
Apache Spark+Delta Lake概念

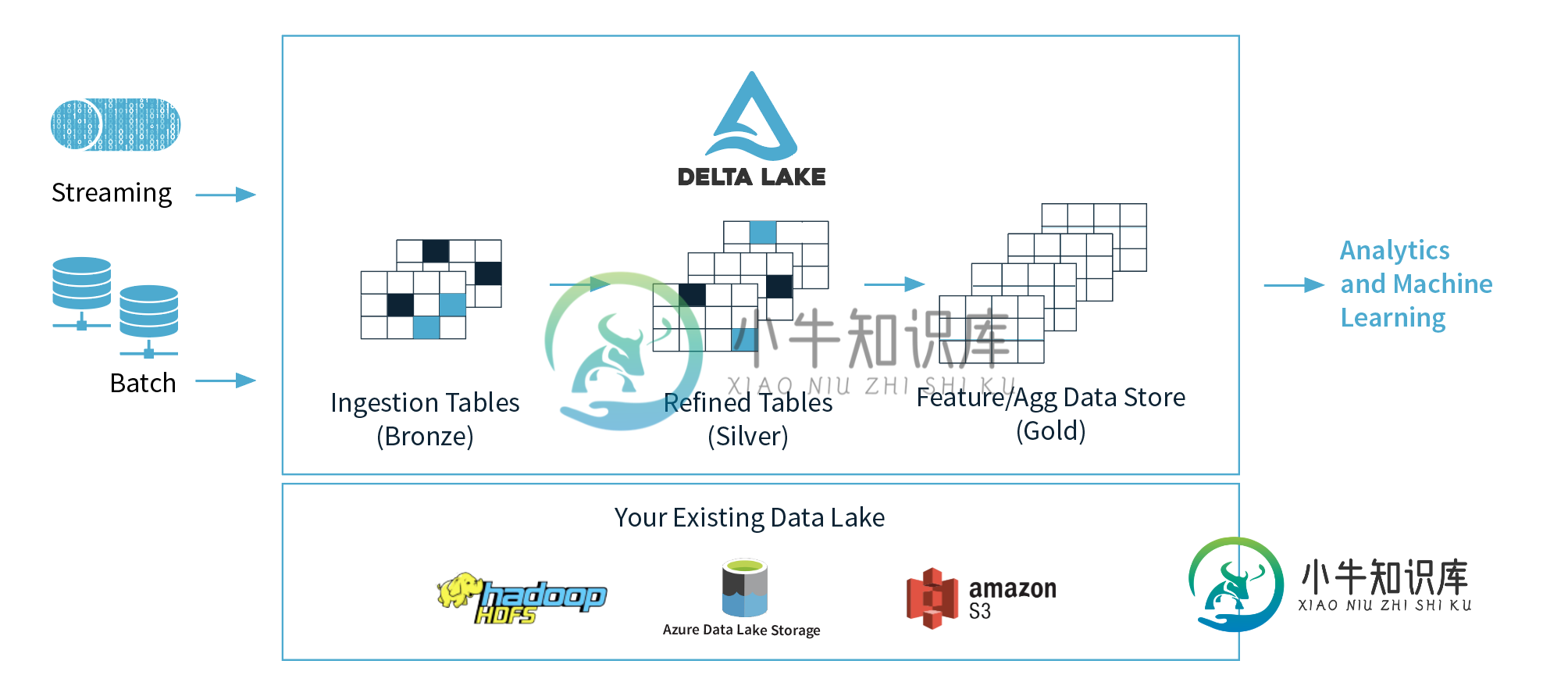
1)数据库建议使用三层(铜层、银层、金层),但推荐使用哪一层来进行机器学习?为什么?我想他们建议在金层中使用干净的数据。
2)如果我们把这三层的概念抽象出来,我们能不能把青铜层看成数据湖,银层看成数据库,金层看成数据仓库?我的意思是从功能上讲,。
3)Delta架构是一个商业术语,还是Kappa架构的演变,还是Lambda和Kappa架构的新趋势?Delta+Lambda架构与Kappa架构有何区别?
5)我曾经使用Kafka、Kinesis或Event Hub进行流式处理,我的问题是,如果我们用Delta Lake表代替这些工具,会发生什么样的问题(我已经知道一切都取决于许多事情,但我想对此有一个大致的看法)。
共有1个答案

1)把它留给你的数据科学家。他们应该在silver和gold区域工作,一些更高级的数据科学家会想要回到原始数据,并分析出可能没有包含在silver/gold表中的额外信息。
2)青铜=原生格式/delta lake格式的原始数据。银色=delta lake中经过净化和清理的数据。Gold=根据业务需求通过delta lake访问或推送到数据仓库的数据。
3)Delta体系结构是lambda体系结构的一个简单版本。Delta体系结构是一个商业术语,我们将观察它在未来是否会发生变化。
-
我有一个基于maven的scala/java混合应用程序,可以提交spar作业。我的应用程序jar“myapp.jar”在lib文件夹中有一些嵌套的jar。其中之一是“common.jar”。我在清单文件中定义了类路径属性,比如。Spark executor抛出在客户端模式下提交应用程序时出错。类(com/myapp/common/myclass.Class)和jar(common.jar)在那里
-
给定一个包含以下格式数据的大文件(V1,V2,…,VN) 我正在尝试使用Spark获得一个类似于下面的配对列表 我尝试了针对一个较旧的问题所提到的建议,但我遇到了一些问题。例如, 我得到了错误, 有人能告诉我哪些地方我可能做得不对,或者有什么更好的方法可以达到同样的效果?非常感谢。
-
我有一个项目的RDD,还有一个函数 。 收集RDD的两个小样本,然后这两个数组。这很好,但无法扩展。 有什么想法吗? 谢谢 编辑:下面是如何压缩每个分区中具有不同项数的两个示例: 关键是,虽然RDD的. zip方法不接受大小不等的分区,但迭代器的. zip方法接受(并丢弃较长迭代器的剩余部分)。
-
我正在ApacheSpark上的数据库中构建一个族谱,使用递归搜索来查找数据库中每个人的最终父级(即族谱顶部的人)。 假设搜索id时返回的第一个人是正确的家长 它给出以下错误 “原因:org.apache.spark.SparkException:RDD转换和操作只能由驱动程序调用,不能在其他转换中调用;例如,
-
我正在构建一个Spark应用程序,我必须在其中缓存大约15GB的CSV文件。我在这里读到了Spark 1.6中引入的新: https://0x0fff.com/spark-memory-management/ 作者在和之间有所不同(火花内存又分为)。正如我所了解的,Spark内存对于执行(洗牌、排序等)和存储(缓存)东西是灵活的——如果一个需要更多内存,它可以从另一个部分使用它(如果尚未完全使用)
-
我试图在火花笔记本的阿帕奇火花中做NLP。对于这个特定的例子,我正在使用库https://opennlp.apache.org创建一个块来提取名词短语。由于数据量的增加,我需要转向分布式计算。 问题是我无法广播我的chunker对象。通过阅读文档(只在board上投射数组等简单对象),我尝试了以下方法: 但这会引发以下错误: 如果我将chunker的初始化封装在函数中,然后在map方法中调用函数,
-
我正在用Kafka设计一个spark流媒体应用程序。我有以下几个问题:我正在将数据从RDBMS表流式传输到kafka,并使用Spark consumer来使用消息,并使用Spark-SQL进行处理 问题:1。我将数据从表中流式传输到kafka as(键作为表名,值作为JSON记录形式的表数据)——这是正确的体系结构吗? 这种数据库流的架构和设计是否正常,我如何解决转换问题中的转换? 你好Piyus
-
英文原文:http://emberjs.com/guides/concepts/core-concepts/ 要开始学习Ember.js,首先要了解一些核心概念。 Ember.js的设计目标是能帮助广大开发者构建能与本地应用相颦美的大型Web应用。要实现这个目标需要新的工具和新的概念。我们花了很大的功夫从Cocoa、Smalltalk等本地应用框架引入了其优秀的理念。 然而,记住Web的特殊性非常