
如何使用Selenium Web驱动程序获取图像元素的工具提示消息?

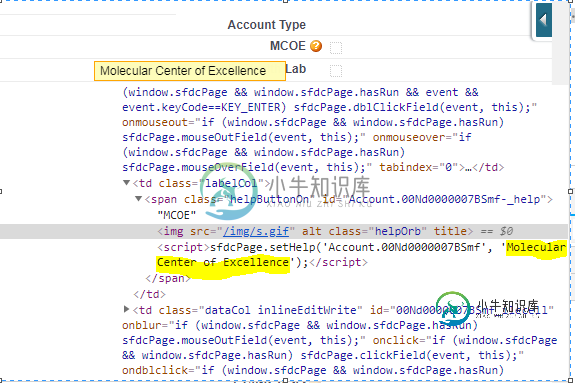
首先,我不能使用。getAttribute(“标题”),因为标题属性中没有文本;其次当我将XPath赋给图像并应用时,getText()不起作用。getText()。
谁能帮我一下吗?
共有2个答案

谢谢!!!下面的这个东西对我有用;该消息是在隐藏的脚本标签属性“文本内容”或“innerHTML”中找到的。这是代码:
public void helpTextAssert(WebElement pathOfToolTip,String enterFieldName,String enterExpectedHelpText){String originalActualText=pathOfToolTip.getAttribute(“textContent”);//使用了下面的布尔变量,因为我在文本内容属性boolean containsTextFlag=pathOfToolTip.getAttribute(“textContent”)。包含(enterExpectedHelpText);如果(originalActualText!=空

你能告诉我为什么吗。getText()不工作?或者,您可以这样做:1。提取HTML代码2。将其另存为字符串3。拆分字符串以提取所需文本
查看如何在Selenium中获取WebElement的超文本标记语言代码
或
//moving to element which triggers this tooltip
Actions action= new Actions(driver);
action.moveToElement(driver.findElement(By.xpath("//td[@class='labelcol']/span[@class='helpButtonOn']"))).build().perform();
//insert wait here
String hovertext=driver.findElement(By.xpath("//td[@class='labelcol']/span[@class='helpButtonOn']/script")).getText();
System.out.println(hovertext);
或
// javascript executor
WebElement element = driver.findElement(By.xpath("//td[@class='labelcol']/span[@class='helpButtonOn']/script"));
String hovertext = (String)((JavascriptExecutor)driver).executeScript("return arguments[0].innerHTML", element);
System.out.println(hovertext);
-
我试图从网站中的元素中提取文本。HTML代码如下所示: 下面是我的代码:
-
这个元素有子元素,这些子元素又有子元素,依此类推。我想获取所有元素,这些元素都是元素的后代。谢谢
-
问题内容: 我试图单击此页面上的元素: 在这一点上,我想单击“现金流量”,“资产负债表”或“季度”。我知道这些按钮已加载,因为我可以使用BeautifulSoup从页面源中提取它们。但是,当我尝试使用Selenium时: 全部返回“无法定位元素”,除了“季度”返回一个元素,但它位于图上方的一个元素而不是我感兴趣的表格上方的一个元素。 我认为这是由于位于错误的iframe中,而我找到了所有ifram
-
我对使用Python的Selenium是新手。我正在尝试获取一些数据,但我不知道如何解析来自以下命令的输出: 我试图在谷歌上搜索一些教程,但我没有找到Python的任何内容。 你能给我个提示吗?
-
我正在使用,我有两个单选按钮(男性和女性),两个单选按钮都有共同的名称定位符,,另外男性单选按钮='m'和女性单选按钮的'value'是'f'。我需要根据用户输入选择这些单选按钮中的任何一个。如何获取下面“性别”元素的子元素?
-
我正在寻找提取表中的数据,我已经找到做以下工作: 从我得到的球员 现在我想检索表中的数据。我该怎么做? 编辑:我应该说,当我这样做的时候 我得到