
多项目sbt-组装问题

我正在尝试创建一个包含两个主要类的项目——SparkConsumer和KafkaProducer。为此,我在sbt文件中引入了多项目结构。消费者和生产者模块用于单独的项目,核心项目包含生产者和消费者都使用的UTIL。Root是主要项目。还介绍了常见设置和库依赖项。然而,由于某种原因,该项目没有编译。所有sbt组件相关设置均标记为红色。然而,插件。具有已定义sbt程序集插件的sbt位于根项目中。
这种问题的解决方案是什么?
项目结构如下所示:
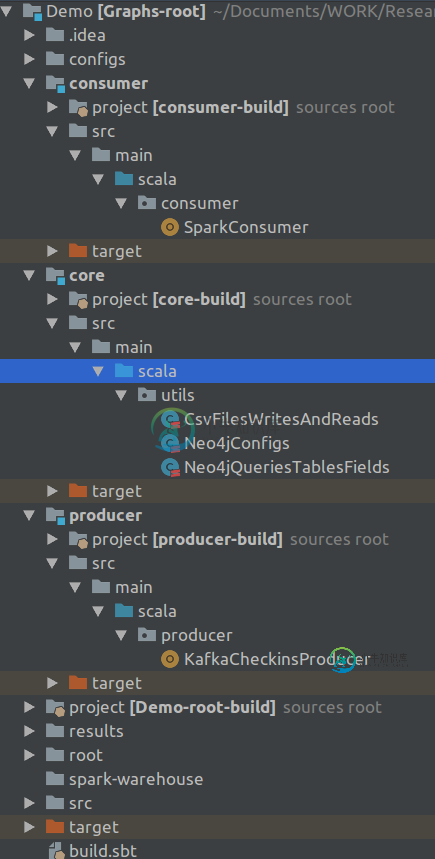
这是构建。sbt文件:
lazy val overrides = Seq("com.fasterxml.jackson.core" % "jackson-core" % "2.9.5",
"com.fasterxml.jackson.core" % "jackson-databind" % "2.9.5",
"com.fasterxml.jackson.module" % "jackson-module-scala_2.11" % "2.9.5")
lazy val commonSettings = Seq(
name := "Demo",
version := "0.1",
scalaVersion := "2.11.8",
resolvers += "Spark Packages Repo" at "http://dl.bintray.com/spark-packages/maven",
dependencyOverrides += overrides
)
lazy val assemblySettings = Seq(
assemblyMergeStrategy in assembly := {
case PathList("org","aopalliance", xs @ _*) => MergeStrategy.last
case PathList("javax", "inject", xs @ _*) => MergeStrategy.last
case PathList("javax", "servlet", xs @ _*) => MergeStrategy.last
case PathList("javax", "activation", xs @ _*) => MergeStrategy.last
case PathList("org", "apache", xs @ _*) => MergeStrategy.last
case PathList("com", "google", xs @ _*) => MergeStrategy.last
case PathList("com", "esotericsoftware", xs @ _*) => MergeStrategy.last
case PathList("com", "codahale", xs @ _*) => MergeStrategy.last
case PathList("com", "yammer", xs @ _*) => MergeStrategy.last
case PathList("org", "slf4j", xs @ _*) => MergeStrategy.last
case PathList("org", "neo4j", xs @ _*) => MergeStrategy.last
case PathList("com", "typesafe", xs @ _*) => MergeStrategy.last
case PathList("net", "jpountz", xs @ _*) => MergeStrategy.last
case PathList("META-INF", xs @ _*) => MergeStrategy.discard
case "about.html" => MergeStrategy.rename
case "META-INF/ECLIPSEF.RSA" => MergeStrategy.last
case "META-INF/mailcap" => MergeStrategy.last
case "META-INF/mimetypes.default" => MergeStrategy.last
case "plugin.properties" => MergeStrategy.last
case "log4j.properties" => MergeStrategy.last
case x =>
val oldStrategy = (assemblyMergeStrategy in assembly).value
oldStrategy(x)
}
)
val sparkVersion = "2.2.0"
lazy val commonDependencies = Seq(
"org.apache.kafka" %% "kafka" % "1.1.0",
"org.apache.spark" %% "spark-core" % sparkVersion % "provided",
"org.apache.spark" %% "spark-sql" % sparkVersion,
"org.apache.spark" %% "spark-streaming" % sparkVersion,
"org.apache.spark" %% "spark-streaming-kafka-0-10" % sparkVersion,
"neo4j-contrib" % "neo4j-spark-connector" % "2.1.0-M4",
"com.typesafe" % "config" % "1.3.0",
"org.neo4j.driver" % "neo4j-java-driver" % "1.5.1",
"com.opencsv" % "opencsv" % "4.1",
"com.databricks" %% "spark-csv" % "1.5.0",
"com.github.tototoshi" %% "scala-csv" % "1.3.5",
"org.elasticsearch" %% "elasticsearch-spark-20" % "6.2.4"
)
lazy val root = (project in file("."))
.settings(
commonSettings,
assemblySettings,
libraryDependencies ++= commonDependencies,
assemblyJarName in assembly := "demo_root.jar"
)
.aggregate(core, consumer, producer)
lazy val core = project
.settings(
commonSettings,
assemblySettings,
libraryDependencies ++= commonDependencies
)
lazy val consumer = project
.settings(
commonSettings,
assemblySettings,
libraryDependencies ++= commonDependencies,
mainClass in assembly := Some("consumer.SparkConsumer"),
assemblyJarName in assembly := "demo_consumer.jar"
)
.dependsOn(core)
lazy val producer = project
.settings(
commonSettings,
assemblySettings,
libraryDependencies ++= commonDependencies,
mainClass in assembly := Some("producer.KafkaCheckinsProducer"),
assemblyJarName in assembly := "demo_producer.jar"
)
.dependsOn(core)
更新:堆栈跟踪
(producer / update) java.lang.IllegalArgumentException: a module is not authorized to depend on itself: demo#demo_2.11;0.1
[error] (consumer / update) java.lang.IllegalArgumentException: a module is not authorized to depend on itself: demo#demo_2.11;0.1
[error] (core / Compile / compileIncremental) Compilation failed
[error] (update) sbt.librarymanagement.ResolveException: unresolved dependency: org.apache.spark#spark-sql_2.12;2.2.0: not found
[error] unresolved dependency: org.apache.spark#spark-streaming_2.12;2.2.0: not found
[error] unresolved dependency: org.apache.spark#spark-streaming-kafka-0-10_2.12;2.2.0: not found
[error] unresolved dependency: com.databricks#spark-csv_2.12;1.5.0: not found
[error] unresolved dependency: org.elasticsearch#elasticsearch-spark-20_2.12;6.2.4: not found
[error] unresolved dependency: org.apache.spark#spark-core_2.12;2.2.0: not found
共有1个答案

未解决的依存关系:组织。阿帕奇。spark#spark-sql_2.12;2.2.0
Spark 2.2.0需要Scala 2.11,请参阅https://spark.apache.org/docs/2.2.0/由于某种原因,未应用您的通用设置中的scalaVersion。您可能需要设置全局scalaVersion才能解决这个问题。
Spark在Java 8、Python 2.7/3.4和R 3.1上运行。对于Scala API,Spark 2.2.0使用Scala 2.11。您需要使用兼容的Scala版本(2.11.x)。
此外,Sock-sql和Sock-流也应标记为“提供”
-
sbt子项目是否可以有自己的目录?或者只有根项目可以用。Scala帮助器文件为构建项目的目录?。下面是我目前的建筑结构。无法访问中定义的对象。 更新:sub-project-1/build.sbt中的以下sbt定义 由于以下错误而失败 Common在/my-project/projects/Common.scala中定义,没有问题。但是Localhost是在/my-project/sub-proj
-
我正在使用sbt 0.13.12,这是我的项目 在构建中。sbt取决于公共。如果我按sbt project sub1 run运行就可以了。但是,当我将子项目打包为jar文件时,我运行sub1。jar文件中,错误显示sub1无法找到一类公共的。 我的目的是包装sub1。jar和sub2。在每个jar文件中编译带有通用代码的jar。 --更新-- 我尝试作为建议回答。运行时遇到这个问题: 而且,是的!
-
但是,在编译ApplicationA时,SBT抱怨依赖项只能是子目录!!: 这看起来很简单,拥有这个项目依赖项的正确方法是什么?
-
这次我的头撞到墙上了。 正在尝试在工作中打开克隆的git SBT项目。它是一个结合了Java和Scala的Play项目,使用Scala 2.11。1,SBT 0.13。6,玩2.5。 我使用IntelliJ从克隆的回购中导入项目,使用JDK 1.8,检查所有下载和SBT复选框,然后运行SBT刷新或从SBT shell重新加载。 完成此操作后,所有SBT和Play代码都将在两个版本上生成。sbt和插
-
我在理解scalapb的语法时遇到了一些困难,特别是我正在尝试添加多个。多项目SBT构建的原型源目录。 我的项目结构如下: 我的身材。sbt如下: 当我运行sbt编译时,我得到以下错误消息: 有人能给我指出正确的方向吗?我不明白这里的一些基本概念... 编辑 好的,我指向了错误的原始目录序列。我已经修改了版本。sbt以反映新的变化。我仍然有一个问题,我的。子项目中未编译原型文件。如果我移动我的。p