类别c1、c2和c3。 最初我使