
为什么IntelliJ在某些情况下不会调试错误。随附示例

我正在测试一些东西,遇到了一个奇怪的情况,当我有一个断点时,IntelliJ没有调试我的代码,如图1所示。但是当我移动断点时,工作正常。
代码:
public class Walrus {
public int weight;
public double tuskSize;
public Walrus(int weight, int x){
this.weight = weight;
this.tuskSize = tuskSize;
}
public static void main(String[] args) {
// Random declared ints.
int x;
double y;
// Declared a Walrus
Walrus someWalrus;
// Set to null
someWalrus = null;
// Initialize a new Walrus.
Walrus a = new Walrus(10,3);
System.out.println();
}
}
当我在这里有我的调试点时(见图),这不起作用并给出以下错误:
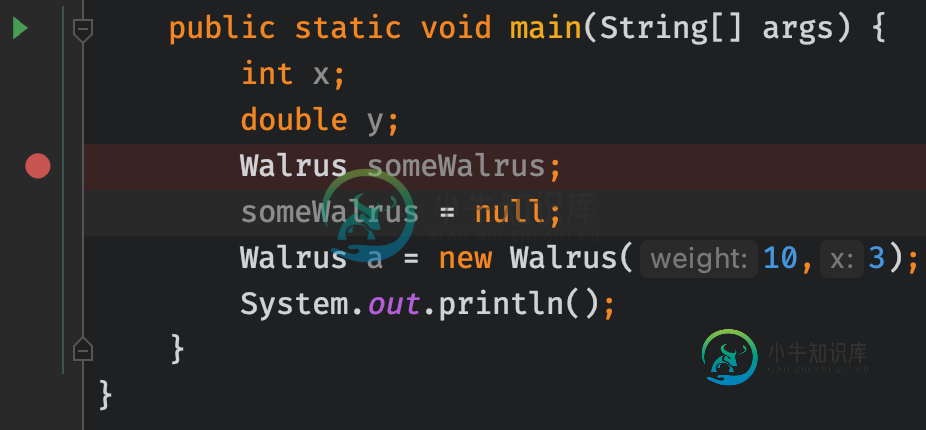
错误:
连接到目标虚拟机,地址:“127.0.0.1:59776”,传输:“socket”OpenJDK 64位服务器虚拟机警告:共享仅支持引导加载程序类,因为已附加引导类路径,与目标虚拟机断开连接,地址:“127.0.0.1:59776”,传输:“socket”进程已完成,退出代码为0
现在,如果我这样做(见第二张图),它运行良好:
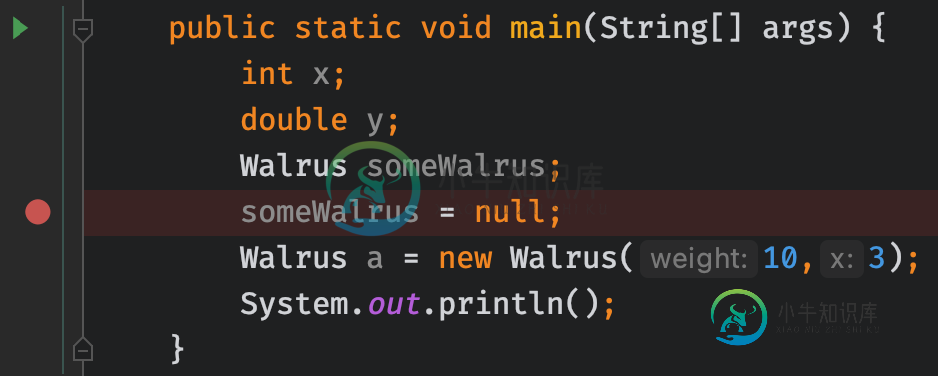
我想可能它认为没有什么需要调试的,因为我没有分配任何变量。但这只是一个猜测。谁能解释一下引擎盖下面发生了什么?谢谢
暂时还没有答案
-
问题内容: 为什么 工作,但是 不是吗 问题答案: 为了理解这一点,让我们考虑一下编译器在两种可能性下每个步骤所做的事情。让我们开始: 编译器将‘4’转换为int。所以变成 然后编译器变成 ch是一个字符,编译器可以将54转换为字符,因为它可以证明转换没有损失。 现在让我们考虑第二个版本: ch在编译时没有已知值。因此,这成为 现在,编译器无法证明此(int)的结果在char范围内可存储。因此它
-
问题内容: 我最近注意到,有一些Java库(JDK,joda time,iText)在编译时没有部分/全部调试信息。要么缺少局部变量信息,要么缺少局部变量信息和行号。 有什么理由吗?我意识到这会使编译后的代码更大,但我认为这不是一个特别大的考虑因素。还是仅使用默认的编译选项进行构建? 谢谢。 问题答案: 默认的编译选项不包含调试信息,您必须明确告诉编译器包括调试信息。大多数人忽略它的原因有几个:
-
本文向大家介绍datanode在什么情况下不会备份相关面试题,主要包含被问及datanode在什么情况下不会备份时的应答技巧和注意事项,需要的朋友参考一下 解答: 当分备份数为1时。
-
我们最近在系统中遇到了一个性能问题,Logback调用了toString(),尽管指定的日志级别(DEBUG)没有为该特定的日志记录程序启用。当然,现在还有一个额外的问题是我们的toString()方法非常占用CPU,但logback的行为非常出乎意料。给定以下简单的测试案例,日志级别为mypkg。LogTest2未指定(默认),我看到toString()调用了两次,但没有打印日志消息(注意:针对
-
问题内容: 今天,在浏览各种问题时,我遇到了一个问题,在我看来有点不可思议,为什么一个人要在上面加上a ,对于这种情况会不会有什么真正的原因,所以这只是微不足道的吗? 问题答案: 动画图像作为GUI的BG。我使用HTML来调整此尺寸(x3),但是如果它已经是所需的尺寸,则可以直接将其设置为标签的。 不知道它是否是“真正的”。这似乎是一个主观术语,需要更多说明。我从来没有使用过这种方法,只是想通了,
-
我目前正在承担一个项目,我正在使用Java微基准线束(JMH)框架测量Java中不同类型循环的速度。我得到了一些关于流的有趣结果,我无法解释,并且想知道是否更了解流和数组列表的人可以帮助我解释我的结果。 基本上,当遍历大小为100的数组列表时,stream.forEach方法比任何其他类型的循环都快得多: 我的结果图表显示在这里:https://i.imgur.com/ypXoWWq.png 我尝