
用python[复制]将多年列转换为单年列(整齐格式)

我的数据集的形式为:

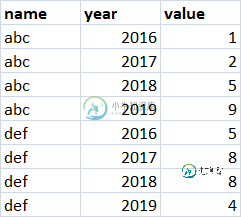
我想把它转换成:
如何使用pandas在Python中实现它?
它解决了感谢和感谢您的时间来帮助!!!1对所有
共有3个答案

您可以使用pandas.melt而不指定value\u vars
如果未指定,则使用未设置为id_变量的所有列。
df.melt(id_vars='name', var_name='year').sort_values('name')
name year value
0 abc 2016 1
2 abc 2017 2
4 abc 2018 5
6 abc 2019 9
1 def 2016 5
3 def 2017 8
5 def 2018 8
7 def 2019 4

你可以用
a = df.columns[1:]
df.melt(id_vars='name',value_vars = a,var_name='year').sort_values('name')

试试这个:
pd.melt(df, id_vars=['name'], value_vars=['2016', '2017', '2018',"2019"],var_name='year', value_name='value').sort_values('name')
输出:
+----+-------+-------+-------+
| | name | year | value |
+----+-------+-------+-------+
| 0 | abc | 2016 | 1 |
| 2 | abc | 2017 | 2 |
| 4 | abc | 2018 | 5 |
| 6 | abc | 2019 | 9 |
| 1 | def | 2016 | 5 |
| 3 | def | 2017 | 8 |
| 5 | def | 2018 | 8 |
| 7 | def | 2019 | 4 |
+----+-------+-------+-------+
-
问题内容: 我正在使用模块,即: 我想计算考虑takes年的一年中的某天。例如今天(2009年3月6日)是2009年的第65天。 我看到两个选择: 创建一个数组,确定是否是a年,然后手动汇总天数。 用于猜测,然后二进制搜索一年中的正确日期: YEAR = 2009 DAY_OF_YEAR = 62 d = datetime.date(YEAR, 1, 1) + datetime.timedelta
-
问题内容: 我表中的日期存储为十进制年份。一个示例翻译为。 我想将十进制年份转换为Oracle的日期格式。 我找到了在Excel中完成此操作的人:十进制的年初至今公式? 但是,我不太清楚如何将逻辑转换为Oracle PL / SQL。 问题答案: 如果您假设小数部分是根据给 定年份中的天数 (即365或366,取决于是否是leap年)来计算的,则可以执行以下操作:
-
我有一个具有以下结构的数据帧: 我需要将单元格Group_Membership中的值转换为列,并得到一个如下所示的数据框: 我设法将列Group_成员资格中的值转换为列表,然后将其“分解”,但随后我应该以某种方式将其转置 不知怎的,我现在应该把它转过来了。而且,我不确定这是最好的方法。。。 非常感谢您的帮助!
-
我有一个这样的表,这个表中的所有用户只有两个特性 我想转换为
-
我有一个日值(1-31)、一个月值(1-12)和一个年值,我需要将它们保存为我的MySQL数据库日期格式。 如何将这些值(对应于日、月和年的3个整数)转换为日期格式以将其保存到数据库中?
-
我有一个excel文件,看起来像这样: Header3包含如下所示的JSON字符串 我想解析JSON Header3列,并为每个键创建一个列,其中键的名称附加有键2的值,整个文件中的键始终相同。 结束数据帧应如下所示: 实例: 需要成为: 在进入花哨的东西之前,我试图至少规范化数据,但我得到了一个空序列。