
使用ANTLR4对语法中的lexer规则进行排序

我正在使用ANTLR4生成一个解析器。我是语法分析器的新手。我读过非常有帮助的ANTLR Megahtml" target="_blank">教程,但我仍然停留在如何正确排序(和/或编写)我的lexer和解析器规则上。
我希望解析器能够处理以下内容:
你好<
下面是我的语法:
doc: item* EOF ;
item: (func | WORD) PUNCT? ;
func: '<<' ID '>>' ;
WS : [ \t\n\r] -> skip ;
fragment LETTER : [a-zA-Z] ;
fragment DIGIT : [0-9] ;
fragment CHAR : (LETTER | DIGIT | SYMB ) ;
WORD : CHAR+ ;
ID: LETTER ( LETTER | DIGIT)* ;
PUNCT : [.,?!] ;
fragment SYMB : ~[a-zA-Z0-9.,?! |{}<>] ;
旁注:我加了“punct?”在“item”规则的末尾,因为有可能在“func”后面出现一个逗号,例如在我上面给出的例句中。但由于“word”后面也可以有逗号,所以我决定把标点符号放在“item”中,而不是放在“func”和“word”中。
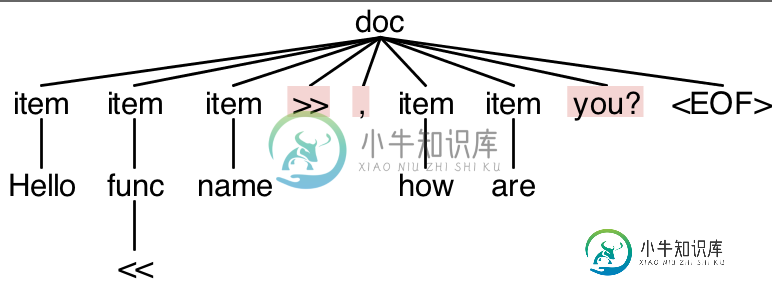
任何以红色突出显示的内容都是解析错误。
ID: LETTER ( LETTER | DIGIT)* ;
WORD : CHAR+ ;

我想一个选择可能是将“func”规则更改为“<
谢谢你的帮助!
共有1个答案

来自最终的ANTLR 4参考:
ANTLR通过将输入字符串与语法中首先指定的规则匹配来解决词法上的歧义。
使用您的语法(问题是.g4)和一个t.text文件,该文件包含
Hello << name >>, how are you at nine o'clock?
执行
$ grun Question doc -tokens -diagnostics t.text
给出
[@0,0:4='Hello',<WORD>,1:0]
[@1,6:7='<<',<'<<'>,1:6]
[@2,9:12='name',<WORD>,1:9]
[@3,14:15='>>',<'>>'>,1:14]
[@4,16:16=',',<PUNCT>,1:16]
[@5,18:20='how',<WORD>,1:18]
[@6,22:24='are',<WORD>,1:22]
[@7,26:28='you',<WORD>,1:26]
[@8,30:31='at',<WORD>,1:30]
[@9,33:36='nine',<WORD>,1:33]
[@10,38:44='o'clock',<WORD>,1:38]
[@11,45:45='?',<PUNCT>,1:45]
[@12,47:46='<EOF>',<EOF>,2:0]
line 1:9 mismatched input 'name' expecting ID
line 1:14 extraneous input '>>' expecting {<EOF>, '<<', WORD, PUNCT}
现在将项目规则中的字更改为字,并添加字规则:
item: (func | word) PUNCT? ;
word: WORD | ID ;
并将ID放在WORD之前:
ID: LETTER ( LETTER | DIGIT)* ;
WORD : CHAR+ ;
代币现在是
[@0,0:4='Hello',<ID>,1:0]
[@1,6:7='<<',<'<<'>,1:6]
[@2,9:12='name',<ID>,1:9]
[@3,14:15='>>',<'>>'>,1:14]
[@4,16:16=',',<PUNCT>,1:16]
[@5,18:20='how',<ID>,1:18]
[@6,22:24='are',<ID>,1:22]
[@7,26:28='you',<ID>,1:26]
[@8,30:31='at',<ID>,1:30]
[@9,33:36='nine',<ID>,1:33]
[@10,38:44='o'clock',<WORD>,1:38]
[@11,45:45='?',<PUNCT>,1:45]
[@12,47:46='<EOF>',<EOF>,2:0]
再也没有错误了。如-gui图形所示,您现在有了标识为word或func的分支。
-
可能在内部使用的代码将在规则之后被取消,如下所示: ANTLR4就是这样做事的吗?
-
我正在使用antlr4 c语法作为我自己语法的灵感。我来了一件事,我真的不明白。为什么没有使用数据类型时会有Lexer规则?例如,规则从未使用过,但分析器规则(为了简化已删除其他数据类型)使用了好几个地方。解析器规则typeSpecifier没有使用lexer规则double有什么原因吗?
-
我刚刚开始学习ANTLR4 lexer规则。我的目标是为Java属性文件创建一个简单的语法。以下是我目前掌握的信息:
-
null null 以下是我的(不完整和不成功的)尝试: 如果不能在lexer中解决这个问题,我可以使用标记、、、、、和自行编写解析器规则。
-
我的语法允许以下操作: 我从其他语法中抓了几个东西来玩。我的主要问题是我的expr规则。给定以下输入:,我期望解析树会找到..规则,但它将解释0。并不正确解析其余部分。 如果在我的0后面加上一个空格,就可以了: 谢了!
-
在使用ANTLR3.5语法进行Java语法分析时,注意到“标识符”规则在Antlr Lexer语法中消耗了很少的关键字。Lexer语法是 当我试图解析行时: 在Antlr语法中是否有任何技巧/规定来匹配关键字本身的规则,而不影响其他功能,如“标识符”?