
如何比较Datatricks中的2个Spark数据帧

我有以下spark数据帧。一个来自文本文件,另一个来自Databricks中的Spark表:
尽管数据完全相同,但以下代码报告了差异。我希望df3为空:
table_df = spark.sql("select * from db.table1")
file_df = spark.read.format("csv").load("my_file.txt", header = False, delimiter = '|')
file_df = file_df.toPandas()
table_df = table_df.toPandas()
df3=table_df.eq(file_df)
print(df3.shape[0])
- 我需要在比较之前订购数据吗?-如果是,我该怎么做
- 我看不出上面的连接是在哪里完成的。它将如何匹配行?[ID]和[帐户]是主键
- 以上是比较2个数据帧的最佳方法吗
这是数据-其中[ID]和[帐户]是主键
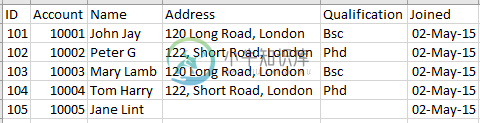
共有1个答案

我通常比较两个数据帧的方法是使用内部连接来查看计数是否匹配,或者使用相减来查看两个数据帧之间是否有任何不同
df1 = create_df(
data=[
('Avery Bradley', 25.0, 7730337.0),
('Jae Crowder', 25.0, 6796117.0),
],
schema = ['name', 'age', 'salary']
)
+-------------+----+---------+
| name| age| salary|
+-------------+----+---------+
|Avery Bradley|25.0|7730337.0| <<< 25
| Jae Crowder|25.0|6796117.0|
+-------------+----+---------+
df2 = create_df(
data=[
('Avery Bradley', 24.0, 7730337.0),
('Jae Crowder', 25.0, 6796117.0),
],
schema = ['name', 'age', 'salary']
)
+-------------+----+---------+
| name| age| salary|
+-------------+----+---------+
|Avery Bradley|24.0|7730337.0| <<< 24
| Jae Crowder|25.0|6796117.0|
+-------------+----+---------+
# Solution #1
df1.subtract(df2).show()
+-------------+----+---------+
| name| age| salary|
+-------------+----+---------+
|Avery Bradley|25.0|7730337.0|
+-------------+----+---------+
# Solution #2
df1.join(df2, on=df1.columns).count()
# 1 <<< while df1.count() = 2
-
问题内容: 如何比较javascript中的2个函数?我不是在谈论内部参考。说 可以比较和吗? 问题答案:
-
我在DataBricks工作,在那里我有一个数据帧。 我唯一想要的就是将这个完整的spark数据帧写入Azure Blob存储。 我找到了这个帖子。所以我尝试了这个代码: 运行该代码会导致以下错误。更改拼花和其他格式的“csv”部分也失败了。 因此,我的问题(这应该很容易是我的假设):如何将我的火花数据帧从DataBricks写入Azure Blob存储? 我的Azure文件夹结构如下所示: 非常
-
问题内容: 例如,我有要比较的功能列表: http://play.golang.org/p/_rCys6rynf 如果两个函数相同,比较的正确方法是什么? 问题答案: 在继续之前:您应该重构而不是比较函数值地址。 规格:比较运算符: 切片,贴图和函数值不可比较。但是,在特殊情况下,可以将切片,映射或函数值与预先声明的标识符进行比较。 函数值不可比。如果功能值的地址相同(不是保存功能值的变量的地址,
-
问题内容: 我需要比较2个不同数据库中的数据库表,以了解差异所在,是否有一个简单的工具或脚本来实现? 问题答案: redgate SQL数据比较
-
问题内容: 我有两张桌子。一个(下面的df)大约有18,000行,另一个(下面的映射文件)大约有80万行。我需要一个可以与如此大的DataFrames一起使用的解决方案。 这是一个玩具示例:表1-df 表2-映射文件 我正在尝试执行以下操作(我的语法是错误的,但是我认为这个想法会出现): 换句话说:我需要遍历mapfile中的每个项目(行),看看它的位置是否在df中每个CHR的任何START和EN
-
在db中,我有一个字段名类型 字段的值如下 但没有返回结果。 问题是什么,如何修复?